10000 contenu connexe trouvé

En modifiant une ligne de code, la formation PyTorch est trois fois plus rapide. Ces « technologies avancées » sont la clé.
Présentation de l'article:Récemment, Sebastian Raschka, chercheur bien connu dans le domaine de l'apprentissage profond et éducateur en chef en intelligence artificielle chez LightningAI, a prononcé un discours d'ouverture « ScalingPyTorchModelTrainingWithMinimalCodeChanges » au CVPR2023. Afin de partager les résultats de la recherche avec davantage de personnes, Sebastian Raschka a compilé le discours dans un article. L'article explore comment faire évoluer la formation du modèle PyTorch avec un minimum de modifications de code et montre que l'accent est mis sur l'exploitation de méthodes de précision mixte et de modes de formation multi-GPU plutôt que sur des optimisations de machine de bas niveau. Vue d'utilisation des articles
2023-08-14
commentaire 0
974

Recherche sur les biais et les méthodes d'autocorrection des modèles de langage
Présentation de l'article:Le biais du modèle linguistique est que lors de la génération du texte, il peut être biaisé en faveur de certains groupes de personnes, thèmes ou sujets, ce qui rend le texte impartial, neutre ou discriminatoire. Ce biais peut provenir de facteurs tels que la sélection des données d'entraînement, la conception de l'algorithme d'entraînement ou la structure du modèle. Pour résoudre ce problème, nous devons nous concentrer sur la diversité des données et garantir que les données de formation incluent une variété d’arrière-plans et de perspectives. De plus, nous devrions revoir les algorithmes de formation et les structures de modèles pour garantir leur équité et leur neutralité afin d'améliorer la qualité et l'inclusivité du texte généré. Par exemple, il peut y avoir un biais excessif en faveur de certaines catégories dans les données d'entraînement, ce qui amène le modèle à favoriser davantage ces catégories lors de la génération de texte. Ce biais peut entraîner de mauvaises performances du modèle lorsqu'il traite d'autres catégories, affectant ainsi les performances du modèle. De plus, il peut y avoir des divergences dans la conception du modèle.
2024-01-22
commentaire 0
466

Python implémente la classification des machines à vecteurs de support (SVM) : explication détaillée des principes de l'algorithme
Présentation de l'article:Dans l'apprentissage automatique, les machines à vecteurs de support (SVM) sont souvent utilisées pour la classification des données et l'analyse de régression, et sont des modèles d'algorithmes discriminants basés sur des hyperplans de séparation. En d’autres termes, étant donné les données d’entraînement étiquetées, l’algorithme génère un hyperplan optimal pour classer de nouveaux exemples. Le modèle d'algorithme de machine à vecteurs de support (SVM) représente les exemples sous forme de points dans l'espace. Après le mappage, les exemples de différentes catégories sont divisés autant que possible. En plus d'effectuer une classification linéaire, les machines à vecteurs de support (SVM) peuvent effectuer efficacement une classification non linéaire, en mappant implicitement leurs entrées dans un espace de fonctionnalités de grande dimension. À quoi sert une machine à vecteurs de support ? Étant donné un ensemble d'exemples de formation, chaque exemple de formation est marqué d'une catégorie selon deux catégories, puis un modèle est construit via l'algorithme de formation de la machine à vecteurs de support (SVM) pour classer les nouveaux exemples en
2024-01-24
commentaire 0
1196

Brisant le mur dimensionnel, X-Dreamer apporte du texte de haute qualité à la génération 3D, intégrant les domaines de la génération 2D et 3D.
Présentation de l'article:Ces dernières années, des progrès significatifs ont été réalisés dans la conversion automatique de texte en contenu 3D, grâce au développement de modèles de diffusion pré-entraînés [1, 2, 3]. Parmi eux, DreamFusion[4] a introduit une méthode efficace qui exploite un modèle de diffusion 2D pré-entraîné[5] pour générer automatiquement des actifs 3D à partir de texte sans avoir besoin d'un ensemble de données d'actifs 3D spécialisé. Une innovation clé introduite par DreamFusion est l'échantillonnage par distillation fractionnée. (SDS). L'algorithme utilise un modèle de diffusion 2D pré-entraîné pour évaluer une représentation 3D unique, telle que NeRF [6], l'optimisant ainsi pour garantir que l'image rendue depuis n'importe quelle perspective de caméra conserve une haute cohérence avec le texte donné. Inspirés par l'algorithme fondateur SDS, plusieurs
2023-12-15
commentaire 0
605

ConvNeXt V2 est là, utilisant uniquement l'architecture de convolution la plus simple, les performances ne sont pas inférieures à celles de Transformer
Présentation de l'article:Après des décennies de recherche fondamentale, le domaine de la reconnaissance visuelle a marqué le début d’une nouvelle ère d’apprentissage des représentations visuelles à grande échelle. Les modèles de vision pré-entraînés à grande échelle sont devenus un outil essentiel pour l’apprentissage des fonctionnalités et les applications de vision. Les performances d'un système d'apprentissage de représentation visuelle sont grandement affectées par trois facteurs principaux : l'architecture du réseau neuronal du modèle, la méthode utilisée pour entraîner le réseau et les données d'entraînement. Les améliorations de chaque facteur contribuent à l’amélioration des performances globales du modèle. Les innovations dans la conception de l'architecture des réseaux neuronaux ont toujours joué un rôle important dans le domaine de l'apprentissage des représentations. L'architecture de réseau neuronal convolutif (ConvNet) a eu un impact significatif sur la recherche en vision par ordinateur, permettant l'utilisation de méthodes universelles d'apprentissage de fonctionnalités dans diverses tâches de reconnaissance visuelle sans recourir à l'intelligence artificielle.
2023-04-11
commentaire 0
1534

Principes de base et exemples de classification des algorithmes KNN
Présentation de l'article:L'algorithme KNN est un algorithme de classification simple et facile à utiliser, adapté aux ensembles de données à petite échelle et aux espaces de fonctionnalités de faible dimension. Il fonctionne bien dans des domaines tels que la classification d'images et la classification de textes, et est populaire en raison de sa simplicité de mise en œuvre et de sa facilité de compréhension. L'idée de base de l'algorithme KNN est de trouver les K voisins les plus proches en comparant les caractéristiques de l'échantillon à classer avec les caractéristiques de l'échantillon d'apprentissage, et de déterminer la catégorie de l'échantillon à classer en fonction des catégories de ceux-ci. K voisins. L'algorithme KNN utilise un ensemble de formation avec des catégories étiquetées et un ensemble de tests à classer. Le processus de classification de l'algorithme KNN comprend les étapes suivantes : d'abord, calculer la distance entre l'échantillon à classer et tous les échantillons d'apprentissage, puis sélectionner les K voisins les plus proches puis voter selon les catégories des K voisins ; Catégorie d'échantillon de classification ;
2024-01-23
commentaire 0
787

Introduction au gameplay du terrain d'entraînement commun 'White Wattle Corridor'
Présentation de l'article:Comment jouer au terrain d'entraînement commun du couloir de Baijing ? Le terrain d'entraînement commun est l'un des modes de jeu de White Wattle Corridor. De nombreux joueurs ne savent pas comment y jouer spécifiquement. Les joueurs peuvent se référer au contenu de l'article pour en savoir plus sur le gameplay du terrain d'entraînement commun. Introduction au gameplay du White Wattle Corridor Joint Training Ground. Je pense que cela vous sera certainement utile, jetons un coup d'œil. Introduction au gameplay du terrain d'entraînement commun "Baijing Corridor" Introduction au gameplay : 1. Tout d'abord, les joueurs doivent capturer quatre zones de défense A, B, C et D dans l'ordre du temps. Il y a 3 partitions sous A, B, C et D. 2. Le joueur place un personnage dans le coin carré du camp et dans le coin du losange pour combattre et sera stationné ici. 3. Enfin, le score est basé sur les résultats de la bataille. Règles de notation : 1. Tous les 1 000 scores, le nombre de sièges à déduction augmente de 5 % et la progression de la déduction indique le maximum.
2024-01-12
commentaire 0
1251

Algorithme symbolique de retour à l'origine
Présentation de l'article:L'algorithme de régression symbolique est un algorithme d'apprentissage automatique qui crée automatiquement des modèles mathématiques. Son objectif principal est de prédire la valeur de la variable de sortie en analysant la relation fonctionnelle entre les variables dans les données d'entrée. Cet algorithme combine les idées des algorithmes génétiques et des stratégies évolutives pour améliorer progressivement la précision du modèle en générant et en combinant aléatoirement des expressions mathématiques. En optimisant continuellement le modèle, les algorithmes de régression symbolique peuvent nous aider à mieux comprendre et prédire les relations complexes entre les données. Le processus de l'algorithme de régression symbolique est le suivant : 1. Définir le problème : déterminer les variables d'entrée et les variables de sortie. 2. Initialisez la population : générez aléatoirement un ensemble d'expressions mathématiques en tant que population. Évaluer la condition physique : utilisez l'expression mathématique de chaque individu pour prédire les données de l'ensemble d'entraînement et calculez l'erreur entre la valeur prédite et la valeur réelle comme adaptation
2024-01-23
commentaire 0
1457

Fonctions et méthodes d'optimisation des hyperparamètres
Présentation de l'article:Les hyperparamètres sont des paramètres qui doivent être définis avant d'entraîner le modèle. Ils ne peuvent pas être appris à partir des données d'entraînement et doivent être ajustés manuellement ou déterminés par une recherche automatique. Les hyperparamètres courants incluent le taux d'apprentissage, le coefficient de régularisation, le nombre d'itérations, la taille du lot, etc. Le réglage des hyperparamètres est le processus d’optimisation des performances de l’algorithme et est très important pour améliorer la précision et les performances de l’algorithme. Le but du réglage des hyperparamètres est de trouver la meilleure combinaison d’hyperparamètres pour améliorer les performances et la précision de l’algorithme. Si le réglage est insuffisant, cela peut entraîner de mauvaises performances de l'algorithme et des problèmes tels qu'un surajustement ou un sous-ajustement. Le réglage peut améliorer la capacité de généralisation du modèle et lui permettre de mieux fonctionner sur de nouvelles données. Il est donc crucial d’ajuster pleinement les hyperparamètres. Il existe de nombreuses méthodes de réglage des hyperparamètres. Les méthodes courantes incluent la recherche par grille, la recherche aléatoire et l'optimisation bayésienne.
2024-01-22
commentaire 0
818

Machine d'apprentissage automatique (AutoML)
Présentation de l'article:L'apprentissage automatique automatique (AutoML) change la donne dans le domaine de l'apprentissage automatique. Il peut sélectionner et optimiser automatiquement les algorithmes, rendant le processus de formation des modèles d'apprentissage automatique plus simple et plus efficace. Même si vous n'avez aucune expérience en apprentissage automatique, vous pouvez facilement entraîner un modèle offrant d'excellentes performances à l'aide d'AutoML. AutoML fournit une approche d'IA explicable pour améliorer l'interprétabilité des modèles. De cette façon, les data scientists peuvent mieux comprendre le processus de prédiction du modèle. Ceci est particulièrement utile dans les domaines de la santé, de la finance et des systèmes autonomes. Cela peut aider à identifier les biais dans les données et à éviter des prédictions incorrectes. AutoML exploite l'apprentissage automatique pour résoudre des problèmes du monde réel, notamment des tâches telles que la sélection d'algorithmes, l'optimisation des hyperparamètres et l'ingénierie des fonctionnalités. Voici quelques méthodes couramment utilisées : Dieu
2024-01-22
commentaire 0
970

Capable d'aligner des humains sans RLHF, performances comparables à ChatGPT ! Une équipe chinoise propose le modèle Wombat
Présentation de l'article:ChatGPT d'OpenAI est capable de comprendre une grande variété d'instructions humaines et de bien performer dans différentes tâches linguistiques. Ceci est possible grâce à une nouvelle méthode de réglage fin du modèle de langage à grande échelle appelée RLHF (Aligned Human Feedback via Reinforcement Learning). La méthode RLHF libère la capacité des modèles de langage à suivre les instructions humaines, rendant les capacités des modèles de langage cohérentes avec les besoins et les valeurs humains. Actuellement, les travaux de recherche du RLHF utilisent principalement l'algorithme PPO pour optimiser les modèles de langage. Cependant, l'algorithme PPO contient de nombreux hyperparamètres et nécessite que plusieurs modèles indépendants coopèrent les uns avec les autres pendant le processus d'itération de l'algorithme, de sorte que des détails d'implémentation erronés peuvent conduire à de mauvais résultats de formation. Dans le même temps, les algorithmes d’apprentissage par renforcement ne sont pas nécessaires du point de vue de l’alignement humain. Argument
2023-05-03
commentaire 0
1360

Réflexion profonde | Où se situe la limite des capacités des grands modèles ?
Présentation de l'article:Si nous disposons de ressources infinies, telles que des données infinies, une puissance de calcul infinie, des modèles infinis, des algorithmes d'optimisation parfaits et des performances de généralisation, le modèle pré-entraîné résultant peut-il être utilisé pour résoudre tous les problèmes ? C’est une question qui préoccupe tout le monde, mais les théories existantes sur l’apprentissage automatique ne peuvent pas y répondre. Cela n'a rien à voir avec la théorie de la capacité d'expression, car le modèle est infini et la capacité d'expression est naturellement infinie. Cela n’a pas non plus d’importance pour la théorie de l’optimisation et de la généralisation, car nous supposons que les performances d’optimisation et de généralisation de l’algorithme sont parfaites. En d’autres termes, les problèmes des recherches théoriques antérieures n’existent plus ici ! Aujourd'hui, j'aimerais vous présenter l'article OnthePowerofFoundationModels que j'ai publié à l'ICML'2023. Du point de vue de la théorie des catégories,
2023-09-08
commentaire 0
1330

Problème de surajustement dans les algorithmes d'apprentissage automatique
Présentation de l'article:Le problème du surajustement dans les algorithmes d'apprentissage automatique nécessite des exemples de code spécifiques. Dans le domaine de l'apprentissage automatique, le problème du surajustement des modèles est l'un des défis courants. Lorsqu'un modèle surajuste les données d'entraînement, il devient trop sensible au bruit et aux valeurs aberrantes, ce qui entraîne de mauvaises performances du modèle sur les nouvelles données. Afin de résoudre le problème du surajustement, nous devons adopter des méthodes efficaces pendant le processus de formation du modèle. Une approche courante consiste à utiliser des techniques de régularisation telles que la régularisation L1 et la régularisation L2. Ces techniques limitent la complexité du modèle en ajoutant un terme de pénalité pour empêcher le modèle d'en faire trop.
2023-10-09
commentaire 0
1037

Comment les fonctionnalités influencent-elles le choix du type de modèle ?
Présentation de l'article:Les fonctionnalités jouent un rôle important dans l’apprentissage automatique. Lors de la création d’un modèle, nous devons choisir avec soin les fonctionnalités à former. La sélection des fonctionnalités affectera directement les performances et le type du modèle. Cet article explore la manière dont les fonctionnalités affectent le type de modèle. 1. Nombre de fonctionnalités Le nombre de fonctionnalités est l'un des facteurs importants affectant le type de modèle. Lorsque le nombre de fonctionnalités est faible, des algorithmes d'apprentissage automatique traditionnels tels que la régression linéaire, les arbres de décision, etc. sont généralement utilisés. Ces algorithmes sont adaptés au traitement d’un petit nombre de caractéristiques et la vitesse de calcul est relativement rapide. Cependant, lorsque le nombre de fonctionnalités devient très important, les performances de ces algorithmes se dégradent généralement car ils ont des difficultés à traiter des données de grande dimension. Par conséquent, dans ce cas, nous devons utiliser des algorithmes plus avancés tels que des machines à vecteurs de support, des réseaux de neurones, etc. Ces algorithmes sont capables de gérer des
2024-01-24
commentaire 0
1035

Conseils d'évaluation du modèle d'apprentissage automatique en Python
Présentation de l'article:L'apprentissage automatique est un domaine complexe qui englobe de nombreuses techniques et méthodes qui nécessitent des tests et une évaluation fréquents des performances du modèle lors de la résolution de problèmes du monde réel. Les techniques d'évaluation de modèles d'apprentissage automatique sont des compétences très importantes en Python car elles aident les développeurs à déterminer quand un modèle est fiable et comment il fonctionne sur un ensemble de données spécifique. Voici quelques techniques courantes d'évaluation de modèles d'apprentissage automatique en Python : Validation croisée La validation croisée est une technique statistique couramment utilisée pour évaluer les performances des algorithmes d'apprentissage automatique. L'ensemble de données est divisé en formation
2023-06-10
commentaire 0
1702
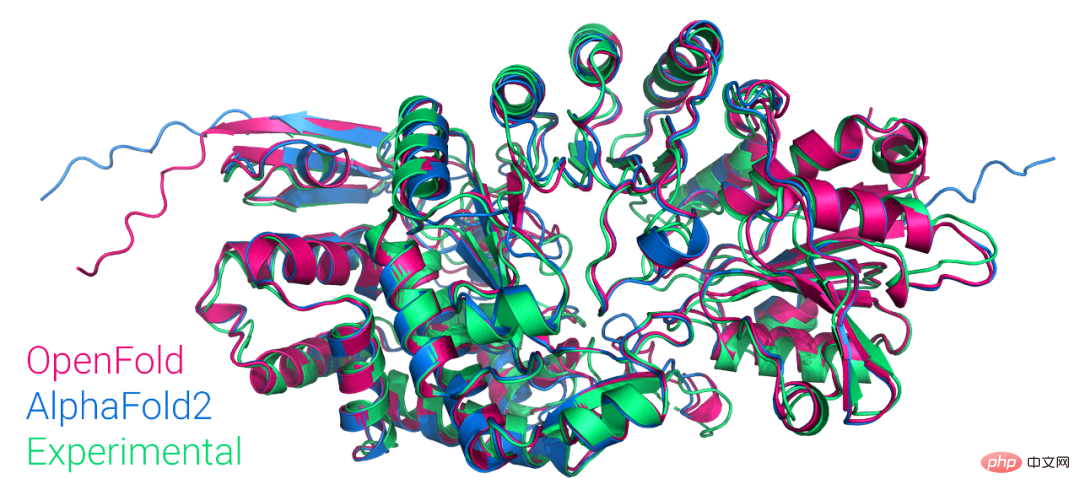
La première version PyTorch accessible au public d'AlphaFold2 est reproduite, en open source par l'Université de Columbia et compte plus de 1 000 étoiles.
Présentation de l'article:Tout à l'heure, Mohammed AlQuraishi, professeur adjoint de biologie des systèmes à l'Université de Columbia, a annoncé sur Twitter avoir formé un modèle appelé OpenFold à partir de zéro, qui est une réapparition PyTorch d'AlphaFold2 pouvant être entraînée. Mohammed AlQuraishi a également déclaré qu'il s'agit de la première reproduction d'AlphaFold2 accessible au public. AlphaFold2 peut prédire périodiquement les structures protéiques avec une précision atomique, en utilisant une technologie conçue pour tirer parti d'algorithmes d'alignement de séquences multiples et d'apprentissage en profondeur, combinés à des connaissances physiques et biologiques sur les structures protéiques pour améliorer les prédictions. Il obtient d’excellents résultats dans la prédiction des structures des 2/3 des protéines.
2023-04-13
commentaire 0
1277

Le premier LLM à prendre en charge la quantification à virgule flottante 4 bits est ici, résolvant les problèmes de déploiement de LLaMA, BERT, etc.
Présentation de l'article:La compression des grands modèles de langage (LLM) a toujours attiré beaucoup d'attention, et la quantification post-formation (Post-training Quantization) est l'un des algorithmes couramment utilisés. Cependant, la plupart des méthodes PTQ existantes sont des quantifications entières et lorsque le nombre de bits. est inférieur à 8, après quantification, la précision du modèle diminuera considérablement. Par rapport à la quantification Integer (INT), la quantification FloatingPoint (FP) peut mieux représenter la distribution à longue traîne, de sorte que de plus en plus de plates-formes matérielles commencent à prendre en charge la quantification FP. Cet article donne une solution à la quantification FP de grands modèles. L’article a été publié sur EMNLP2023. Adresse papier : https://arxiv.org/abs/2310.16
2023-11-18
commentaire 0
1195

Les performances de prise de vue nocturne du Redmi K70 Pro ont été grandement améliorées, grâce à l'aide de l'algorithme Xiaomi Night Owl
Présentation de l'article:Selon les informations du 27 novembre, Redmi a récemment lancé son dernier téléphone mobile K70Pro. Ce téléphone est non seulement équipé de la technologie anti-tremblement optique OIS, mais introduit également pour la première fois l'algorithme Night Owl développé par Xiaomi, offrant aux utilisateurs une expérience de prise de vue nocturne sans précédent. Selon la compréhension de l'éditeur, l'algorithme Night Owl a fait ses débuts. sur Xiaomi 11 Ultra Une fonctionnalité importante. Cet algorithme se concentre sur la résolution des problèmes de bruit courants dans la photographie de nuit. Grâce au système d'étalonnage du bruit des scènes de nuit développé de manière indépendante, il effectue une modélisation mathématique précise de la distribution et de la forme du bruit des scènes de nuit. Afin d'améliorer l'effet de l'algorithme Night Owl, l'équipe d'ingénierie de Xiaomi a adopté une méthode innovante pour augmenter la diversité des données de bruit simulées en ajoutant du bruit à la simulation, enrichissant ainsi les données d'entraînement de l'algorithme et rendant le processus de débruitage
2023-11-27
commentaire 0
1713

Comprendre l'apprentissage par renforcement et ses scénarios d'application
Présentation de l'article:La meilleure façon de dresser un chien est d’utiliser un système de récompense pour le récompenser pour son bon comportement et le punir pour son mauvais comportement. La même stratégie peut être utilisée pour l’apprentissage automatique, appelé apprentissage par renforcement. L'apprentissage par renforcement est une branche de l'apprentissage automatique qui entraîne des modèles grâce à la prise de décision pour trouver la meilleure solution à un problème. Pour améliorer la précision du modèle, des récompenses positives peuvent être utilisées pour encourager l’algorithme à se rapprocher de la bonne réponse, tandis que des récompenses négatives peuvent être attribuées pour punir les écarts par rapport à l’objectif. Il vous suffit de clarifier les objectifs, puis de modéliser les données. Le modèle commencera à interagir avec les données et proposera lui-même des solutions sans intervention manuelle. Exemple d'apprentissage par renforcement Prenons l'exemple du dressage de chiens. Nous fournissons des récompenses telles que des biscuits pour chien pour inciter le chien à effectuer diverses actions. Le chien recherche des récompenses selon une certaine stratégie, il suit donc les ordres et apprend de nouvelles actions, comme mendier.
2024-01-22
commentaire 0
1415

China Unicom lance un grand modèle d'IA d'image et de texte capable de générer des images et des clips vidéo à partir de texte
Présentation de l'article:Driving China News le 28 juin 2023, aujourd'hui, lors du Mobile World Congress à Shanghai, China Unicom a publié le modèle graphique « Honghu Graphic Model 1.0 ». China Unicom a déclaré que le modèle graphique Honghu est le premier grand modèle pour les services à valeur ajoutée des opérateurs. Le journaliste de China Business News a appris que le modèle graphique de Honghu dispose actuellement de deux versions de 800 millions de paramètres de formation et de 2 milliards de paramètres de formation, qui peuvent réaliser des fonctions telles que des images basées sur du texte, le montage vidéo et des images basées sur des images. En outre, le président de China Unicom, Liu Liehong, a également déclaré dans son discours d'ouverture d'aujourd'hui que l'IA générative inaugure une singularité de développement et que 50 % des emplois seront profondément affectés par l'intelligence artificielle au cours des deux prochaines années.
2023-06-29
commentaire 0
1520
