10000 contenu connexe trouvé

Discuter de l'analyse de la planification d'itinéraire de l'algorithme de recherche de chemin et de la mise en œuvre du code
Présentation de l'article:L'algorithme de recherche de chemin est l'un des algorithmes couramment utilisés dans le domaine de l'infographie et de l'intelligence artificielle, qui permet de calculer le chemin le plus court ou le chemin optimal d'un point à un autre. Dans cet article, je présenterai en détail deux algorithmes de recherche de chemin couramment utilisés : l'algorithme de Dijkstra et l'algorithme A*. L'algorithme de Dijkstra L'algorithme de Dijkstra est un algorithme de recherche en largeur utilisé pour trouver le chemin le plus court entre deux points dans un graphique. Cela fonctionne comme suit : Nous devons créer un ensemble S pour stocker les sommets qui ont trouvé le chemin le plus court. Nous devons créer un ensemble Q pour stocker les sommets qui n'ont pas encore trouvé le chemin le plus court. Lors de l'initialisation du tableau de distance dist, nous devons déplacer le point de départ vers d'autres points. Réglez la distance à l'infini, définissez la distance du point de départ à lui-même sur 0 et répétez les étapes suivantes.
2023-12-20
commentaire 0
766

Comment optimiser l'algorithme de fusion de données dans le développement big data C++ ?
Présentation de l'article:Comment optimiser l'algorithme de fusion de données dans le développement de Big Data C++ ? Introduction : La fusion de données est un problème souvent rencontré dans le développement de Big Data, en particulier lorsqu'il s'agit de deux ou plusieurs ensembles de données triés. En C++, nous pouvons implémenter l'algorithme de fusion de données en utilisant l'idée du tri par fusion. Cependant, lorsque la quantité de données est importante, l’algorithme de fusion peut rencontrer des problèmes d’efficacité. Dans cet article, nous présenterons comment optimiser l'algorithme de fusion de données dans le développement de Big Data C++ pour améliorer l'efficacité opérationnelle. 1. Pour mettre en œuvre l'algorithme commun de fusion de données, nous d'abord
2023-08-27
commentaire 0
944

Combat réel LightGBM + réglage des paramètres de recherche aléatoire : taux de précision 96,67 %
Présentation de l'article:Bonjour à tous, je m'appelle Peter~LightGBM est un algorithme d'apprentissage automatique classique. Son contexte, ses principes et ses caractéristiques méritent d'être étudiés. L'algorithme de LightGBM offre des fonctionnalités telles que l'efficacité, l'évolutivité et une grande précision. Cet article présentera brièvement les caractéristiques et principes de LightGBM ainsi que quelques cas basés sur LightGBM et l'optimisation de la recherche aléatoire. Algorithme LightGBM Dans le domaine de l'apprentissage automatique, les machines à amplification de gradient (GBM) sont une classe d'algorithmes d'apprentissage d'ensemble puissants qui construisent un modèle puissant en ajoutant progressivement des apprenants faibles (généralement des arbres de décision) pour minimiser les erreurs de prédiction. Les GBM sont souvent utilisés pour minimiser les pré-
2024-06-08
commentaire 0
712

Implémentation d'algorithmes parallèles hautes performances en programmation concurrente C++ ?
Présentation de l'article:Réponse : Pour implémenter des algorithmes parallèles simultanés en C++, vous pouvez utiliser des bibliothèques de concurrence C++ (telles que std::thread, std::mutex) et utiliser des algorithmes parallèles (tri par fusion, tri rapide, MapReduce) pour améliorer les performances. Description détaillée : La bibliothèque de concurrence C++ fournit des mécanismes de gestion et de synchronisation des threads, tels que std::thread, std::mutex, std::condition_variable. Les algorithmes parallèles améliorent les performances en distribuant les tâches à plusieurs threads s'exécutant simultanément. Cas pratique : le tri par fusion parallèle est un algorithme récursif classique parallélisé qui peut trier et fusionner les résultats en segments pour améliorer l'efficacité du traitement de grands ensembles de données.
2024-06-03
commentaire 0
554

Le réseau neuronal graphique a été publié dans une sous-revue Nature, mais il a été révélé qu'il était 104 fois plus lent que l'algorithme ordinaire. Questionneurs : est-ce une nouvelle hauteur ?
Présentation de l'article:GNN est un domaine très populaire ces dernières années. Récemment, un article de la sous-revue Nature a proposé une méthode pour utiliser GNN pour résoudre des problèmes d'optimisation combinatoire et a affirmé que les performances de l'optimiseur GNN sont équivalentes, voire supérieures, aux solveurs existants. Cependant, cet article a suscité quelques doutes : certaines personnes ont souligné que les performances de ce GNN ne sont en réalité pas aussi bonnes que celles de l'algorithme glouton classique, et que la vitesse est beaucoup plus lente que l'algorithme glouton (pour les problèmes avec un million de variables, l'algorithme glouton l'algorithme est meilleur que le GNN 104 fois plus rapide). Alors les sceptiques disent : « Nous ne voyons aucune bonne raison d’utiliser ces GNN pour résoudre ce problème, c’est comme utiliser un marteau pour casser des noix. » Ils espèrent que les auteurs de ces articles pourront affirmer que la méthode est supérieure.
2023-04-12
commentaire 0
1126

Python implémente 12 algorithmes de réduction de dimensionnalité
Présentation de l'article:Bonjour à tous, je m'appelle Peter~ Les informations sur les différents algorithmes de réduction de dimensionnalité sur Internet sont mitigées et la plupart d'entre eux ne fournissent pas de code source. Voici un projet GitHub qui utilise Python pour implémenter 11 algorithmes classiques d'extraction de données (réduction de la dimensionnalité des données), notamment : PCA, LDA, MDS, LLE, TSNE, etc., avec des informations et des effets d'affichage pertinents très adaptés aux débutants et aux apprenants automatiques ; ceux qui viennent de commencer le data mining. Pourquoi devons-nous effectuer une réduction de dimensionnalité des données ? La soi-disant réduction de dimensionnalité consiste à utiliser un ensemble de vecteurs Zi avec un nombre d pour représenter les informations utiles contenues dans un certain nombre de vecteurs Xi avec un nombre D, où d est généralement , nous constaterons que les dimensions de la plupart des ensembles de données atteindront des centaines, voire des milliers, et le classique
2023-04-12
commentaire 0
1739

L'importance de l'asymptotisme dans les problèmes d'apprentissage automatique
Présentation de l'article:La propriété asymptotique indique si les performances de l'algorithme se stabiliseront ou convergeront vers une certaine limite à mesure que la quantité de données augmente. Dans les problèmes d’apprentissage automatique, les propriétés asymptotiques sont des indicateurs importants pour évaluer l’évolutivité et l’efficacité des algorithmes. Comprendre les propriétés asymptotiques des algorithmes nous aide à choisir des algorithmes appropriés pour résoudre les problèmes d'apprentissage automatique. En analysant les performances de l'algorithme sous différentes quantités de données, nous pouvons prédire l'efficacité et les performances de l'algorithme sur des ensembles de données à grande échelle. Ceci est très important pour les problèmes pratiques liés au traitement d’ensembles de données à grande échelle. Par conséquent, comprendre les propriétés asymptotiques des algorithmes peut nous aider à prendre des décisions plus éclairées dans des applications pratiques. Il existe de nombreux algorithmes d'apprentissage automatique courants, tels que les machines à vecteurs de support, les Bayes naïfs, les arbres de décision et les réseaux de neurones. Chaque algorithme a ses propres avantages et inconvénients, il y a donc des facteurs à prendre en compte lors du choix
2024-01-24
commentaire 0
892
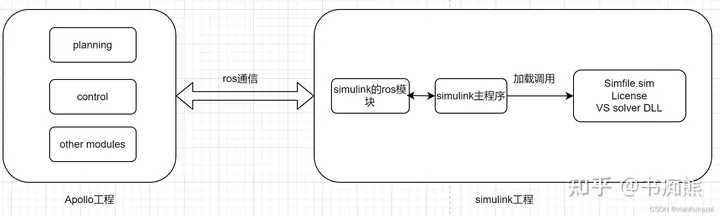
Apollo s'associe à Carsim/TruckSim pour une simulation conjointe
Présentation de l'article:1. La simulation d’arrière-plan joue un rôle important dans la recherche et le développement en matière de conduite autonome. Elle peut considérablement améliorer l’efficacité de la recherche et du développement et garantir la fiabilité des algorithmes. En tant qu'excellente plate-forme open source, le système Baidu Apollo est très adapté aux recherches d'amis intéressés par l'apprentissage de la conduite autonome. De plus, Carsim/Trucksim est un outil de simulation de dynamique de véhicule classique très respecté. Cet article présente la méthode de réalisation d'une simulation locale en temps réel grâce à la combinaison d'Apollo et de Trucksim. Il convient aux débutants pour construire une plateforme de simulation et étudier le système Apollo. 2. Conception de l'architecture Le code principal du projet Apollo est implémenté en C++. Les interfaces courantes pour Trucksim incluent simulink, Python et le langage C.
2024-01-13
commentaire 0
1275

Optimisation de l'algorithme de compression Gzip à l'aide du cache Memcache en PHP
Présentation de l'article:À mesure que la technologie réseau se développe de plus en plus, le nombre de visites sur les sites Web augmente progressivement. Afin d'améliorer l'expérience utilisateur, nous devons réduire autant que possible le temps de chargement des pages Web et la taille des données transmises. Parmi eux, l'algorithme de compression Gzip est un algorithme de compression de données classique qui peut compresser les données lors de la transmission des données et réduire la taille des données transmises, améliorant ainsi la vitesse de chargement des pages Web et l'expérience utilisateur. Lorsque nous utilisons l'algorithme de compression Gzip pour optimiser le site Web, nous pouvons également le combiner avec la technologie de mise en cache Memcache en PHP pour améliorer encore les performances du site Web. 1.G
2023-05-15
commentaire 0
808

Présentation des algorithmes courants et de leur popularité dans l'apprentissage automatique des graphes (GML)
Présentation de l'article:L'apprentissage automatique graphique (GML) est un domaine en croissance rapide qui combine l'apprentissage automatique et la représentation graphique des données. La représentation graphique des données fait des graphiques un outil puissant pour modéliser des systèmes complexes. Grâce à des graphiques, nous sommes capables de capturer les relations et les interactions entre différentes entités. Cet article découvrira les avantages de l'apprentissage automatique graphique par rapport aux méthodes traditionnelles, ainsi que plusieurs algorithmes d'apprentissage automatique graphique populaires. Avantages de l'apprentissage automatique graphique par rapport aux méthodes traditionnelles L'apprentissage automatique graphique (GML) est souvent considéré comme supérieur à l'apprentissage automatique classique pour plusieurs raisons : Les algorithmes GML sont conçus pour exploiter la manière naturelle dont les graphiques gèrent des relations complexes qui peuvent être difficiles ou ne peuvent pas être représentées par les méthodes traditionnelles. . L'algorithme GML fait preuve de robustesse face aux données manquantes et est capable d'extraire des informations significatives. 3. Traitez des données à grande échelle
2024-01-23
commentaire 0
1395

Comment implémenter l'algorithme du problème du sac à dos en utilisant PHP
Présentation de l'article:Comment utiliser PHP pour implémenter l'algorithme du problème du sac à dos. Le problème du sac à dos est un problème d'optimisation combinatoire classique. Son objectif est de sélectionner un ensemble d'éléments pour maximiser leur valeur totale dans une capacité de sac à dos limitée. Dans cet article, nous présenterons comment utiliser PHP pour implémenter l'algorithme du problème du sac à dos et fournirons des exemples de code correspondants. Description du problème du sac à dos Le problème du sac à dos peut être décrit de la manière suivante : étant donné un sac à dos d'une capacité C et N articles. Chaque élément i a un poids wi et une valeur vi. Il est nécessaire de sélectionner certains éléments parmi ces N éléments de telle sorte qu'ils
2023-07-09
commentaire 0
1506

Utilisez Webman pour optimiser et traiter les images sur les sites Web
Présentation de l'article:Utiliser Webman pour optimiser et traiter les images sur les sites Web À l'ère d'Internet d'aujourd'hui, l'application d'images dans les pages Web est devenue de plus en plus importante. L’esthétique et la vitesse de chargement des pages sont indissociables de l’optimisation et du traitement des images. Cet article expliquera comment utiliser Webman, un outil puissant, pour optimiser et traiter les images sur le site Web afin d'améliorer l'expérience utilisateur et les performances des pages. Webman est un outil de traitement d'image basé sur Python. Il combine une variété d'excellents algorithmes de traitement d'image et techniques d'optimisation pour m'aider.
2023-08-25
commentaire 0
1019

Comment utiliser le backtracking pour parvenir à une solution efficace au problème de permutation complète en PHP ?
Présentation de l'article:Comment utiliser le backtracking pour parvenir à une solution efficace au problème de permutation complète en PHP ? La méthode de backtracking est un algorithme couramment utilisé pour résoudre des problèmes de permutation et de combinaison, et peut rechercher toutes les solutions possibles dans un temps limité. En PHP, nous pouvons utiliser le backtracking pour résoudre le problème de permutation complète et trouver une solution efficace. Le problème de permutation totale est un problème classique de permutation et de combinaison, dont le but est de trouver toutes les permutations possibles étant donné un ensemble d'éléments différents. Par exemple, pour l'ensemble d'éléments {1,2,3}, tous les arrangements possibles sont {1,
2023-09-19
commentaire 0
1283
Illustration des dix algorithmes d'apprentissage automatique les plus couramment utilisés !
Présentation de l'article:Dans le domaine de l'apprentissage automatique, il existe un dicton intitulé « Il n'y a pas de repas gratuit dans le monde ». En bref, cela signifie qu'aucun algorithme ne peut avoir le meilleur effet sur chaque problème. Cette théorie est très importante dans l'apprentissage supervisé. particulièrement important. Par exemple, on ne peut pas dire que les réseaux de neurones sont toujours meilleurs que les arbres de décision, ou vice versa. L'exécution du modèle est influencée par de nombreux facteurs, tels que la taille et la structure de l'ensemble de données. Par conséquent, vous devez essayer de nombreux algorithmes différents en fonction de votre problème, tout en utilisant un ensemble de données de test pour évaluer les performances et choisir le meilleur. Bien entendu, l’algorithme que vous essayez doit être pertinent par rapport à votre problème, et la clé est la tâche principale de l’apprentissage automatique. Par exemple, si vous souhaitez nettoyer votre maison, vous pouvez utiliser un aspirateur, un balai ou une vadrouille, mais vous n'utiliserez certainement pas de pelle.
2023-04-12
commentaire 0
1499

Comment résoudre le problème du spanning tree minimum en PHP en utilisant la méthode diviser pour régner et obtenir la solution optimale ?
Présentation de l'article:Comment résoudre le problème du spanning tree minimum en PHP en utilisant la méthode diviser pour régner et obtenir la solution optimale ? L'arbre couvrant minimum est un problème classique de la théorie des graphes, qui vise à trouver un sous-ensemble de tous les sommets d'un graphe connecté et à relier les arêtes de sorte que le sous-ensemble forme un arbre et que la somme des poids de toutes les arêtes soit la plus petite. La méthode diviser pour régner est une idée consistant à décomposer un gros problème en plusieurs sous-problèmes, puis à résoudre les sous-problèmes un par un et enfin à fusionner les résultats. L’utilisation de la méthode diviser pour régner pour résoudre le problème du spanning tree minimum en PHP peut être réalisée en suivant les étapes suivantes. Définissez la structure des données du graphique :
2023-09-19
commentaire 0
907

Exemples pour expliquer comment utiliser PHP pour obtenir un arrangement complet
Présentation de l'article:Implémentation de la permutation complète PHP En informatique, une permutation complète est une permutation et une combinaison différente de tous les éléments d'un ensemble. Le problème de permutation totale est un problème d'algorithme classique qui peut être utilisé non seulement en mathématiques et en informatique, mais également dans d'autres domaines, tels que la cryptographie, la bioinformatique et le commerce électronique. La mise en œuvre d'une permutation complète en PHP nécessite l'utilisation de méthodes et de techniques récursives pour échanger des éléments. Ci-dessous, nous expliquerons en détail comment utiliser PHP pour obtenir un arrangement complet. Tout d'abord, nous devons définir une fonction pour implémenter l'opération d'arrangement complet. Cette fonction doit recevoir deux paramètres. Le premier paramètre est la valeur à organiser.
2023-04-04
commentaire 0
791

Comment résoudre le problème du sac à dos en PHP en utilisant un algorithme de programmation dynamique et obtenir une solution optimale ?
Présentation de l'article:Comment résoudre le problème du sac à dos en PHP en utilisant un algorithme de programmation dynamique et obtenir une solution optimale ? Le problème du sac à dos est l’un des problèmes d’optimisation combinatoire classiques en informatique. Étant donné un ensemble d'articles et la capacité d'un sac à dos, la manière de sélectionner les articles à mettre dans le sac à dos afin de maximiser la valeur totale des articles dans le sac à dos est au cœur du problème du sac à dos qui doit être résolu. La programmation dynamique est l'une des méthodes courantes pour résoudre le problème du sac à dos. Il obtient finalement la solution optimale en divisant le problème en sous-problèmes et en enregistrant les solutions des sous-problèmes. Ci-dessous, nous expliquerons en détail comment utiliser l'algorithme de programmation dynamique en PHP
2023-09-21
commentaire 0
1353

Comment les entreprises peuvent faire passer l'intelligence artificielle au niveau supérieur
Présentation de l'article:Les entreprises obtiennent de plus en plus un avantage concurrentiel en déployant l’intelligence artificielle à l’aide d’architectures cloud hybrides distribuées. Cela est dû à deux facteurs : premièrement, davantage de données sont générées en périphérie que jamais auparavant. En fait, on prévoit que d’ici 2025, 50 % des données générées par les entreprises seront traitées en dehors des centres de données traditionnels ou du cloud computing. Une récente enquête mondiale a révélé que 78 % des décideurs informatiques estiment que la transition de l'infrastructure informatique vers la périphérie numérique est une priorité d'avenir pour leur entreprise. Deuxièmement, le déplacement de grandes quantités de données vers des moteurs d’infrastructure de formation en IA centralisés pour le traitement signifie que les entreprises consacreront un temps et des dépenses précieux. En outre, les réglementations en matière de conformité et de confidentialité exigent souvent que le traitement et l'analyse des données d'IA soient conservés dans le pays d'origine, ce qui
2023-04-14
commentaire 0
1629

En se concentrant sur le domaine de l'intelligence artificielle, cette entreprise de Pudong prépare l'industrie de la navigation mobile autonome par robot.
Présentation de l'article:En tant que haut lieu de l'intelligence artificielle dans le pays, Pudong réalise des percées dans de nombreux domaines et accélère son avance. À l'heure actuelle, l'industrie de l'intelligence artificielle à Pudong montre une tendance à se rassembler et à se développer. Dans ce domaine en développement rapide, Silan Technology développe l'industrie de la navigation mobile autonome par robot à Zhangjiang en adoptant une disposition « un horizontal et trois verticaux ». En termes de technologie, nous continuons à mettre à niveau la technologie de manière itérative sur la base d'applications de scénarios ; en termes de produits, nous continuons à faire des percées pour fournir des produits stables et fiables pour le marché ; en termes de fabrication, nous utilisons la fabrication intelligente pour permettre la mise à niveau des lignes de production ; ; en termes de modèles commerciaux, nous adoptons un modèle de coopération flexible pour promouvoir le développement écologique. Après dix ans de recherche et de développement, Silan Technology a accumulé une grande quantité de données de scène, des modèles d'algorithmes continuellement affinés de manière itérative, et ses produits connectés sont devenus de plus en plus abondante. Maintenant nous nous sommes battus
2023-10-30
commentaire 0
1143

Structures de données PHP SPL : libérer le potentiel des opérations de données
Présentation de l'article:Explorez les avantages des structures de données PHPSPL La bibliothèque de structures de données phpSPL (Standard PHP Library) est un trésor de structures de données prédéfinies telles que des tableaux, des files d'attente, des piles et des ensembles qui aident à simplifier et à gérer efficacement les données. Grâce à ces structures, les développeurs peuvent : Améliorer l'efficacité de la gestion des données : les structures de données SPL fournissent des interfaces cohérentes et des algorithmes d'optimisation qui simplifient le stockage, la récupération et la manipulation des données. Lisibilité améliorée du code : grâce à des structures standardisées, le code devient plus facile à comprendre et à maintenir, améliorant ainsi l'efficacité du développement. Performances améliorées : les structures de données SPL sont optimisées pour gérer efficacement de grandes quantités de données, améliorant ainsi les performances globales de votre application. Types de structures de données SPL La bibliothèque de structures de données SPL couvre un large éventail de structures de données
2024-02-19
commentaire 0
1141
