10000 contenu connexe trouvé

Modèle de pré-formation Text-to-SQL multitâche en deux étapes MIGA basé sur T5
Présentation de l'article:De plus en plus de travaux ont prouvé que les modèles linguistiques pré-entraînés (PLM) contiennent des connaissances riches. Pour différentes tâches, l'utilisation de méthodes de formation appropriées pour tirer parti du PLM peut mieux améliorer les capacités du modèle. Dans les tâches Text-to-SQL, les générateurs traditionnels actuels sont basés sur des arbres syntaxiques et doivent être conçus pour la syntaxe SQL. Récemment, NetEase Interactive Entertainment AI Lab s'est associé à l'Université des études étrangères du Guangdong et à l'Université de Columbia pour proposer un modèle de pré-formation multitâche en deux étapes MIGA basé sur la méthode de pré-formation du modèle de langage pré-entraîné T5. MIGA introduit trois tâches auxiliaires dans la phase de pré-formation et les organise dans un paradigme de tâches de génération unifiée, qui peut intégrer tous les ensembles de données Text-to-SQL
2023-04-13
commentaire 0
1306

Modèles pré-entraînés spécifiques pour le domaine de la PNL biomédicale : PubMedBERT
Présentation de l'article:Le développement rapide des grands modèles de langage cette année a conduit à ce que des modèles comme BERT soient désormais appelés « petits » modèles. Lors du concours d'examen scientifique LLM de Kaggle, les joueurs utilisant deberta ont obtenu la quatrième place, ce qui est un excellent résultat. Par conséquent, dans un domaine ou un besoin spécifique, un grand modèle de langage n’est pas nécessairement requis comme meilleure solution, et les petits modèles ont également leur place. Par conséquent, ce que nous allons présenter aujourd'hui est PubMedBERT, un article publié par Microsoft Research à l'ACM en 2022. Ce modèle pré-entraîne BERT à partir de zéro en utilisant des corpus spécifiques à un domaine. Voici les principaux points de l'article : Pour ceux-là. avec des domaines spécifiques comportant de grandes quantités de texte non étiqueté, tels que la biomédecine, pré-entraînés à partir de zéro
2023-11-27
commentaire 0
1235

Analyse technique ChatGPT PHP : Comment utiliser des modèles pré-entraînés pour créer des applications de chat intelligentes
Présentation de l'article:Analyse technique ChatGPTPHP : Comment utiliser des modèles pré-entraînés pour créer des applications de chat intelligentes À l'ère de l'information d'aujourd'hui, les applications de chat intelligentes sont devenues un élément indispensable de la vie quotidienne et des affaires. Les applications de chat intelligent peuvent aider les utilisateurs à communiquer en langage naturel et à fournir des réponses en temps réel aux questions et suggestions. Le projet ChatGPT récemment open source nous offre un moyen efficace de créer des applications de chat intelligentes. Cet article présentera en détail comment utiliser le langage de programmation PHP combiné à des modèles pré-entraînés pour créer des applications de chat intelligentes et fournir
2023-10-24
commentaire 0
1098


CMU s'associe à Adobe : le modèle GAN a inauguré l'ère de la pré-formation, ne nécessitant que 1 % des échantillons de formation
Présentation de l'article:Après être entrés dans l’ère de la pré-formation, les performances des modèles de reconnaissance visuelle se sont développées rapidement, mais les modèles de génération d’images, tels que les réseaux contradictoires génératifs (GAN), semblent avoir pris du retard. Habituellement, la formation GAN est effectuée à partir de zéro, de manière non supervisée, ce qui prend du temps et demande beaucoup de travail. Les « connaissances » acquises grâce au Big Data lors d'une pré-formation à grande échelle ne sont pas utilisées. De plus, la génération d'images elle-même doit être capable de capturer et de simuler des données statistiques complexes dans des phénomènes visuels du monde réel, sinon les images générées ne seront pas conformes aux lois du monde physique et seront directement identifiées comme « fausses » d'un seul coup d'œil. . Le modèle pré-entraîné fournit des connaissances et le modèle GAN fournit des capacités de génération. La combinaison des deux peut être une belle chose ! La question est de savoir quels modèles pré-entraînés et comment les combiner peuvent améliorer la capacité de génération du modèle GAN.
2023-05-11
commentaire 0
1467

Une autre révolution dans l'apprentissage par renforcement ! DeepMind propose une « distillation d'algorithmes » : un transformateur d'apprentissage par renforcement pré-entraîné explorable
Présentation de l'article:Transformer peut être considéré comme l'architecture de réseau neuronal la plus puissante pour les tâches de modélisation de séquence actuelles, et le modèle Transformer pré-entraîné peut utiliser des invites comme conditions ou un apprentissage en contexte pour s'adapter à différentes tâches en aval. La capacité de généralisation des modèles Transformer pré-entraînés à grande échelle a été vérifiée dans plusieurs domaines, tels que la complétion de texte, la compréhension du langage, la génération d'images, etc. Depuis l’année dernière, des travaux pertinents ont prouvé qu’en traitant l’apprentissage par renforcement hors ligne (RL hors ligne) comme un problème de prédiction de séquence, le modèle peut apprendre des politiques à partir de données hors ligne. Mais les approches actuelles soit apprennent les politiques à partir de données qui ne contiennent pas d'apprentissage
2023-04-12
commentaire 0
1848

Vous ne trouvez pas le modèle pré-entraîné pour la parole chinoise ? Les versions chinoises Wav2vec 2.0 et HuBERT arrivent
Présentation de l'article:Les modèles de pré-entraînement vocal tels que Wav2vec 2.0 [1], HuBERT [2] et WavLM [3] ont considérablement amélioré l'apprentissage automatique grâce à un apprentissage auto-supervisé sur des dizaines de milliers d'heures de données vocales non étiquetées (telles que Libri-light). Exécution de tâches vocales en aval telles que la reconnaissance automatique de la parole (ASR), la synthèse vocale (TTS) et la conversion vocale (VC). Cependant, ces modèles ne disposent pas de versions publiques chinoises, ce qui les rend difficiles à appliquer dans des scénarios de recherche sur la langue chinoise. WenetSpeech [4] Oui
2023-04-08
commentaire 0
1926

Mininglamp Technology lance TensorBoard.cpp open source gratuit pour faciliter la pré-formation des grands modèles
Présentation de l'article:Récemment, Mininglamp Technology Group a implémenté l'interface C++ de TensorBoard, un outil de visualisation d'apprentissage automatique, qui enrichit encore l'ensemble d'outils de projet de grands modèles basés sur C++, rendant la surveillance du processus de pré-formation de grands modèles plus pratique et efficace, et accélérant les grands modèles. modèle de pré-formation dans le domaine du marketing. L'outil est open source sur Github. TensorBoard est un outil de visualisation d'apprentissage automatique développé par Google et est souvent utilisé pour surveiller divers indicateurs du processus d'apprentissage automatique. Zhao Liang, directeur technique principal de Mininglamp Technology, a déclaré : « Dans le processus de formation de grands modèles, la surveillance des données est une dimension importante, et TensorBoard visualise divers paramètres et résultats dans le modèle, tels que l'enregistrement des changements de perte et des ensembles de validation au cours du grand. processus de formation modèle.
2023-08-14
commentaire 0
821

CVPR 2024 | Pré-formation spatio-temporelle en quatre dimensions du modèle mondial de conduite autonome
Présentation de l'article:L'Université de Pékin et l'équipe d'innovation d'EVLO ont proposé conjointement DriveWorld, un algorithme de pré-entraînement spatio-temporel à quatre dimensions pour la conduite autonome. Cette méthode utilise un modèle mondial pour la pré-formation, conçoit un modèle spatial d'état de mémoire pour une modélisation spatio-temporelle à quatre dimensions et réduit l'incertitude aléatoire et l'incertitude des connaissances auxquelles est confrontée la conduite autonome en prédisant la grille d'occupation de la scène. Cet article a été accepté par CVPR2024. Titre de l'article : DriveWorld : 4DPre-trainedSceneUnderstandingviaWorldModelsforAutonomousDriving Lien de l'article : https://arxiv.org/abs/2405.04390 1. Mouvement
2024-08-07
commentaire 0
841

Du BERT à ChatGPT, un examen complet de neuf instituts de recherche de premier plan, dont l'Université de Beihang : le « modèle de base de pré-formation » que nous avons poursuivi ensemble au fil des ans
Présentation de l'article:Les performances étonnantes de ChatGPT dans des scénarios avec peu de tirs et zéro tir ont rendu les chercheurs plus convaincus que la « pré-formation » est la bonne voie. Les modèles de base pré-entraînés (PretrainedFoundationModels, PFM) sont considérés comme la base de diverses tâches en aval sous différents modes de données, c'est-à-dire, basés sur des données à grande échelle, des modèles de base pré-entraînés tels que BERT, GPT-3, MAE, DALLE- E et ChatGPT sont formés, fournissant une initialisation raisonnable des paramètres pour les applications en aval. L'idée de pré-formation derrière PFM joue un rôle important dans l'application de grands modèles. Différent des méthodes précédentes d'extraction de fonctionnalités utilisant des modules de convolution et récursifs, le nouveau.
2023-04-15
commentaire 0
1458

Apple utilise des modèles de langage autorégressifs pour pré-entraîner les modèles d'image
Présentation de l'article:1. Contexte Après l'émergence de grands modèles tels que GPT, la méthode de modélisation autorégressive Transformer + du modèle de langage, qui est la tâche de pré-entraînement consistant à prédire le prochain jeton, a remporté un grand succès. Alors, cette méthode de modélisation autorégressive peut-elle obtenir de meilleurs résultats dans les modèles visuels ? L'article présenté aujourd'hui est un article récemment publié par Apple sur la formation d'un modèle visuel basé sur la pré-formation Transformer + autorégressive. Laissez-moi vous présenter ce travail. Titre de l'article : ScalablePre-trainingofLargeAutoregressiveImageModels Adresse de téléchargement : https://ar
2024-01-29
commentaire 0
1019

Comment effectuer une recherche d'images de manière efficace et précise ? Jetez un œil au modèle pré-entraîné à la vision légère
Présentation de l'article:Avez-vous déjà eu des problèmes avec la récupération d'images ? Soit il est difficile de trouver avec précision l’image recherchée parmi la quantité massive d’images, soit la recherche basée sur du texte n’est pas satisfaisante. Concernant ce problème, des chercheurs de Microsoft Research Asia et de la division Microsoft Cloud Computing et Intelligence artificielle ont mené des recherches approfondies sur les modèles visuels légers et ont proposé une série de méthodes de conception et de compression pour les modèles visuels de pré-entraînement afin de répondre aux exigences de déploiement visuel de Transformer Lightweight. . À l'heure actuelle, cette méthode et ce modèle ont été appliqués avec succès au moteur de recherche Bing de Microsoft, permettant un raisonnement et une récupération précis et rapides de dizaines de milliards d'images. Cet article fournira une explication approfondie du développement, des technologies clés, des applications et du potentiel des modèles légers de pré-entraînement visuel, ainsi que des opportunités et des défis futurs. J'espère que tout le monde pourra mieux comprendre.
2023-04-08
commentaire 0
1365

Explication détaillée du modèle de pré-formation d'apprentissage profond en Python
Présentation de l'article:Avec le développement de l'intelligence artificielle et de l'apprentissage profond, les modèles de pré-formation sont devenus une technologie populaire dans le traitement du langage naturel (NLP), la vision par ordinateur (CV), la reconnaissance vocale et d'autres domaines. En tant que l'un des langages de programmation les plus populaires à l'heure actuelle, Python joue naturellement un rôle important dans l'application de modèles pré-entraînés. Cet article se concentrera sur le modèle de pré-formation d'apprentissage profond en Python, y compris sa définition, ses types, ses applications et comment utiliser le modèle de pré-formation. Qu'est-ce qu'un modèle pré-entraîné ? La principale difficulté des modèles d’apprentissage profond est d’analyser un grand nombre de données de haute qualité.
2023-06-11
commentaire 0
2010

Formation personnalisée de modèles d'apprentissage profond à l'aide de techniques d'apprentissage par transfert
Présentation de l'article:Traducteur | Réviseur par Zhu Xianzhong | Sun Shujuan L'apprentissage par transfert est un type d'apprentissage automatique. Il s'agit d'une méthode appliquée aux réseaux neuronaux qui ont été formés ou pré-entraînés, et ces réseaux neuronaux pré-entraînés sont construits à l'aide de millions de données entraînées. points. L'utilisation la plus connue de cette technologie consiste actuellement à entraîner des réseaux de neurones profonds, car cette méthode a montré de bonnes performances dans la formation de réseaux de neurones profonds en utilisant moins de données. En fait, cette technique est également utile dans le domaine de la science des données, car la plupart des données du monde réel ne contiennent généralement pas des millions de points de données pour former un modèle d'apprentissage profond robuste. Il existe actuellement de nombreux modèles entraînés à l’aide de millions de points de données et pouvant être utilisés pour entraîner des réseaux neuronaux complexes d’apprentissage en profondeur avec une précision maximale.
2023-04-23
commentaire 0
1701


Guide de formation du modèle ChatGPT Python : étapes pour personnaliser un chatbot
Présentation de l'article:Guide de formation du modèle ChatGPTPython : Aperçu des étapes de personnalisation des robots de chat : Ces dernières années, avec le développement croissant de la technologie NLP (traitement du langage naturel), les robots de chat ont attiré de plus en plus d'attention. ChatGPT d'OpenAI est un puissant modèle de langage pré-entraîné qui peut être utilisé pour créer des chatbots multi-domaines. Cet article présentera les étapes d'utilisation de Python pour entraîner le modèle ChatGPT, y compris la préparation des données, la formation du modèle et la génération d'échantillons de dialogue. Étape 1 : Préparation, collecte et nettoyage des données
2023-10-24
commentaire 0
1334

Analyse multifonctionnelle de l'ARN, le modèle de langage ARN de l'équipe Baidu basé sur Transformer est publié dans la sous-journal Nature
Présentation de l'article:Les modèles linguistiques pré-entraînés de base de Radis se sont révélés très prometteurs dans l'analyse des séquences nucléotidiques, mais l'utilisation d'un seul ensemble de poids pré-entraînés pour obtenir des modèles multifonctionnels qui fonctionnent bien dans différentes tâches reste difficile. Les équipes du Baidu Big Data Lab (BDL) et de l'Université Jiao Tong de Shanghai ont développé RNAErnie, un modèle de pré-formation centré sur l'ARN basé sur l'architecture Transformer. Les chercheurs ont évalué le modèle sur sept ensembles de données et cinq tâches, démontrant la supériorité de RNAErnie dans l'apprentissage supervisé et non supervisé. RNAErnie a dépassé la ligne de base, améliorant la précision de la classification de 1,8 %, la précision de la prédiction des interactions de 2,2 % et le score F1 de la prédiction de la structure de 3,3 %.
2024-06-10
commentaire 0
599
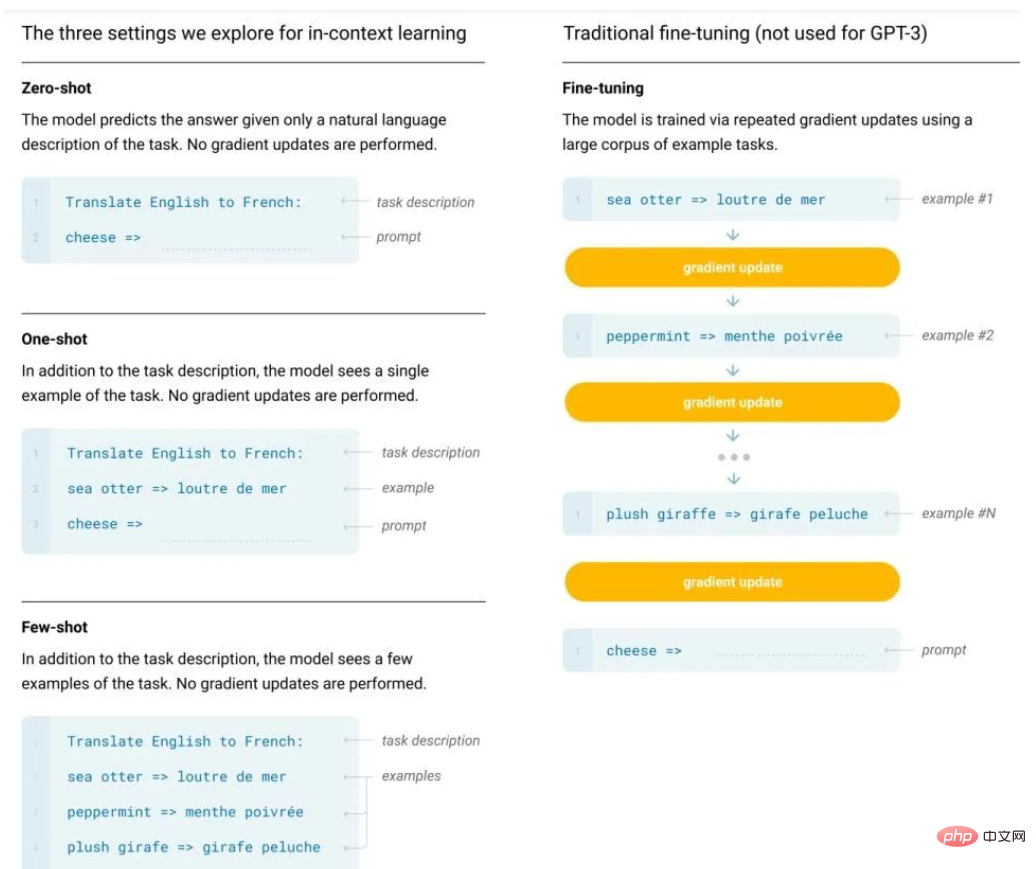
Pourquoi l'apprentissage en contexte, piloté par GPT, fonctionne-t-il ? Le modèle effectue une descente de pente en secret
Présentation de l'article:À la suite du BERT, les chercheurs ont remarqué le potentiel des modèles de pré-formation à grande échelle, et différentes tâches de pré-formation, architectures de modèles, stratégies de formation, etc. ont été proposées. Cependant, les modèles de type BERT présentent généralement deux défauts majeurs : l’un est une dépendance excessive à l’égard des données étiquetées ; l’autre est le phénomène de surajustement. Plus précisément, les modèles de langage actuels ont tendance à avoir un cadre en deux étapes, c'est-à-dire pré-formation + réglage fin des tâches en aval. Cependant, un grand nombre d'échantillons sont nécessaires pendant le processus de réglage fin pour les tâches en aval, sinon l'effet sera. être pauvre. Cependant, le coût de l'étiquetage des données est élevé. Les données étiquetées sont également limitées et le modèle ne peut s'adapter qu'à la distribution des données d'entraînement. Cependant, s'il y a moins de données, il est facile de provoquer un surajustement, ce qui réduira la capacité de généralisation du modèle. En tant que pionnier des grands modèles, des modèles de langage pré-entraînés à grande échelle, en particulier GPT-3
2023-04-25
commentaire 0
1546

L'Université de Pékin et Wangshi Intelligence proposent un nouveau modèle : combler le fossé entre le pré-entraînement aux réactions chimiques et la génération conditionnelle de molécules !
Présentation de l'article:Les réactions chimiques sont à la base de la conception de médicaments et de la recherche en chimie organique. Il existe un besoin croissant au sein de la communauté des chercheurs d’un cadre d’apprentissage profond à grande échelle capable de capturer efficacement les règles fondamentales des réactions chimiques. Récemment, une équipe de recherche de l’Université de Pékin et de Wangshi Intelligence a proposé une nouvelle méthode pour combler le fossé entre les tâches de pré-entraînement moléculaire basées sur les réactions et les tâches de génération. Inspirés par les mécanismes de la chimie organique, les chercheurs ont développé un nouveau cadre de pré-formation qui leur permet d'incorporer des biais inductifs dans les modèles. Ce cadre proposé permet d'obtenir des résultats de pointe lors de l'exécution de tâches difficiles en aval. En tirant parti des connaissances en chimie, le cadre surmonte les limites des modèles de génération moléculaire actuels qui reposent sur un petit nombre de modèles de réaction. Au cours d'expériences approfondies, le modèle a généré des structures synthétisables de haute qualité. Dans l'ensemble, le modèle a fonctionné.
2023-12-14
commentaire 0
620
