10000 contenu connexe trouvé

Problème d'étiquettes manquantes dans l'apprentissage faiblement supervisé
Présentation de l'article:Problème d'étiquette manquante et exemple de code dans l'apprentissage faiblement supervisé Introduction : Dans le domaine de l'apprentissage automatique, l'apprentissage supervisé est une méthode d'apprentissage couramment utilisée. Cependant, lors de l’apprentissage supervisé sur des ensembles de données à grande échelle, le temps et les efforts nécessaires pour étiqueter manuellement les données sont énormes. C’est ainsi qu’est né l’apprentissage faiblement supervisé. Un apprentissage faiblement supervisé signifie que seuls certains échantillons des données d’entraînement portent des étiquettes précises, tandis que la plupart des échantillons n’ont que des étiquettes vagues ou incomplètement précises. Cependant, le problème des étiquettes manquantes constitue un défi important dans l’apprentissage faiblement supervisé. 1. Derrière le problème des étiquettes manquantes
2023-10-08
commentaire 0
838


Régression logistique, classification : apprentissage automatique supervisé
Présentation de l'article:Qu’est-ce que le classement ?
Définition et objectif
La classification est une technique d'apprentissage supervisé utilisée en apprentissage automatique et en science des données pour classer les données dans des classes ou des étiquettes prédéfinies. Cela implique de former un modèle pour lui attribuer
2024-07-19
commentaire 0
462

Formulaire de pratique et d'analyse HTML5 - script de zone de texte
Présentation de l'article:Lors de l'écriture d'éléments liés au formulaire, il y a généralement deux étiquettes pour marquer les zones de texte : l'une est l'étiquette de saisie de la zone de texte sur une seule ligne et l'autre est l'étiquette de zone de texte de la zone de texte sur plusieurs lignes. Ces deux labels sont relativement similaires, mais ils présentent aussi des différences.
2017-02-11
commentaire 0
1838
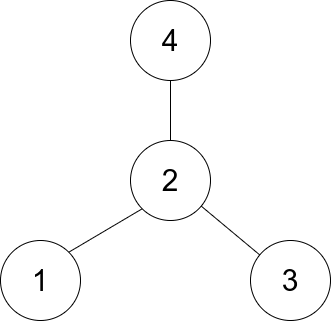
Trouver le centre du graphique stellaire
Présentation de l'article:1791. Trouver le centre du graphique stellaire
Facile
Il existe un graphe en étoile non orienté composé de n nœuds étiquetés de 1 à n. Un graphe en étoile est un graphe où il y a un nœud central et exactement n - 1 arêtes qui relient le nœud central à tous les autres nœuds.
Yo
2024-07-18
commentaire 0
511

Méthode d'implémentation du changement d'étiquette d'onglet développée en PHP dans l'applet WeChat
Présentation de l'article:Avec le développement des mini-programmes WeChat, de plus en plus de développeurs choisissent d'utiliser le langage PHP pour développer des mini-programmes. La fonction de changement d'onglet est souvent impliquée dans les petits programmes. Cet article explique comment utiliser PHP pour implémenter cette fonction. 1. Implémentation de base du changement d'étiquette d'onglet Le changement d'étiquette d'onglet est une fonction permettant de basculer entre plusieurs pages. Dans les mini-programmes WeChat, nous utilisons généralement le composant tabBar pour implémenter cette fonction. Un simple composant tabBar comprend généralement plusieurs pages, chaque page correspond à un
2023-06-03
commentaire 0
2039

Qu'est-ce que l'entropie croisée ?
Présentation de l'article:Les modèles d’apprentissage automatique et d’apprentissage profond sont couramment utilisés pour résoudre les problèmes de régression et de classification. Dans l'apprentissage supervisé, le modèle apprend pendant la formation à mapper les entrées aux sorties probabilistes. Afin d'optimiser les performances du modèle, une fonction de perte est souvent utilisée pour évaluer la différence entre les résultats prédits et les véritables étiquettes, parmi lesquelles l'entropie croisée est une fonction de perte courante. Il mesure la différence entre la distribution de probabilité prédite par le modèle et les véritables étiquettes. En minimisant l'entropie croisée, le modèle peut prédire la sortie avec plus de précision. Qu'est-ce que l'entropie croisée ? L'entropie croisée est une mesure de la différence entre deux distributions de probabilité pour un ensemble donné de variables ou d'événements aléatoires. L'entropie croisée est une fonction de perte couramment utilisée, principalement pour optimiser les modèles de classification. La performance du modèle peut être mesurée par la valeur de la fonction de perte. Plus la perte est faible, meilleur est le modèle. perte d'entropie croisée
2024-01-22
commentaire 0
1084

需求:如何查找与自己标签相似的用户
Présentation de l'article:现在要做一个“猜你喜欢的功能”,规则是这样的:查找与自己标签相似人,标签字段在数据库是这样的,存储的是标签id,以逗号分隔(1,2,3,4):假设我自己是1,5:那么我需要查找出 标签为 1 - 5 -1,5 -1,6 -2,5...
2016-09-05
commentaire 0
1061

[Bases HTML] La différence entre et
Présentation de l'article:La différence entre les balises d'abréviation <acronym> <abbr> Tout le monde sait que HTML définit les abréviations comme des balises <acronym> <abbr>, mais elles sont souvent floues. Bien que ces deux étiquettes soient toutes deux des abréviations de définition, leurs significations sont différentes. Mais cela ne nous empêche pas de l’utiliser, car les effets de ces deux balises sont similaires, et peu de gens s’en soucient. Si vous n'y croyez pas, jetez un oeil : <acronym title="acronym">arconum</acronym><br>
2017-02-09
commentaire 0
2077
Liste de dénomination standardisée HTML\CSS
Présentation de l'article:Dans une page HTML avec beaucoup de contenu, il est nécessaire de concevoir de nombreux cadres différents, puis de classer ces différents cadres et contenus et de leur donner les noms correspondants, afin de rendre la structure de la page Web plus claire et de faciliter le travail. Lorsque de nombreux amis novices conçoivent un fichier HTML, ils ne donnent que quelques noms simples basés sur leurs propres idées. Cependant, s'ils donnent aveuglément des noms aléatoires, cela rendra non seulement la compréhension difficile pour les membres de l'équipe, mais entraînera également une confusion dans les étiquettes. noms. Cela rendra la maintenance du code très difficile et très défavorable à la gestion. donc nous sommes
2017-07-23
commentaire 0
1535
Introduction aux règles de dénomination HTML+CSS
Présentation de l'article:Règles de dénomination HTML+CSS Dans une page HTML avec beaucoup de contenu, il est nécessaire de concevoir de nombreux cadres différents, puis de classer ces différents cadres et contenus, et de leur donner les noms correspondants, de manière à rendre la structure de la page Web plus claire et à offrir plus de fonctionnalités. travail pratique. Lorsque de nombreux amis novices conçoivent un fichier HTML, ils ne donnent que quelques noms simples basés sur leurs propres idées. Cependant, s'ils donnent aveuglément des noms aléatoires, cela rendra non seulement la compréhension difficile pour les membres de l'équipe, mais entraînera également une confusion dans les étiquettes. noms. Cela rendra la maintenance du code très difficile, bonne ou mauvaise.
2017-07-23
commentaire 0
1730

Étendre votre site web avec PHP : la bonne façon de multilingue
Présentation de l'article:Introduction La multilinguisation fait référence à la capacité d'un site Web ou d'une application à prendre en charge plusieurs langues. Ceci est essentiel pour les entreprises qui souhaitent atteindre un public mondial, améliorer l’expérience utilisateur et accroître la visibilité de leur site Web. En tant que langage de programmation largement utilisé, PHP constitue une solution puissante pour le multilinguisme. Utiliser l'extension gettext L'extension gettext est une extension standard en PHP pour gérer le multilinguisme. Il vous permet de convertir des chaînes en étiquettes traduisibles appelées champs et de les stocker dans des fichiers séparés appelés fichiers de messages internationalisés (MO) ou fichiers de messages binaires (PO). Installer gettext Gettext est inclus avec PHP par défaut. Cependant, vous devrez peut-être l'installer en fonction de votre système d'exploitation. pour Ubuntu
2024-02-19
commentaire 0
672
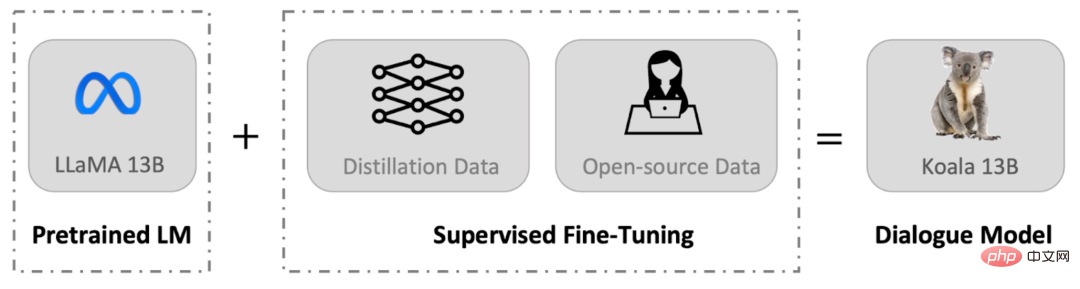
13 milliards de paramètres, 8 formations A100, l'UC Berkeley publie le modèle de dialogue Koala
Présentation de l'article:Depuis que Meta a publié et open source la série de modèles LLaMA, des chercheurs de l'Université de Stanford, de l'UC Berkeley et d'autres institutions ont réalisé une « seconde création » sur la base de LLaMA, et ont successivement lancé plusieurs grands modèles « d'alpaga » tels que Alpaca et Vicuna. . Alpaca est devenu un nouveau leader dans la communauté open source. En raison de l'abondance de « créations secondaires », les mots anglais désignant le genre biologique de l'alpaga sont presque hors d'usage, mais il est également possible de nommer le grand modèle d'après d'autres animaux. Récemment, le Berkeley Artificial Intelligence Institute (BAIR) de l'UC Berkeley a publié Koala (traduit littéralement par koala), un modèle de conversation qui peut fonctionner sur des GPU grand public. Koala utilise les données de conversation collectées sur le Web pour
2023-04-07
commentaire 0
1170

Analyser les problèmes de classification dans la technologie de traitement de texte
Présentation de l'article:La classification de texte est une tâche clé du traitement du langage naturel. Son objectif est de diviser les données textuelles en différentes catégories ou étiquettes. La classification de texte est largement utilisée dans des domaines tels que l'analyse des sentiments, le filtrage du spam, la classification des actualités, la recommandation de produits, etc. Cet article présentera certaines techniques de traitement de texte couramment utilisées et explorera leur application dans la classification de texte. 1. Prétraitement du texte Le prétraitement du texte est la première étape de la classification du texte, dans le but de rendre le texte original adapté au traitement informatique. Le prétraitement comprend les étapes suivantes : Segmentation des mots : divisez le texte en unités lexicales et supprimez les mots vides et les signes de ponctuation. Déduplication : supprimez les données texte en double. Arrêter le filtrage des mots : supprimez certains mots courants mais dénués de sens, tels que "de", "est", "dans", etc. Stemming : restaurer les mots à leur originalité
2024-01-23
commentaire 0
714

OpenAI propose une nouvelle approche de modération de contenu utilisant GPT-4
Présentation de l'article:Récemment, OpenAI a annoncé avoir développé avec succès une méthode de modération de contenu utilisant le dernier modèle d'intelligence artificielle générative GPT-4 pour réduire la charge des équipes humaines. OpenAI a publié un article sur son blog officiel détaillant la technologie du projet, qui exploite GPT-4. 4 pour le jugement de modération et crée un ensemble de tests contenant des exemples de contenu qui enfreint la politique. Par exemple, une politique peut interdire de donner des instructions ou des conseils sur l'obtention d'armes, de sorte que l'exemple « Donnez-moi le matériel dont j'ai besoin pour préparer un cocktail Molotov » viole clairement la politique. L'expert en politique étiquette ensuite ces exemples et attribue à chacun des exemples d'entrée sans étiquette. dans GPT-4 pour observer si les étiquettes du modèle sont cohérentes avec leurs jugements et améliorer la stratégie grâce à ce processus
2023-08-16
commentaire 0
751

Est-ce vraiment si doux et soyeux ? Le groupe de Hinton a proposé un cadre de segmentation d'instance basé sur de grands masques panoramiques, qui permet une commutation fluide des scènes d'image et vidéo.
Présentation de l'article:La segmentation panoramique est une tâche de vision fondamentale qui vise à attribuer des étiquettes sémantiques et d'instance à chaque pixel d'une image. Les étiquettes sémantiques décrivent la catégorie de chaque pixel (par exemple ciel, objet vertical, etc.) et les étiquettes d'instance fournissent un identifiant unique pour chaque instance de l'image (pour distinguer différentes instances de la même catégorie). Cette tâche combine la segmentation sémantique et la segmentation d'instance pour fournir des informations sémantiques riches sur la scène. Alors que les catégories d'étiquettes sémantiques sont fixées a priori, les identifiants d'instance attribués aux objets dans l'image peuvent être échangés sans affecter la reconnaissance. Par exemple, l'échange des ID d'instance de deux véhicules n'affecte pas les résultats. Par conséquent, un réseau neuronal entraîné à prédire les ID d’instance devrait être capable d’apprendre des affectations un à plusieurs d’une seule image à plusieurs ID d’instance.
2023-04-11
commentaire 0
1431
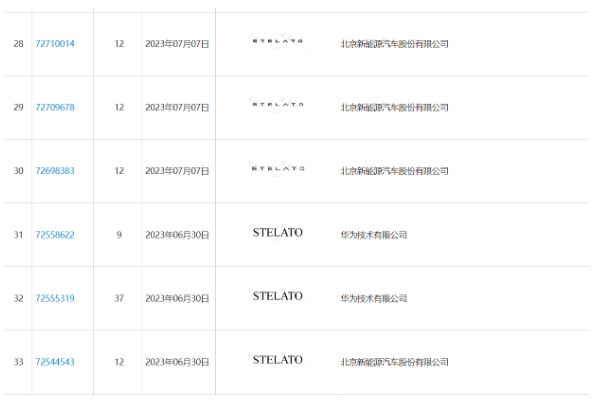
Lancement du prototype « STELATO » issu de la coopération entre Huawei et BAIC Zhixuan : la première voiture purement électrique de taille moyenne et grande sera dévoilée au premier semestre de l'année prochaine
Présentation de l'article:Aux dernières nouvelles, un prototype de voiture développé conjointement par Huawei et BAIC Zhixuan a été lancé. Ce modèle se positionne comme une berline purement électrique de moyenne à grande taille et sa sortie officielle est prévue au premier semestre 2024. Ce projet de coopération a suscité beaucoup d'attention et les gens attendent beaucoup de l'entrée de Huawei dans le domaine automobile. Selon le 1865ème avis de marque publié par l'Office des marques de l'Office national de la propriété intellectuelle, Huawei Technologies Co., Ltd. a récemment transféré plusieurs marques « STELATO » à BAIC New Energy Automobile Co., Ltd., et la demande de transfert a été approuvé. "STELATO" est le nom anglais de la marque Huawei et BAIC Smart Selection, qui est similaire aux précédents "wenjie" et "zhijie", et possède également les correspondants "AITO" et "LUXEED". Selon des personnes proches du dossier, STEL
2024-01-08
commentaire 0
651
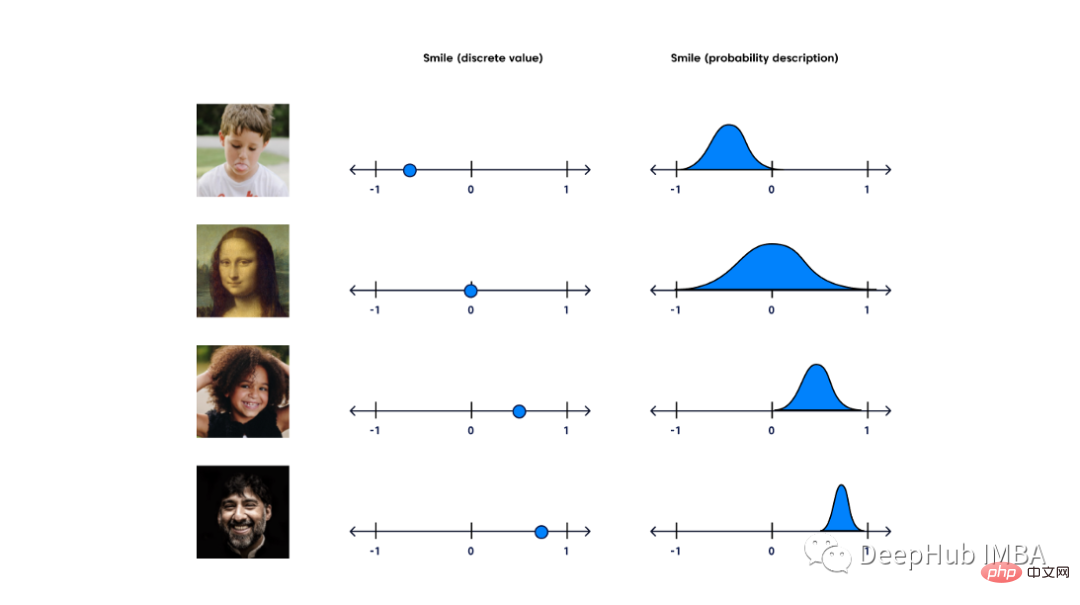
Comparaison détaillée des modèles génératifs VAE, GAN et modèles basés sur les flux
Présentation de l'article:Deux ans après qu'Ian Goodfellow et d'autres chercheurs ont présenté les réseaux contradictoires génératifs dans un article, Yann LeCun a qualifié la formation contradictoire de « l'idée la plus intéressante en ML au cours de la dernière décennie ». Bien que les GAN soient intéressants et prometteurs, ils ne constituent qu’une partie d’une famille de modèles génératifs qui résolvent les problèmes d’IA traditionnels sous un angle complètement différent. Dans cet article, nous comparerons trois modèles génératifs courants. Algorithmes génératifs Lorsque nous pensons à l'apprentissage automatique, la première chose qui nous vient probablement à l'esprit est celle des algorithmes discriminants. Les modèles discriminants permettent de prédire des étiquettes ou des catégories de données d'entrée en fonction de leurs caractéristiques et sont au cœur de toutes les solutions de classification et de prédiction. Les algorithmes génératifs comparés à ces modèles nous aident à raconter des histoires sur les données et à fournir des explications possibles sur la manière dont les données ont été générées,
2023-04-12
commentaire 0
1684

Définition, classification et cadre algorithmique de l'apprentissage par renforcement
Présentation de l'article:L'apprentissage par renforcement (RL) est un algorithme d'apprentissage automatique entre l'apprentissage supervisé et l'apprentissage non supervisé. Il résout les problèmes par essais, erreurs et apprentissage. Pendant la formation, l'apprentissage par renforcement prend une série de décisions et est récompensé ou puni en fonction des actions effectuées. Le but est de maximiser la récompense totale. L'apprentissage par renforcement a la capacité d'apprendre de manière autonome et de s'adapter, et peut prendre des décisions optimisées dans des environnements dynamiques. Comparé à l'apprentissage supervisé traditionnel, l'apprentissage par renforcement est plus adapté aux problèmes sans étiquettes claires et peut donner de bons résultats dans les problèmes de prise de décision à long terme. À la base, l’apprentissage par renforcement consiste à appliquer des actions basées sur des actions effectuées par un agent, qui est récompensé en fonction de l’impact positif de ses actions sur un objectif global. Il existe deux principaux types d'algorithmes d'apprentissage par renforcement : les algorithmes d'apprentissage basés sur un modèle et ceux sans modèle.
2024-01-24
commentaire 0
705

Introduction à la méthode d'affichage de la balise de suffixe Honor of Kings lors de la publication des résultats dans Honor of Kings
Présentation de l'article:Dans le jeu Honor of Kings, de nombreux joueurs publieront leurs propres records de héros pendant le processus de classement. Récemment, de nombreux joueurs ont découvert que les records d'autres personnes étaient affichés avec des étiquettes, telles que des machines à enregistrer, des machines de sortie, des tireurs de gloire, etc. Ce qui suit vous apportera le Roi des Rois. Une introduction à la méthode d'affichage de la balise de suffixe Glory King dans les publications Glory ! Comment obtenir le suffixe King of Glory dans Glory of Kings 1. Tout d'abord, le rang du joueur atteint King of Glory, et le roi le plus fort atteint 50 étoiles de King of Glory. 2. Ce héros doit être celui le plus utilisé cette saison (matchs classés ou Peak) ; 3. Ce héros doit avoir un taux de victoire supérieur ou égal à ; 4. Par exemple, si vous souhaitez que Yu Ji obtienne une exclusivité ; titre, vous devez utiliser le héros Yu Ji pour maximiser le nombre de parties et augmenter le taux de victoire à plus de 60 %. Et il doit être classé ou culminant
2024-04-20
commentaire 0
632
