10000 contenu connexe trouvé

Méthode d'apprentissage par renforcement pour la communication des composants Vue
Présentation de l'article:Méthode d'apprentissage par renforcement pour la communication entre composants Vue Dans le développement de Vue, la communication entre composants est un sujet très important. Cela implique comment partager des données entre plusieurs composants, déclencher des événements, etc. Une approche courante consiste à utiliser les méthodes props et $emit pour la communication entre les composants parent et enfant. Cependant, cette méthode de communication simple peut devenir lourde et difficile à maintenir lorsque la taille des applications augmente et que les relations entre les composants deviennent complexes. L'apprentissage par renforcement est un algorithme qui utilise des mécanismes d'essais, d'erreurs et de récompense pour optimiser la résolution de problèmes. En communication composante, je
2023-07-17
commentaire 0
1293

Comment créer un algorithme d'apprentissage par renforcement en utilisant PHP
Présentation de l'article:Comment créer un algorithme d'apprentissage par renforcement à l'aide de PHP Introduction : L'apprentissage par renforcement est une méthode d'apprentissage automatique qui apprend à prendre des décisions optimales en interagissant avec l'environnement. Dans cet article, nous présenterons comment créer des algorithmes d'apprentissage par renforcement à l'aide du langage de programmation PHP et fournirons des exemples de code pour aider les lecteurs à mieux comprendre. 1. Qu'est-ce qu'un algorithme d'apprentissage par renforcement ? L'algorithme d'apprentissage par renforcement est une méthode d'apprentissage automatique qui apprend à prendre des décisions en observant les commentaires de l'environnement. Contrairement à d’autres algorithmes d’apprentissage automatique, les algorithmes d’apprentissage par renforcement ne sont pas uniquement basés sur des données existantes.
2023-07-31
commentaire 0
712

Apprenez à assembler un circuit imprimé en 20 minutes ! Le framework SERL open source a un taux de réussite de contrôle de précision de 100 % et est trois fois plus rapide que les humains.
Présentation de l'article:Désormais, les robots peuvent apprendre des tâches de contrôle de précision en usine. Ces dernières années, des progrès significatifs ont été réalisés dans le domaine des technologies d'apprentissage par renforcement des robots, comme la marche des quadrupèdes, la préhension, la manipulation adroite, etc., mais la plupart d'entre eux se limitent à la phase de démonstration en laboratoire. L’application généralisée de la technologie d’apprentissage par renforcement robotique aux environnements de production réels se heurte encore à de nombreux défis, ce qui limite dans une certaine mesure sa portée d’application dans des scénarios réels. Dans le processus d'application pratique de la technologie d'apprentissage par renforcement, il est nécessaire de surmonter plusieurs problèmes complexes, notamment la configuration du mécanisme de récompense, la réinitialisation de l'environnement, l'amélioration de l'efficacité des échantillons et la garantie de la sécurité des actions. Les experts du secteur soulignent que la résolution des nombreux problèmes liés à la mise en œuvre réelle de la technologie d’apprentissage par renforcement est aussi importante que l’innovation continue de l’algorithme lui-même. Face à ce défi, des chercheurs de l'Université de Californie à Berkeley, de l'Université de Stanford, de l'Université de Washington et
2024-02-21
commentaire 0
1206

La vitesse de formation est augmentée de 17 %. Le cadre de recherche sur l'apprentissage par renforcement open source du quatrième paradigme prend en charge la formation mono-agent et multi-agents.
Présentation de l'article:OpenRL est un cadre de recherche d'apprentissage par renforcement basé sur PyTorch développé par l'équipe d'apprentissage par renforcement Fourth Paradigm. Il prend en charge la formation de tâches mono-agent, multi-agents, en langage naturel et autres. OpenRL est développé sur la base de PyTorch, dans le but de fournir à la communauté de recherche sur l'apprentissage par renforcement une plate-forme facile à utiliser, flexible, efficace et durablement évolutive. Actuellement, les fonctionnalités prises en charge par OpenRL incluent : une interface commune facile à utiliser et prenant en charge la formation mono-agent et multi-agent ; prend en charge la formation par apprentissage par renforcement pour les tâches en langage naturel (telles que les tâches de dialogue) ; prend en charge l'importation de modèles et de données depuis HuggingFace ; ; prend en charge LSTM, GRU, les modèles tels que Transformer prennent en charge une variété d'accélérations d'entraînement, telles que : l'entraînement automatique de précision mixte,
2023-05-11
commentaire 0
1078

Huang Hongbo, expert technique en IA de Xishanju : Intégration pratique de l'apprentissage par renforcement et des arbres de comportement dans les jeux
Présentation de l'article:Du 6 au 7 août 2022, la conférence mondiale sur les technologies d'intelligence artificielle AISummit se tiendra comme prévu. Lors du sous-forum « Exploration des frontières de l'intelligence artificielle » tenu dans l'après-midi du 7, Huang Hongbo, un expert technique en IA de Xishanju, a partagé le thème « Combinaison pratique de l'apprentissage par renforcement et des arbres de comportement dans les jeux » et a partagé en détail le impact de l’apprentissage par renforcement dans le domaine du jeu. Huang Hongbo a déclaré que la mise en œuvre de la technologie d'apprentissage par renforcement ne consiste pas à modifier l'algorithme pour le rendre plus puissant, mais à combiner la technologie d'apprentissage par renforcement avec l'apprentissage en profondeur et la planification de jeux pour former un ensemble complet de solutions et les mettre en œuvre. L'apprentissage par renforcement rend les jeux plus intelligents. La mise en œuvre de l'apprentissage par renforcement dans les jeux peut rendre les jeux plus intelligents et plus jouables.
2023-04-09
commentaire 0
1834

Apprentissage automatique : les 19 meilleurs projets d'apprentissage par renforcement (RL) sur Github
Présentation de l'article:L'apprentissage par renforcement (RL) est une méthode d'apprentissage automatique dans laquelle les agents apprennent par essais et erreurs. Les algorithmes d’apprentissage par renforcement sont utilisés dans de nombreux domaines, tels que les jeux, la robotique et la finance. L'objectif de RL est de découvrir une stratégie qui maximise les rendements attendus à long terme. Les algorithmes d’apprentissage par renforcement sont généralement divisés en deux catégories : basés sur un modèle et sans modèle. Les algorithmes basés sur des modèles utilisent des modèles environnementaux pour planifier des voies d'action optimales. Cette approche repose sur une modélisation précise de l'environnement, puis sur l'utilisation du modèle pour prédire les résultats de différentes actions. En revanche, les algorithmes sans modèle apprennent directement des interactions avec l’environnement et ne nécessitent pas de modélisation explicite de l’environnement. Cette méthode est plus adaptée aux situations où le modèle d’environnement est difficile à obtenir ou imprécis. En comparaison réelle, les algorithmes d’apprentissage par renforcement sans modèle ne
2024-03-19
commentaire 0
939
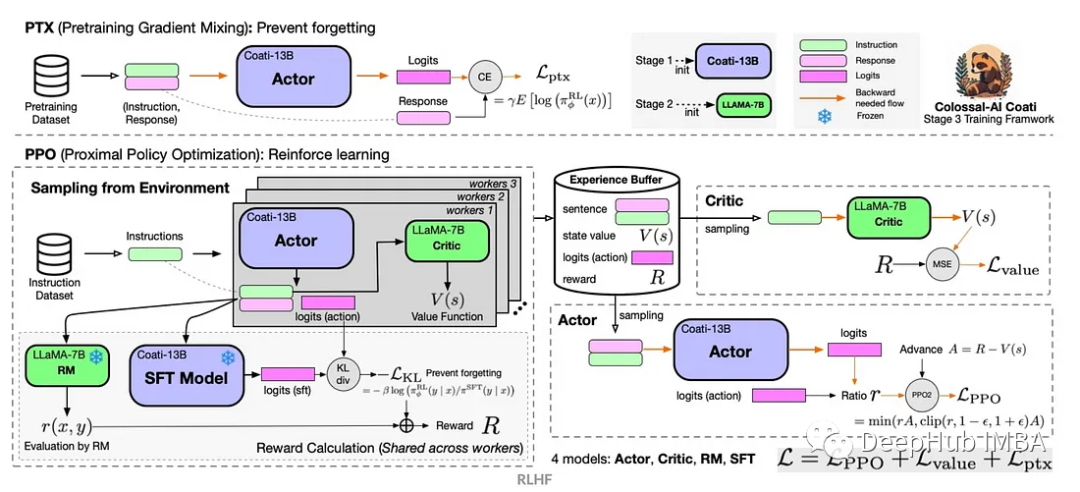
Apprentissage par renforcement Deep Q-learning utilisant la simulation de bras robotique de Panda-Gym
Présentation de l'article:L'apprentissage par renforcement (RL) est une méthode d'apprentissage automatique qui permet à un agent d'apprendre comment se comporter dans son environnement par essais et erreurs. Les agents sont récompensés ou punis pour avoir pris des mesures qui conduisent aux résultats souhaités. Au fil du temps, l'agent apprend à prendre des mesures qui maximisent la récompense attendue. Les agents RL sont généralement formés à l'aide d'un processus de décision markovien (MDP), un cadre mathématique pour modéliser des problèmes de décision séquentielle. Le MDP se compose de quatre parties : État : un ensemble d'états possibles de l'environnement. Action : un ensemble d'actions qu'un agent peut entreprendre. Fonction de transition : fonction qui prédit la probabilité de transition vers un nouvel état en fonction de l'état et de l'action actuels. Fonction de récompense : fonction qui attribue une récompense à l'agent pour chaque conversion. L'objectif de l'agent est d'apprendre une fonction politique,
2023-10-31
commentaire 0
667

Une méthode pour optimiser l'AB à l'aide de l'apprentissage par renforcement du gradient politique
Présentation de l'article:Les tests AB sont une technique largement utilisée dans les expériences en ligne. Son objectif principal est de comparer deux ou plusieurs versions d'une page ou d'une application afin de déterminer quelle version atteint les meilleurs objectifs commerciaux. Ces objectifs peuvent être des taux de clics, des taux de conversion, etc. En revanche, l’apprentissage par renforcement est une méthode d’apprentissage automatique qui utilise l’apprentissage par essais et erreurs pour optimiser les stratégies de prise de décision. L'apprentissage par renforcement par gradient de politiques est une méthode spéciale d'apprentissage par renforcement qui vise à maximiser les récompenses cumulatives en apprenant des politiques optimales. Les deux ont des applications différentes dans l’optimisation des objectifs commerciaux. Dans les tests AB, nous considérons les différentes versions de page comme différentes actions, et les objectifs commerciaux peuvent être considérés comme des indicateurs importants de signaux de récompense. Afin d'atteindre le maximum d'objectifs commerciaux, nous devons concevoir une stratégie capable de choisir
2024-01-24
commentaire 0
1001
Du transformateur au modèle de diffusion, découvrez les méthodes d'apprentissage par renforcement basées sur la modélisation de séquences dans un seul article
Présentation de l'article:Les modèles génératifs à grande échelle ont apporté d’énormes avancées dans le traitement du langage naturel et même dans la vision par ordinateur au cours des deux dernières années. Récemment, cette tendance a également affecté l'apprentissage par renforcement, notamment l'apprentissage par renforcement hors ligne (offline RL), tel que Decision Transformer (DT)[1], Trajectory Transformer (TT)[2], Gato[3], Diffuser[4], etc. Cette méthode considère les données d'apprentissage par renforcement (y compris le statut, l'action, la récompense et le retour à l'emploi) comme une chaîne de données de séquence déstructurées et modélise ces données de séquence comme la tâche principale de l'apprentissage. Ces modèles peuvent tous utiliser des méthodes d'apprentissage supervisé ou auto-supervisé
2023-04-14
commentaire 0
973

Grimper, sauter et franchir des espaces étroits, des stratégies d'apprentissage par renforcement open source permettent aux chiens robots de faire du parkour
Présentation de l'article:Le parkour est un sport extrême. C'est un énorme défi pour les robots, en particulier les chiens robots à quatre pattes, qui doivent surmonter rapidement divers obstacles dans des environnements complexes. Certaines études ont tenté d'utiliser des données d'animaux de référence ou des récompenses complexes, mais ces approches génèrent des compétences de parkour qui sont soit diverses mais aveugles, soit basées sur la vision mais spécifiques à une scène. Cependant, le parkour autonome nécessite que les robots acquièrent des compétences générales diverses et basées sur la vision pour percevoir divers scénarios et réagir rapidement. Récemment, une vidéo d'un parkour de chien robot est devenue virale. Le chien robot dans la vidéo surmonte rapidement divers obstacles dans divers scénarios. Par exemple, en passant par l'espace sous la plaque de fer, en grimpant sur une caisse en bois, puis en sautant sur une autre caisse en bois, une série d'actions est fluide et fluide : cette série d'actions montre que le chien robot maîtrise ramper, grimper et rampant sur le sol.
2023-09-20
commentaire 0
1099

Guide d'intégration de la technologie d'intelligence artificielle dans la programmation graphique C++
Présentation de l'article:En intégrant la technologie de l'intelligence artificielle dans la programmation graphique C++, les développeurs peuvent créer des applications plus intelligentes et interactives. Ceux-ci incluent la classification d'images, la détection d'objets, la génération d'images, l'IA de jeu, la planification de chemin, la génération de scènes et d'autres fonctions. Les technologies d'intelligence artificielle telles que les réseaux neuronaux, l'apprentissage par renforcement et les réseaux contradictoires génératifs peuvent être intégrées au C++ via des frameworks tels que TensorFlow, OpenAIGym et PyTorch pour réaliser ces fonctions.
2024-06-02
commentaire 0
358

Quels sont les algorithmes d'apprentissage par renforcement en Python ?
Présentation de l'article:Avec le développement de la technologie de l'intelligence artificielle, l'apprentissage par renforcement, en tant que technologie importante de l'intelligence artificielle, a été largement utilisé dans de nombreux domaines, tels que les systèmes de contrôle, les jeux, etc. En tant que langage de programmation populaire, Python permet également la mise en œuvre de nombreux algorithmes d'apprentissage par renforcement. Cet article présentera les algorithmes d'apprentissage par renforcement couramment utilisés et leurs caractéristiques en Python. Q-learningQ-learning est un algorithme d'apprentissage par renforcement basé sur une fonction de valeur. Il guide les stratégies comportementales en apprenant une fonction de valeur, permettant à l'agent de choisir dans l'environnement.
2023-06-04
commentaire 0
1414

Un seul GPU permet une prise de décision en ligne à 20 Hz, une interprétation de la dernière méthode efficace de planification de trajectoire basée sur un modèle de génération de séquences.
Présentation de l'article:Précédemment, nous avons introduit l'application de méthodes de modélisation de séquence basées sur le modèle de transformateur et de diffusion dans l'apprentissage par renforcement, en particulier dans le domaine du contrôle continu hors ligne. Parmi eux, Trajectory Transformer (TT) et Diffusser sont des algorithmes de planification basés sur des modèles. Ils montrent une prédiction de trajectoire de très haute précision et une bonne flexibilité, mais le délai de prise de décision est relativement élevé. En particulier, TT discrétise chaque dimension indépendamment sous forme de symbole dans la séquence, ce qui rend la séquence entière très longue, et le temps de génération de séquence augmente rapidement avec les dimensions des états et des actions.
2023-04-13
commentaire 0
1657

Produit conjointement par Qingbei ! Une enquête pour comprendre les tenants et les aboutissants du 'Transformer+Reinforcement Learning'
Présentation de l'article:Depuis sa sortie, le modèle Transformer est rapidement devenu une architecture neuronale courante dans les contextes d'apprentissage supervisé dans les domaines du traitement du langage naturel et de la vision par ordinateur. Bien que l'engouement pour Transformer ait commencé à se répandre dans le domaine de l'apprentissage par renforcement, en raison des caractéristiques de RL lui-même, telles que le besoin de fonctionnalités uniques, la conception de l'architecture, etc., la combinaison actuelle de Transformer et de l'apprentissage par renforcement n'est pas fluide, et son chemin de développement manque d'articles pertinents pour mener une analyse approfondie. Récemment, des chercheurs de l'Université Tsinghua, de l'Université de Pékin et de Tencent ont publié conjointement un document de recherche sur la combinaison de Transformer et de l'apprentissage par renforcement, examinant systématiquement le processus de motivation et de développement lié à l'utilisation de Transformer dans l'apprentissage par renforcement. papier
2023-04-13
commentaire 0
1123

Nanyang Polytechnic publie le maître de trading quantitatif TradeMaster, couvrant 15 algorithmes d'apprentissage par renforcement
Présentation de l'article:Récemment, la famille des plateformes quantitatives a accueilli un nouveau membre, une plateforme open source basée sur l'apprentissage par renforcement : TradeMaster—Trading Master. Développée par l'Université technologique de Nanyang, TradeMaster est une plateforme de trading quantitative unifiée, de bout en bout et conviviale couvrant quatre principaux marchés financiers, six scénarios de trading majeurs, 15 algorithmes d'apprentissage par renforcement et une série d'outils d'évaluation visuelle ! Adresse de la plateforme : https://github.com/TradeMaster-NTU/TradeMaster Contexte Introduction Ces dernières années, la technologie de l'intelligence artificielle occupe une position de plus en plus importante dans les stratégies de trading quantitatives. En raison de sa capacité décisionnelle exceptionnelle dans des environnements complexes, la technologie d’apprentissage par renforcement est appliquée à
2023-04-11
commentaire 0
1082
La curiosité de l'IA ne tue pas seulement le chat ! Le nouvel algorithme d'apprentissage par renforcement du MIT, cette fois l'agent est 'difficile et facile à tout prendre'
Présentation de l'article:Tout le monde a été confronté à un problème séculaire. Vous essayez de choisir un restaurant où manger un vendredi soir, mais vous n'avez pas de réservation. Devez-vous faire la queue dans votre restaurant préféré qui regorge de monde, ou essayer un nouveau restaurant dans l’espoir de découvrir de plus savoureuses surprises ? Ce dernier point a le potentiel de créer des surprises, mais ce type de comportement motivé par la curiosité comporte des risques : la nourriture du nouveau restaurant que vous essayez pourrait être encore plus savoureuse. La curiosité est le moteur de l’IA pour explorer le monde, et les exemples sont innombrables : navigation autonome, prise de décision des robots, résultats de détection optimisés, etc. Dans certains cas, les machines utilisent « l'apprentissage par renforcement » pour atteindre un objectif dans lequel l'agent d'IA apprend à plusieurs reprises en étant récompensé pour son bon comportement et puni pour son mauvais comportement. Tout comme lorsque les humains choisissent un restaurant
2023-04-13
commentaire 0
998

La boîte noire d'AlphaZero est ouverte ! Article DeepMind publié dans PNAS
Présentation de l'article:Les échecs ont toujours été un terrain d’essai pour l’IA. Il y a 70 ans, Alan Turing émettait l’hypothèse qu’il serait possible de construire une machine à jouer aux échecs capable d’apprendre par elle-même et de s’améliorer continuellement grâce à son expérience. "Deep Blue", apparu au siècle dernier, a vaincu les humains pour la première fois, mais il s'est appuyé sur des experts pour coder les connaissances humaines en matière d'échecs. AlphaZero, né en 2017, a réalisé la conjecture de Turing en tant que machine d'apprentissage par renforcement pilotée par un réseau neuronal. AlphaZero n'a pas besoin d'utiliser d'heuristiques conçues à la main ni de regarder des humains jouer aux échecs, mais est entièrement formé en jouant contre lui-même. Alors, apprend-il vraiment les concepts humains sur les échecs ? Il s’agit d’un problème d’interprétabilité du réseau neuronal. À cet égard, AlphaZero
2023-04-12
commentaire 0
1397
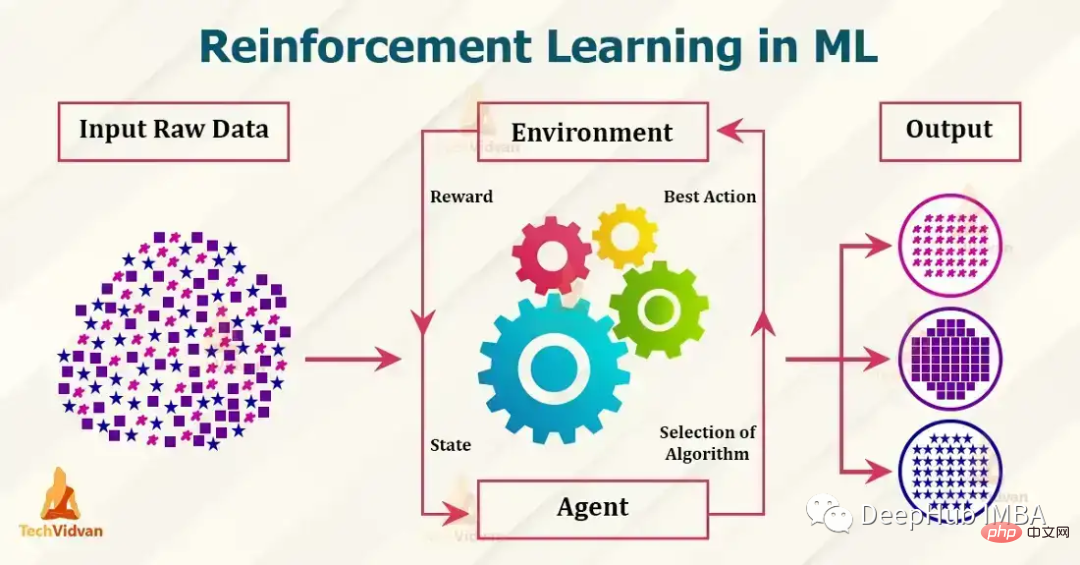
Sept algorithmes d'apprentissage par renforcement et implémentations de code populaires
Présentation de l'article:Les algorithmes d'apprentissage par renforcement actuellement populaires incluent Q-learning, SARSA, DDPG, A2C, PPO, DQN et TRPO. Ces algorithmes ont été utilisés dans diverses applications telles que les jeux, la robotique et la prise de décision, et ces algorithmes populaires sont constamment développés et améliorés. Dans cet article, nous en donnerons une brève introduction. 1. Q-learningQ-learning : Q-learning est un algorithme d'apprentissage par renforcement sans modèle et sans stratégie. Il estime la fonction de valeur d'action optimale à l'aide de l'équation de Bellman, qui met à jour de manière itérative la valeur estimée pour une paire état-action donnée. Q-learning est connu pour sa simplicité et sa capacité à gérer de grands espaces d’états continus.
2023-04-11
commentaire 0
1641

Des souris marchant dans le labyrinthe à AlphaGo battant les humains, le développement de l'apprentissage par renforcement
Présentation de l'article:Lorsqu’il s’agit d’apprentissage par renforcement, l’adrénaline de nombreux chercheurs monte de manière incontrôlable ! Il joue un rôle très important dans les systèmes d’IA de jeu, les robots modernes, les systèmes de conception de puces et d’autres applications. Il existe de nombreux types d'algorithmes d'apprentissage par renforcement, mais ils sont principalement divisés en deux catégories : « basés sur un modèle » et « sans modèle ». Dans une conversation avec TechTalks, le neuroscientifique et auteur de « The Birth of Intelligence » Daeyeol Lee a discuté de différents modèles d'apprentissage par renforcement chez les humains et les animaux, de l'intelligence artificielle et de l'intelligence naturelle, ainsi que des orientations de recherche futures. Apprentissage par renforcement sans modèle À la fin du XIXe siècle, la « loi de l'effet » proposée par le psychologue Edward Thorndike est devenue la base de l'apprentissage par renforcement sans modèle. Ème
2023-05-09
commentaire 0
879
