10000 contenu connexe trouvé

L'application d'apprentissage automatique de Golang pour l'apprentissage par renforcement
Présentation de l'article:Introduction à l'application d'apprentissage automatique de Golang dans l'apprentissage par renforcement L'apprentissage par renforcement est une méthode d'apprentissage automatique qui apprend un comportement optimal en interagissant avec l'environnement et en fonction des commentaires de récompense. Le langage Go possède des fonctionnalités telles que le parallélisme, la concurrence et la sécurité de la mémoire, ce qui lui confère un avantage dans l'apprentissage par renforcement. Cas pratique : Apprentissage par renforcement Go Dans ce tutoriel, nous utiliserons le langage Go et l'algorithme AlphaZero pour implémenter un modèle d'apprentissage par renforcement Go. Étape 1 : Installer les dépendances gogetgithub.com/tensorflow/tensorflow/tensorflow/gogogetgithub.com/golang/protobuf/ptypes/times
2024-05-08
commentaire 0
505

Problèmes de sélection d'algorithmes dans l'apprentissage par renforcement
Présentation de l'article:Le problème de la sélection d'algorithmes dans l'apprentissage par renforcement nécessite des exemples de code spécifiques. L'apprentissage par renforcement est un domaine de l'apprentissage automatique qui apprend des stratégies optimales grâce à l'interaction entre l'agent et l'environnement. Dans l’apprentissage par renforcement, le choix d’un algorithme approprié est crucial pour l’effet d’apprentissage. Dans cet article, nous explorons les problèmes de sélection d’algorithmes dans l’apprentissage par renforcement et fournissons des exemples de code concrets. Il existe de nombreux algorithmes parmi lesquels choisir en apprentissage par renforcement, tels que Q-Learning, DeepQNetwork (DQN), Actor-Critic, etc. Choisissez le bon algorithme
2023-10-08
commentaire 0
1190

Comment créer un algorithme d'apprentissage par renforcement en utilisant PHP
Présentation de l'article:Comment créer un algorithme d'apprentissage par renforcement à l'aide de PHP Introduction : L'apprentissage par renforcement est une méthode d'apprentissage automatique qui apprend à prendre des décisions optimales en interagissant avec l'environnement. Dans cet article, nous présenterons comment créer des algorithmes d'apprentissage par renforcement à l'aide du langage de programmation PHP et fournirons des exemples de code pour aider les lecteurs à mieux comprendre. 1. Qu'est-ce qu'un algorithme d'apprentissage par renforcement ? L'algorithme d'apprentissage par renforcement est une méthode d'apprentissage automatique qui apprend à prendre des décisions en observant les commentaires de l'environnement. Contrairement à d’autres algorithmes d’apprentissage automatique, les algorithmes d’apprentissage par renforcement ne sont pas uniquement basés sur des données existantes.
2023-07-31
commentaire 0
701

Problèmes de conception de récompense dans l'apprentissage par renforcement
Présentation de l'article:Le problème de la conception des récompenses dans l'apprentissage par renforcement nécessite des exemples de code spécifiques. L'apprentissage par renforcement est une méthode d'apprentissage automatique dont l'objectif est d'apprendre à prendre des mesures qui maximisent les récompenses cumulatives grâce à l'interaction avec l'environnement. Dans l’apprentissage par renforcement, la récompense joue un rôle crucial. Elle constitue un signal dans le processus d’apprentissage de l’agent et sert à guider son comportement. Cependant, la conception des récompenses est un problème difficile, et une conception raisonnable des récompenses peut grandement affecter les performances des algorithmes d’apprentissage par renforcement. Dans l’apprentissage par renforcement, les récompenses peuvent être considérées comme l’agent contre l’environnement.
2023-10-08
commentaire 0
1437

Technologie d'apprentissage par renforcement profond en C++
Présentation de l'article:La technologie d'apprentissage par renforcement profond est une branche de l'intelligence artificielle qui a beaucoup retenu l'attention. Elle a remporté de nombreux concours internationaux et est également largement utilisée dans les assistants personnels, la conduite autonome, l'intelligence des jeux et d'autres domaines. Dans le processus de réalisation d’un apprentissage par renforcement profond, le C++, en tant que langage de programmation efficace et excellent, est particulièrement important lorsque les ressources matérielles sont limitées. L’apprentissage par renforcement profond, comme son nom l’indique, combine les technologies des deux domaines de l’apprentissage profond et de l’apprentissage par renforcement. Pour comprendre simplement, l'apprentissage profond fait référence à l'apprentissage de fonctionnalités à partir de données et à la prise de décisions en créant un réseau neuronal multicouche.
2023-08-21
commentaire 0
1123

Définition, classification et cadre algorithmique de l'apprentissage par renforcement
Présentation de l'article:L'apprentissage par renforcement (RL) est un algorithme d'apprentissage automatique entre l'apprentissage supervisé et l'apprentissage non supervisé. Il résout les problèmes par essais, erreurs et apprentissage. Pendant la formation, l'apprentissage par renforcement prend une série de décisions et est récompensé ou puni en fonction des actions effectuées. Le but est de maximiser la récompense totale. L'apprentissage par renforcement a la capacité d'apprendre de manière autonome et de s'adapter, et peut prendre des décisions optimisées dans des environnements dynamiques. Comparé à l'apprentissage supervisé traditionnel, l'apprentissage par renforcement est plus adapté aux problèmes sans étiquettes claires et peut donner de bons résultats dans les problèmes de prise de décision à long terme. À la base, l’apprentissage par renforcement consiste à appliquer des actions basées sur des actions effectuées par un agent, qui est récompensé en fonction de l’impact positif de ses actions sur un objectif global. Il existe deux principaux types d'algorithmes d'apprentissage par renforcement : les algorithmes d'apprentissage basés sur un modèle et ceux sans modèle.
2024-01-24
commentaire 0
690

Problèmes de conception des fonctions de récompense dans l'apprentissage par renforcement
Présentation de l'article:Problèmes de conception de fonctions de récompense dans l'apprentissage par renforcement Introduction L'apprentissage par renforcement est une méthode qui apprend des stratégies optimales grâce à l'interaction entre un agent et l'environnement. Dans l’apprentissage par renforcement, la conception de la fonction de récompense est cruciale pour l’effet d’apprentissage de l’agent. Cet article explorera les problèmes de conception des fonctions de récompense dans l'apprentissage par renforcement et fournira des exemples de code spécifiques. Le rôle de la fonction de récompense et de la fonction de récompense cible constituent une partie importante de l'apprentissage par renforcement et sont utilisés pour évaluer la valeur de récompense obtenue par l'agent dans un certain état. Sa conception aide à guider l'agent pour maximiser la fatigue à long terme en choisissant les actions optimales.
2023-10-09
commentaire 0
1716

apprentissage par renforcement hiérarchique
Présentation de l'article:L'apprentissage par renforcement hiérarchique (HRL) est une méthode d'apprentissage par renforcement qui apprend les comportements et les décisions de haut niveau de manière hiérarchique. Différent des méthodes traditionnelles d'apprentissage par renforcement, HRL décompose la tâche en plusieurs sous-tâches, apprend une stratégie locale dans chaque sous-tâche, puis combine ces stratégies locales pour former une stratégie globale. Cette méthode d'apprentissage hiérarchique peut réduire les difficultés d'apprentissage causées par des environnements de grande dimension et des tâches complexes, et améliorer l'efficacité et les performances de l'apprentissage. Grâce à des stratégies hiérarchiques, HRL peut prendre des décisions à différents niveaux pour atteindre des comportements intelligents de niveau supérieur. Cette approche trouve des applications dans de nombreux domaines tels que le contrôle des robots, le gameplay et la conduite autonome.
2024-01-22
commentaire 0
1405

Apprentissage automatique : les 19 meilleurs projets d'apprentissage par renforcement (RL) sur Github
Présentation de l'article:L'apprentissage par renforcement (RL) est une méthode d'apprentissage automatique dans laquelle les agents apprennent par essais et erreurs. Les algorithmes d’apprentissage par renforcement sont utilisés dans de nombreux domaines, tels que les jeux, la robotique et la finance. L'objectif de RL est de découvrir une stratégie qui maximise les rendements attendus à long terme. Les algorithmes d’apprentissage par renforcement sont généralement divisés en deux catégories : basés sur un modèle et sans modèle. Les algorithmes basés sur des modèles utilisent des modèles environnementaux pour planifier des voies d'action optimales. Cette approche repose sur une modélisation précise de l'environnement, puis sur l'utilisation du modèle pour prédire les résultats de différentes actions. En revanche, les algorithmes sans modèle apprennent directement des interactions avec l’environnement et ne nécessitent pas de modélisation explicite de l’environnement. Cette méthode est plus adaptée aux situations où le modèle d’environnement est difficile à obtenir ou imprécis. En comparaison réelle, les algorithmes d’apprentissage par renforcement sans modèle ne
2024-03-19
commentaire 0
920
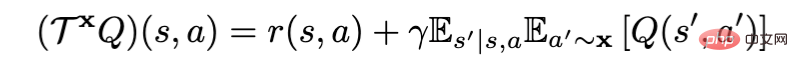
Un nouveau paradigme pour l'apprentissage par renforcement hors ligne ! JD.com et l'Université Tsinghua proposent un algorithme d'apprentissage découplé
Présentation de l'article:L'algorithme d'apprentissage par renforcement hors ligne (Offline RL) est l'une des sous-directions les plus populaires de l'apprentissage par renforcement. L'apprentissage par renforcement hors ligne n'interagit pas avec l'environnement et vise à apprendre les politiques cibles à partir de données précédemment enregistrées. L'apprentissage par renforcement hors ligne est particulièrement intéressant par rapport à l'apprentissage par renforcement en ligne (Online RL) dans les domaines où la collecte de données est coûteuse ou dangereuse, mais où il peut y avoir une grande quantité de données (par exemple, robotique, contrôle industriel, conduite autonome). Lors de l'utilisation de l'opérateur d'évaluation de politique Bellman pour l'évaluation de politique, l'algorithme d'apprentissage par renforcement hors ligne actuel peut être divisé en basé sur RL (x = π) et basé sur l'imitation (x = μ) en fonction de la différence de X, où π est la cible. stratégie , μ est la stratégie comportementale
2023-04-11
commentaire 0
997

Comprendre l'apprentissage par renforcement et ses scénarios d'application
Présentation de l'article:La meilleure façon de dresser un chien est d’utiliser un système de récompense pour le récompenser pour son bon comportement et le punir pour son mauvais comportement. La même stratégie peut être utilisée pour l’apprentissage automatique, appelé apprentissage par renforcement. L'apprentissage par renforcement est une branche de l'apprentissage automatique qui entraîne des modèles grâce à la prise de décision pour trouver la meilleure solution à un problème. Pour améliorer la précision du modèle, des récompenses positives peuvent être utilisées pour encourager l’algorithme à se rapprocher de la bonne réponse, tandis que des récompenses négatives peuvent être attribuées pour punir les écarts par rapport à l’objectif. Il vous suffit de clarifier les objectifs, puis de modéliser les données. Le modèle commencera à interagir avec les données et proposera lui-même des solutions sans intervention manuelle. Exemple d'apprentissage par renforcement Prenons l'exemple du dressage de chiens. Nous fournissons des récompenses telles que des biscuits pour chien pour inciter le chien à effectuer diverses actions. Le chien recherche des récompenses selon une certaine stratégie, il suit donc les ordres et apprend de nouvelles actions, comme mendier.
2024-01-22
commentaire 0
1397

Une méthode pour optimiser l'AB à l'aide de l'apprentissage par renforcement du gradient politique
Présentation de l'article:Les tests AB sont une technique largement utilisée dans les expériences en ligne. Son objectif principal est de comparer deux ou plusieurs versions d'une page ou d'une application afin de déterminer quelle version atteint les meilleurs objectifs commerciaux. Ces objectifs peuvent être des taux de clics, des taux de conversion, etc. En revanche, l’apprentissage par renforcement est une méthode d’apprentissage automatique qui utilise l’apprentissage par essais et erreurs pour optimiser les stratégies de prise de décision. L'apprentissage par renforcement par gradient de politiques est une méthode spéciale d'apprentissage par renforcement qui vise à maximiser les récompenses cumulatives en apprenant des politiques optimales. Les deux ont des applications différentes dans l’optimisation des objectifs commerciaux. Dans les tests AB, nous considérons les différentes versions de page comme différentes actions, et les objectifs commerciaux peuvent être considérés comme des indicateurs importants de signaux de récompense. Afin d'atteindre le maximum d'objectifs commerciaux, nous devons concevoir une stratégie capable de choisir
2024-01-24
commentaire 0
986

Huang Hongbo, expert technique en IA de Xishanju : Intégration pratique de l'apprentissage par renforcement et des arbres de comportement dans les jeux
Présentation de l'article:Du 6 au 7 août 2022, la conférence mondiale sur les technologies d'intelligence artificielle AISummit se tiendra comme prévu. Lors du sous-forum « Exploration des frontières de l'intelligence artificielle » tenu dans l'après-midi du 7, Huang Hongbo, un expert technique en IA de Xishanju, a partagé le thème « Combinaison pratique de l'apprentissage par renforcement et des arbres de comportement dans les jeux » et a partagé en détail le impact de l’apprentissage par renforcement dans le domaine du jeu. Huang Hongbo a déclaré que la mise en œuvre de la technologie d'apprentissage par renforcement ne consiste pas à modifier l'algorithme pour le rendre plus puissant, mais à combiner la technologie d'apprentissage par renforcement avec l'apprentissage en profondeur et la planification de jeux pour former un ensemble complet de solutions et les mettre en œuvre. L'apprentissage par renforcement rend les jeux plus intelligents. La mise en œuvre de l'apprentissage par renforcement dans les jeux peut rendre les jeux plus intelligents et plus jouables.
2023-04-09
commentaire 0
1819


Méthode d'apprentissage par renforcement pour la communication des composants Vue
Présentation de l'article:Méthode d'apprentissage par renforcement pour la communication entre composants Vue Dans le développement de Vue, la communication entre composants est un sujet très important. Cela implique comment partager des données entre plusieurs composants, déclencher des événements, etc. Une approche courante consiste à utiliser les méthodes props et $emit pour la communication entre les composants parent et enfant. Cependant, cette méthode de communication simple peut devenir lourde et difficile à maintenir lorsque la taille des applications augmente et que les relations entre les composants deviennent complexes. L'apprentissage par renforcement est un algorithme qui utilise des mécanismes d'essais, d'erreurs et de récompense pour optimiser la résolution de problèmes. En communication composante, je
2023-07-17
commentaire 0
1269

Sélection de fonctionnalités via des stratégies d'apprentissage par renforcement
Présentation de l'article:La sélection des fonctionnalités est une étape critique dans le processus de création de modèles d’apprentissage automatique. Choisir de bonnes fonctionnalités pour le modèle et la tâche que nous voulons accomplir peut améliorer les performances. Si nous traitons d’ensembles de données de grande dimension, la sélection des caractéristiques est particulièrement importante. Cela permet au modèle d’apprendre plus rapidement et mieux. L’idée est de trouver le nombre optimal de fonctionnalités et les fonctionnalités les plus significatives. Dans cet article, nous présenterons et mettrons en œuvre une nouvelle sélection de fonctionnalités via une stratégie d'apprentissage par renforcement. Nous commençons par discuter de l’apprentissage par renforcement, en particulier des processus de décision markoviens. Il s'agit d'une méthode très nouvelle dans le domaine de la science des données, particulièrement adaptée à la sélection de fonctionnalités. Ensuite, il présente son implémentation et comment installer et utiliser la bibliothèque python (FSRLearning). Enfin, un exemple simple est utilisé pour démontrer cela
2024-06-05
commentaire 0
484

La fonction de valeur dans l'apprentissage par renforcement et l'importance de son équation de Bellman
Présentation de l'article:L'apprentissage par renforcement est une branche de l'apprentissage automatique qui vise à apprendre des actions optimales dans un environnement donné par essais et erreurs. Parmi eux, la fonction de valeur et l'équation de Bellman sont des concepts clés de l'apprentissage par renforcement et nous aident à comprendre les principes de base de ce domaine. La fonction de valeur est le rendement attendu à long terme d’un état donné. En apprentissage par renforcement, nous utilisons souvent des récompenses pour évaluer le bien-fondé d’une action. Les récompenses peuvent être immédiates ou différées, avec des effets se produisant dans les pas de temps ultérieurs. Par conséquent, nous pouvons diviser les fonctions de valeur en deux catégories : les fonctions de valeur d’état et les fonctions de valeur d’action. Les fonctions de valeur d'état évaluent la valeur d'entreprendre une action dans un certain état, tandis que les fonctions de valeur d'action évaluent la valeur d'entreprendre une action spécifique dans un état donné. Algorithmes d'apprentissage par renforcement par calcul et mise à jour de fonctions de valeur
2024-01-22
commentaire 0
925

Jusqu'où Transformer a-t-il évolué en matière d'apprentissage par renforcement ? L'Université Tsinghua, l'Université de Pékin et d'autres ont publié conjointement une revue de TransformRL
Présentation de l'article:L'apprentissage par renforcement (RL) fournit une forme mathématique pour la prise de décision séquentielle, et l'apprentissage par renforcement profond (DRL) a également fait de grands progrès ces dernières années. Cependant, les problèmes d’efficacité des échantillons entravent l’application généralisée des méthodes d’apprentissage par renforcement profond dans le monde réel. Pour résoudre ce problème, un mécanisme efficace consiste à introduire un biais inductif dans le cadre DRL. Dans l’apprentissage par renforcement profond, les approximateurs de fonctions sont très importants. Cependant, par rapport à la conception architecturale en apprentissage supervisé (SL), les problématiques de conception architecturale en DRL sont encore rarement étudiées. La plupart des travaux existants sur les architectures RL ont été menés par la communauté d'apprentissage supervisé/semi-supervisé. Par exemple, pour traiter les entrées basées sur des images de grande dimension dans DRL, une approche courante consiste à introduire des réseaux de neurones convolutifs (CNN) [
2023-04-13
commentaire 0
761

L'apprentissage par renforcement est-il exagéré ?
Présentation de l'article:Traducteur | Révisé par Li Rui | Sun Shujuan Vous pouvez imaginer que vous vous préparez à jouer aux échecs avec vos amis, mais ce n'est pas un être humain, mais un programme informatique qui ne comprend pas les règles du jeu. Mais cette application comprend qu'elle est dédiée à un seul objectif : gagner au jeu. Parce que le programme informatique ne connaît pas les règles, les mouvements qu'il commence à jouer sont aléatoires. Certaines de ces astuces n'ont aucun sens et il vous est facile de gagner. Disons que vous aimez tellement jouer aux échecs avec cet ami que vous devenez accro au jeu. Mais le programme informatique finira par gagner car il apprendra progressivement des moyens et des astuces pour vous vaincre. Même si ce scénario hypothétique peut paraître tiré par les cheveux, il devrait vous donner une idée de l’apprentissage par renforcement, un domaine de l’apprentissage automatique.
2023-04-13
commentaire 0
1139

Algorithme de gradient de politique d'apprentissage par renforcement
Présentation de l'article:L'algorithme de gradient de politique est un algorithme d'apprentissage par renforcement important. Son idée principale est de rechercher la meilleure stratégie en optimisant directement la fonction politique. Par rapport à la méthode d'optimisation indirecte de la fonction de valeur, l'algorithme de gradient politique a une meilleure convergence et stabilité et peut gérer les problèmes d'espace d'action continu, il est donc largement utilisé. L’avantage de cet algorithme est qu’il peut apprendre directement les paramètres de politique sans avoir besoin d’une fonction de valeur estimée. Cela permet à l’algorithme de gradient politique de faire face aux problèmes complexes de l’espace d’états de grande dimension et de l’espace d’action continu. De plus, l'algorithme de gradient politique peut également approximer le gradient par échantillonnage, améliorant ainsi l'efficacité des calculs. En bref, l'algorithme de gradient de politique est une méthode puissante et flexible. Dans l'algorithme de gradient de politique, nous devons définir une fonction de politique\pi(a|s), qui donne.
2024-01-22
commentaire 0
1229
