10000 contenu connexe trouvé

Explication détaillée des types de données PHP8 : optimisez le traitement du Big Data et gérez facilement des données massives
Présentation de l'article:Analyse complète des types de big data PHP8 : Facilitez le traitement de données massives par vos applications Résumé : Avec le développement rapide d'Internet, la quantité de données augmente de jour en jour. Pour les développeurs, comment traiter efficacement des données massives est devenu une question urgente. PHP est un langage de programmation populaire. La dernière version de PHP8 nous apporte une série de types de données puissants pour nous aider à traiter plus facilement des données volumineuses. Cet article fournira une analyse approfondie des 8 principaux types de données dans PHP8 et fournira des exemples de code spécifiques pour aider les développeurs à mieux comprendre et
2024-01-05
commentaire 0
1370

Comment stocker et interroger des données massives en PHP ?
Présentation de l'article:Avec le développement d’Internet et des technologies de l’information, le Big Data est devenu un sujet brûlant. De nombreuses entreprises effectuent le stockage et l'analyse de données volumineuses. En tant que langage de développement Web couramment utilisé, PHP propose également de nombreuses solutions réalisables pour le stockage et les requêtes massives de données. Cet article explique comment stocker et interroger des données massives en PHP. 1. Stockage massif de données MySQL est une base de données relationnelle couramment utilisée et peut stocker des données massives via des sous-bases de données et des tables. Le partitionnement de base de données et le partitionnement de tables font référence à la division d'une grande base de données en plusieurs bases de données plus petites.
2023-05-21
commentaire 0
954

Comment RiSearch PHP gère la recherche et l'analyse de données massives
Présentation de l'article:La façon dont RiSearchPHP gère la recherche et l'analyse de données massives nécessite des exemples de code spécifiques. Résumé : Avec le développement rapide d'Internet, la croissance du volume de données est devenue une tendance. Dans ce cas, comment rechercher et analyser efficacement des données massives est devenu un défi. En tant que moteur de recherche en texte intégral, RiSearchPHP fournit de puissantes fonctions de recherche et d'analyse, qui peuvent nous aider à faire face aux besoins de recherche et d'analyse de données massives. Introduction : À l’ère actuelle du big data, le traitement de données massives est devenu un
2023-10-03
commentaire 0
1138

Partager des conseils sur la façon d'explorer d'énormes quantités de données par lots avec PHP et phpSpider !
Présentation de l'article:Partager des conseils sur la façon d'explorer d'énormes quantités de données par lots avec PHP et phpSpider ! Avec le développement rapide d’Internet, les données massives sont devenues l’une des ressources les plus importantes à l’ère de l’information. Pour de nombreux sites Web et applications, l’exploration et l’obtention de ces données sont essentielles. Dans cet article, nous présenterons comment utiliser les outils PHP et phpSpider pour réaliser une analyse par lots de données massives et fournirons quelques exemples de code pour vous aider à démarrer. Introduction phpSpider est un outil d'exploration open source basé sur PHP qui utilise
2023-07-22
commentaire 0
853

Traitement du Big Data avec les fonctions JavaScript : méthodes clés pour traiter des données massives
Présentation de l'article:JavaScript est un langage de programmation largement utilisé dans le développement Web et le traitement de données, et il a la capacité de gérer le Big Data. Cet article présentera les méthodes clés des fonctions JavaScript dans le traitement de données massives et fournira des exemples de code spécifiques. Lorsqu’il s’agit de Big Data, les performances sont très critiques. Les fonctions et la syntaxe intégrées de JavaScript fonctionnent bien lors du traitement de petites quantités de données, mais lorsque la quantité de données augmente, la vitesse de traitement diminue considérablement. Afin de gérer le Big Data, nous devons prendre certaines mesures d’optimisation. 1. Évitez
2023-11-18
commentaire 0
1052

Stockez et récupérez efficacement des données volumineuses à l'aide de Java et Redis
Présentation de l'article:Stockage et récupération efficaces de données massives à l'aide de Java et Redis Résumé : Le stockage et la récupération de données massives ont toujours été un enjeu important dans le domaine de l'informatique. Dans les applications Internet modernes, l’efficacité du stockage et de la récupération de données massives est cruciale pour les performances du système et l’expérience utilisateur. Cet article explique comment utiliser Java et Redis pour créer un système efficace de stockage et de récupération de données massives. En concevant correctement le modèle de données, en utilisant Redis comme outil de mise en cache et en combinant les opérations efficaces de l'API Java, nous pouvons parvenir à un traitement rapide des données.
2023-07-29
commentaire 0
1440

MySQL et Oracle : comparaison de la prise en charge du stockage et de l'accès massifs aux données
Présentation de l'article:MySQL et Oracle : comparaison de la prise en charge du stockage et de l'accès massifs aux données À l'ère actuelle du Big Data, la demande de stockage et d'accès massifs aux données augmente de jour en jour. MySQL et Oracle sont deux systèmes de gestion de bases de données relationnelles (SGBDR) très respectés, qui présentent certaines différences dans le stockage et l'accès à des données massives. Cet article explorera la comparaison du support entre MySQL et Oracle dans ce domaine et fournira des exemples de code pour l'illustrer. 1. Capacité et performances de stockage MySQL et Oracle ont une capacité de stockage
2023-07-13
commentaire 0
1267

Application de Redis dans le développement Ruby : Comment mettre en cache des données massives
Présentation de l'article:L'application de Redis dans le développement Ruby : Comment mettre en cache des données massives Introduction : Dans le développement d'applications modernes, un traitement efficace des données est crucial. La mise en cache est une stratégie d'optimisation courante pour les applications contenant de grandes quantités de données. Redis est une base de données de cache très populaire qui offre des performances élevées, une flexibilité et est très compatible avec le langage Ruby. Cet article explique comment utiliser Redis pour mettre en cache des données massives dans le développement Ruby afin d'améliorer les performances et l'efficacité des applications. Installation et configuration de Redis : d'abord
2023-07-30
commentaire 0
1275

Comment utiliser le framework de traitement du Big Data en Java pour analyser et traiter des données massives ?
Présentation de l'article:Comment utiliser le framework de traitement du Big Data en Java pour analyser et traiter des données massives ? Avec le développement rapide d’Internet, le traitement de données massives est devenu une tâche importante. Face à une telle quantité de données, les méthodes traditionnelles de traitement des données ne peuvent plus répondre correctement aux besoins, c'est pourquoi l'émergence de cadres de traitement du Big Data est devenue une solution. Dans le domaine Java, il existe de nombreux frameworks de traitement de Big Data matures parmi lesquels choisir, tels qu'Apache Hadoop et Apache Spark. Voici comment réussir
2023-08-02
commentaire 0
1416

Comment implémenter des graphiques statistiques de données massives sous le framework Vue
Présentation de l'article:Comment mettre en œuvre des graphiques statistiques de données massives dans le cadre Vue Introduction : Ces dernières années, l'analyse et la visualisation des données ont joué un rôle de plus en plus important dans tous les domaines. Dans le développement front-end, les graphiques constituent l’un des moyens les plus courants et les plus intuitifs d’afficher des données. Le framework Vue est un framework JavaScript progressif pour la création d'interfaces utilisateur. Il fournit de nombreux outils et bibliothèques puissants qui peuvent nous aider à créer rapidement des graphiques et à afficher des données volumineuses. Cet article présentera comment implémenter des graphiques statistiques de données massives dans le framework Vue, et joindra
2023-08-25
commentaire 0
1672

Comment optimiser php Elasticsearch pour gérer les requêtes de recherche pour des quantités massives de données ?
Présentation de l'article:Comment optimiser phpElasticsearch pour gérer les requêtes de recherche pour des quantités massives de données ? Résumé : À mesure que l'échelle des données continue de croître, les exigences des moteurs de recherche sont de plus en plus élevées. Comment optimiser phpElasticsearch pour gérer les demandes de recherche de données massives est devenu un problème très critique. Cet article aidera les lecteurs à résoudre ce problème en présentant des méthodes d'optimisation et des exemples de code spécifiques. Utiliser l'insertion par lots : lorsque la quantité de données est importante, vous pouvez améliorer les performances d'écriture par insertion par lots. Ci-dessous un exemple
2023-09-13
commentaire 0
811

Échange clé-valeur de tableau PHP : goulots d'étranglement en matière de performances et solutions dans des scénarios de données massives
Présentation de l'article:L'utilisation de l'implémentation de tables de hachage peut résoudre efficacement le goulot d'étranglement des performances de l'échange clé-valeur de tableaux de données massifs de PHP : Goulot d'étranglement des performances : la fonction array_flip() a une complexité temporelle de O(n) dans un scénario de données massives et ses performances sont médiocres. . Solution efficace : utilisez la structure de données de la table de hachage, la complexité temporelle moyenne est de O(1), améliorant considérablement les performances.
2024-05-04
commentaire 0
585

Stockage massif de données et optimisation des requêtes de pagination dans le système de vente flash PHP
Présentation de l'article:Stockage de données de masse et optimisation des requêtes de pagination dans le système de vente flash PHP 1. Introduction Avec le développement rapide de l'industrie du commerce électronique, diverses activités promotionnelles sont devenues un moyen important pour attirer les utilisateurs, et les ventes flash, en tant que type de promotion en ligne hautement concentré activités, sont très importantes pour Les performances et la stabilité du système imposent des exigences extrêmement élevées. Parmi eux, le stockage massif de données et l’optimisation des requêtes de pagination sont l’une des clés pour construire un système de vente flash efficace. Cet article explique comment effectuer un stockage massif de données et optimiser les requêtes de pagination dans le système de vente flash PHP, et fournit des exemples de code spécifiques. 2. Vente flash massive de stockage de données
2023-09-22
commentaire 0
1338

Quel framework PHP est le meilleur pour créer des applications devant gérer de grandes quantités de données ?
Présentation de l'article:Lors du traitement de données massives en PHP, le framework le plus adapté est déterminé en fonction des besoins spécifiques et des critères suivants : Performance : Traitez efficacement les données massives et maintenez des temps de réponse rapides. Évolutivité : évoluez facilement à mesure que les volumes de données augmentent, en évitant les goulots d'étranglement. Concurrence : prend en charge le traitement simultané des données pour gérer les applications à haut débit. Support communautaire : communauté active et documentation riche pour résoudre les problèmes rapidement.
2024-06-02
commentaire 0
607

Intégration de Nginx Proxy Manager et du système de stockage distribué : résoudre d'énormes problèmes d'accès aux données
Présentation de l'article:Intégration de NginxProxyManager et des systèmes de stockage distribués : Pour résoudre le problème de l'accès massif aux données, des exemples de code spécifiques sont nécessaires Introduction : Avec l'avènement de l'ère du Big Data, de nombreuses entreprises sont confrontées au défi du traitement de données massives. Les systèmes de stockage traditionnels à nœud unique ne peuvent pas répondre aux besoins de demandes de données hautement simultanées et de traitement de données en temps réel. Afin de résoudre ce problème, de nombreuses entreprises ont commencé à adopter des systèmes de stockage distribué pour traiter des données massives. Cet article expliquera comment intégrer NginxProxyManager à un système de stockage distribué
2023-09-27
commentaire 0
717

Application de Redis dans le développement Ruby : comment mettre en cache des données utilisateur massives
Présentation de l'article:Application de Redis dans le développement Ruby : Comment mettre en cache des données utilisateur massives Dans les sites Web et les applications modernes, un accès rapide aux données et le temps de réponse sont cruciaux pour l'expérience utilisateur. Cependant, face à des données utilisateur massives et à une concurrence élevée, les performances de la base de données peuvent être limitées. Pour résoudre ce problème, les développeurs peuvent utiliser la technologie de mise en cache pour accélérer l'accès aux données. Redis est un système de stockage clé-valeur en mémoire couramment utilisé qui fournit une solution de mise en cache rapide, flexible et évolutive. Dans cet article, nous allons vous montrer comment
2023-07-31
commentaire 0
1262

HP与Oracle在海量数据业务展开竞争
Présentation de l'article:6月20日HP公司发布Vertica Analytics Platform 5.0版,最新版将与HP自己的硬件产品结合到一起。HP在今年早些时候收购了Vertica,这将帮助HP在逐渐升温的海量数据市场发挥关键作用。 Vertica基于列存储。基于列存储的设计相比传统面向行存储的数据库具有巨大
2016-06-07
commentaire 0
2194


Une première mondiale ! China Unicom achève la vérification de la transmission sans perte, à haut débit et sur une vaste zone de données massives sur 3 000 kilomètres
Présentation de l'article:Selon les informations du 17 mai, selon le compte public officiel de China Unicom, le groupe China Unicom a récemment organisé l'Institut de recherche China Unicom, l'Institut de conception des communications de Chine et d'autres unités pour s'attaquer conjointement aux problèmes clés liés à l'accès aux entreprises d'informatique intelligente/superinformatique et au transport d'interconnexions. exigences sur le réseau existant. La première vérification de transmission sans perte à haut débit sur une vaste zone au monde de données massives avec une distance de transmission réelle de plus de 3 000 kilomètres. Il a été rapporté que dans les scénarios commerciaux d'informatique intelligente et de supercalcul, la rapidité de transmission de données massives au niveau du téraoctet via une bande passante traditionnelle de 100 M ou Gigabit ne peut pas répondre aux exigences, et le coût de la transmission via des lignes dédiées à plus grande vitesse est trop élevé. Par conséquent, la transmission efficace et sans perte de données massives a toujours été un problème dans l’industrie. Cette fois, sur la base du réseau national ROADM entièrement optique de China Unicom et de l'Internet fédérateur 169, les données de formation commerciale en informatique intelligente de Shanghai sont importées dans le cluster de formation en informatique intelligente de Ningxia Zhongwei.
2024-06-01
commentaire 0
883
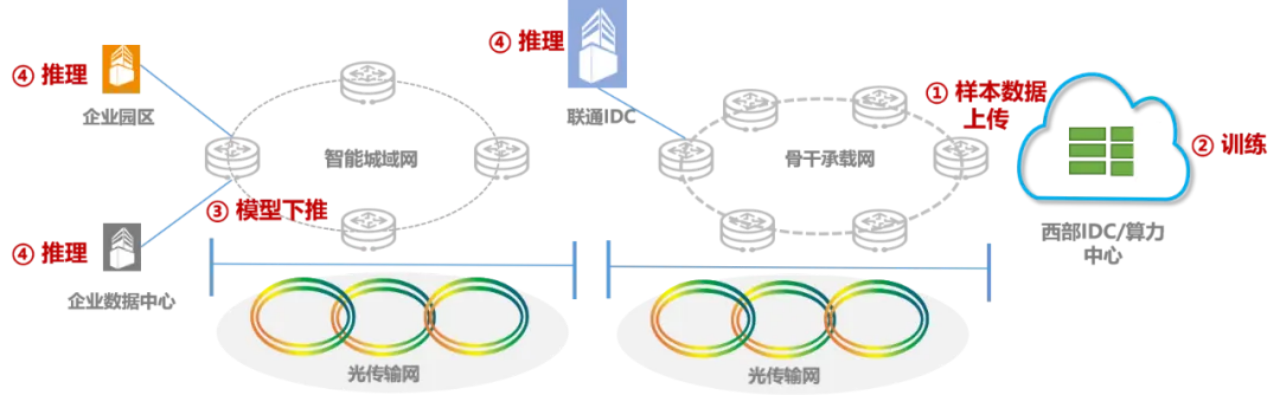
Pour la première fois au monde, China Unicom a finalisé la vérification de la transmission sans perte, à haut débit et sur une vaste zone de données massives sur 3 000 kilomètres.
Présentation de l'article:Selon les informations du 16 mai, China Unicom a annoncé aujourd'hui que le groupe China Unicom avait organisé l'Institut de recherche China Unicom, l'Institut de conception Zhongxun, la succursale de Shanghai, la succursale de Ningxia et d'autres unités pour résoudre conjointement les problèmes clés liés à l'accès aux entreprises d'informatique/superinformatique intelligente et au transport d'interconnexions. besoins. Réalisation de la première vérification de transmission sans perte à haut débit et sur une vaste zone au monde de données massives avec une distance de transmission réelle de plus de 3 000 kilomètres sur le réseau existant. Dans les scénarios commerciaux d'informatique intelligente et de supercalcul, il est difficile de répondre aux exigences de rapidité de transmission de données massives au niveau du téraoctet via une bande passante traditionnelle de 100 M ou Gigabit, et le coût est trop élevé pour transmettre via des lignes dédiées à plus grande vitesse. les données massives ont toujours été un problème standard dans l’industrie. Cette fois, sur la base du réseau national ROADM entièrement optique de China Unicom et de l'Internet fédérateur 169, les données de formation commerciale en informatique intelligente de Shanghai sont importées dans le cluster de formation en informatique intelligente de Ningxia Zhongwei.
2024-05-30
commentaire 0
998
