10000 contenu connexe trouvé

Comment utiliser le langage Go pour mener des recherches sur l'apprentissage par renforcement profond ?
Présentation de l'article:L'apprentissage par renforcement profond (DeepReinforcementLearning) est une technologie avancée qui combine l'apprentissage en profondeur et l'apprentissage par renforcement. Elle est largement utilisée dans la reconnaissance vocale, la reconnaissance d'images, le traitement du langage naturel et d'autres domaines. En tant que langage de programmation rapide, efficace et fiable, le langage Go peut apporter une aide à la recherche sur l’apprentissage par renforcement profond. Cet article expliquera comment utiliser le langage Go pour mener des recherches sur l'apprentissage par renforcement profond. 1. Installez le langage Go et les bibliothèques associées et commencez à utiliser le langage Go pour un apprentissage par renforcement en profondeur.
2023-06-10
commentaire 0
1226
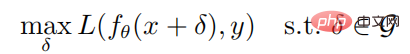
Attaques et défenses contradictoires dans l'apprentissage par renforcement profond
Présentation de l'article:01 Introduction Cet article porte sur le travail d'apprentissage par renforcement profond contre les attaques. Dans cet article, l'auteur étudie la robustesse des stratégies d'apprentissage par renforcement profond face aux attaques adverses dans la perspective d'une optimisation robuste. Dans le cadre d'une optimisation robuste, l'attaque adverse optimale est obtenue en minimisant le retour attendu de la stratégie et, par conséquent, un bon mécanisme de défense est obtenu en améliorant les performances de la stratégie face au pire des cas. Considérant que les attaquants sont généralement incapables d'attaquer dans l'environnement d'entraînement, l'auteur propose un algorithme d'attaque glouton qui tente de minimiser le retour attendu de la stratégie sans interagir avec l'environnement. De plus, l'auteur propose également un algorithme de défense qui permet l'entraînement contradictoire ; algorithmes d'apprentissage par renforcement profond utilisant des jeux max-min. Les résultats expérimentaux dans l'environnement de jeu Atari montrent que
2023-04-08
commentaire 0
1333
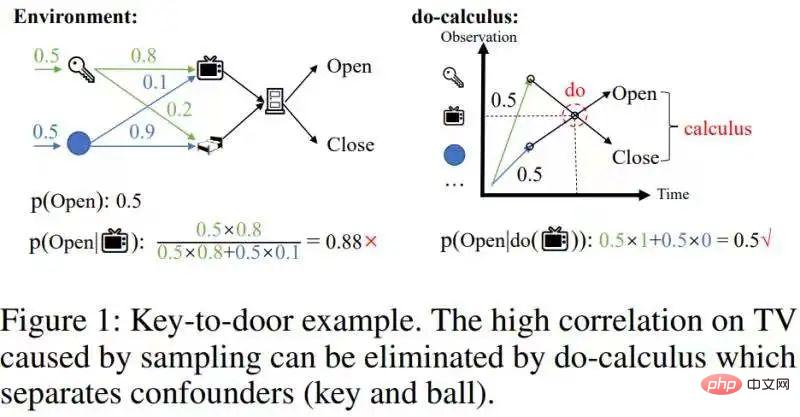
Présenté pour la première fois ! Utiliser l'inférence causale pour effectuer un apprentissage par renforcement partiellement observable
Présentation de l'article:Cet article « Inférence contrefactuelle rapide pour l'apprentissage par renforcement basé sur l'histoire » propose un algorithme d'inférence causale rapide qui réduit considérablement la complexité informatique de l'inférence causale - à un niveau qui peut être combiné avec l'apprentissage par renforcement en ligne. Les contributions théoriques de cet article comprennent principalement deux points : 1. Proposer le concept d'effets causals moyennés dans le temps. 2. Étendre le fameux critère de porte dérobée de l'estimation univariée de l'effet d'intervention à l'estimation multivariable de l'effet d'intervention, appelé critère de porte dérobée par étapes ; Le contexte nécessite la préparation de connaissances de base sur l’apprentissage par renforcement partiellement observable et l’inférence causale. Sans entrer ici dans trop d’introduction, donnons quelques portails : Amélioration partiellement observable
2023-04-15
commentaire 0
1083

Apprentissage par renforcement inverse : définition, principes et applications
Présentation de l'article:L'apprentissage par renforcement inverse (IRL) est une technique d'apprentissage automatique qui utilise le comportement observé pour déduire la motivation sous-jacente qui le sous-tend. Contrairement à l’apprentissage par renforcement traditionnel, l’IRL ne nécessite pas de signaux de récompense explicites, mais déduit plutôt des fonctions de récompense potentielles à travers le comportement. Cette méthode constitue un moyen efficace de comprendre et de simuler le comportement humain. Le principe de fonctionnement de l'IRL est basé sur le cadre du processus de décision de Markov (MDP). Dans MDP, l'agent interagit avec l'environnement en choisissant différentes actions. L'environnement donnera un signal de récompense basé sur les actions de l'agent. Le but de l'IRL est de déduire une fonction de récompense inconnue à partir du comportement observé de l'agent pour expliquer le comportement de l'agent. En analysant les actions choisies par un agent dans différents états, IRL peut modéliser les actions d’un agent.
2024-01-22
commentaire 0
887

Une méthode pour optimiser l'AB à l'aide de l'apprentissage par renforcement du gradient politique
Présentation de l'article:Les tests AB sont une technique largement utilisée dans les expériences en ligne. Son objectif principal est de comparer deux ou plusieurs versions d'une page ou d'une application afin de déterminer quelle version atteint les meilleurs objectifs commerciaux. Ces objectifs peuvent être des taux de clics, des taux de conversion, etc. En revanche, l’apprentissage par renforcement est une méthode d’apprentissage automatique qui utilise l’apprentissage par essais et erreurs pour optimiser les stratégies de prise de décision. L'apprentissage par renforcement par gradient de politiques est une méthode spéciale d'apprentissage par renforcement qui vise à maximiser les récompenses cumulatives en apprenant des politiques optimales. Les deux ont des applications différentes dans l’optimisation des objectifs commerciaux. Dans les tests AB, nous considérons les différentes versions de page comme différentes actions, et les objectifs commerciaux peuvent être considérés comme des indicateurs importants de signaux de récompense. Afin d'atteindre le maximum d'objectifs commerciaux, nous devons concevoir une stratégie capable de choisir
2024-01-24
commentaire 0
996

apprentissage par renforcement hiérarchique
Présentation de l'article:L'apprentissage par renforcement hiérarchique (HRL) est une méthode d'apprentissage par renforcement qui apprend les comportements et les décisions de haut niveau de manière hiérarchique. Différent des méthodes traditionnelles d'apprentissage par renforcement, HRL décompose la tâche en plusieurs sous-tâches, apprend une stratégie locale dans chaque sous-tâche, puis combine ces stratégies locales pour former une stratégie globale. Cette méthode d'apprentissage hiérarchique peut réduire les difficultés d'apprentissage causées par des environnements de grande dimension et des tâches complexes, et améliorer l'efficacité et les performances de l'apprentissage. Grâce à des stratégies hiérarchiques, HRL peut prendre des décisions à différents niveaux pour atteindre des comportements intelligents de niveau supérieur. Cette approche trouve des applications dans de nombreux domaines tels que le contrôle des robots, le gameplay et la conduite autonome.
2024-01-22
commentaire 0
1415

Problèmes de conception des fonctions de récompense dans l'apprentissage par renforcement
Présentation de l'article:Problèmes de conception de fonctions de récompense dans l'apprentissage par renforcement Introduction L'apprentissage par renforcement est une méthode qui apprend des stratégies optimales grâce à l'interaction entre un agent et l'environnement. Dans l’apprentissage par renforcement, la conception de la fonction de récompense est cruciale pour l’effet d’apprentissage de l’agent. Cet article explorera les problèmes de conception des fonctions de récompense dans l'apprentissage par renforcement et fournira des exemples de code spécifiques. Le rôle de la fonction de récompense et de la fonction de récompense cible constituent une partie importante de l'apprentissage par renforcement et sont utilisés pour évaluer la valeur de récompense obtenue par l'agent dans un certain état. Sa conception aide à guider l'agent pour maximiser la fatigue à long terme en choisissant les actions optimales.
2023-10-09
commentaire 0
1727

Problèmes de sélection d'algorithmes dans l'apprentissage par renforcement
Présentation de l'article:Le problème de la sélection d'algorithmes dans l'apprentissage par renforcement nécessite des exemples de code spécifiques. L'apprentissage par renforcement est un domaine de l'apprentissage automatique qui apprend des stratégies optimales grâce à l'interaction entre l'agent et l'environnement. Dans l’apprentissage par renforcement, le choix d’un algorithme approprié est crucial pour l’effet d’apprentissage. Dans cet article, nous explorons les problèmes de sélection d’algorithmes dans l’apprentissage par renforcement et fournissons des exemples de code concrets. Il existe de nombreux algorithmes parmi lesquels choisir en apprentissage par renforcement, tels que Q-Learning, DeepQNetwork (DQN), Actor-Critic, etc. Choisissez le bon algorithme
2023-10-08
commentaire 0
1197

Comment effectuer un apprentissage par renforcement profond et une traduction en langage naturel en PHP ?
Présentation de l'article:Dans le développement de la technologie moderne, l’apprentissage par renforcement profond et la traduction en langage naturel sont les deux domaines d’application les plus représentatifs. PHP, en tant que langage de programmation simple et facile à apprendre, peut également participer à ces deux domaines, offrant davantage de possibilités pour une application généralisée de la technologie de l'IA. 1. Apprentissage par renforcement profond L'apprentissage par renforcement profond est une direction de recherche populaire dans le domaine de l'intelligence artificielle et a été largement utilisé dans de nombreux domaines, notamment les jeux, la conduite autonome, le contrôle des robots, etc. L'idée principale est de former un réseau neuronal profond avec une entrée et une sortie cible données.
2023-05-22
commentaire 0
724

Comment effectuer un apprentissage par renforcement profond et une analyse du comportement des utilisateurs en PHP ?
Présentation de l'article:Avec le développement continu de la technologie du deep learning, l’intelligence artificielle est de plus en plus utilisée dans diverses industries. Parmi les différents langages de programmation, PHP, en tant que langage côté serveur populaire, peut également utiliser la technologie d'apprentissage par renforcement profond pour l'analyse du comportement des utilisateurs. L'apprentissage profond est une technologie d'apprentissage automatique qui découvre des modèles et des régularités en s'entraînant sur de grandes quantités de données. L'apprentissage par renforcement profond est une méthode qui combine l'apprentissage en profondeur et l'apprentissage par renforcement et est utilisée pour résoudre des problèmes de prise de décision complexes. Pour mettre en œuvre l'apprentissage par renforcement profond en PHP, vous devez utiliser les bibliothèques et boîtes PHP pertinentes.
2023-05-26
commentaire 0
1004


Des souris marchant dans le labyrinthe à AlphaGo battant les humains, le développement de l'apprentissage par renforcement
Présentation de l'article:Lorsqu’il s’agit d’apprentissage par renforcement, l’adrénaline de nombreux chercheurs monte de manière incontrôlable ! Il joue un rôle très important dans les systèmes d’IA de jeu, les robots modernes, les systèmes de conception de puces et d’autres applications. Il existe de nombreux types d'algorithmes d'apprentissage par renforcement, mais ils sont principalement divisés en deux catégories : « basés sur un modèle » et « sans modèle ». Dans une conversation avec TechTalks, le neuroscientifique et auteur de « The Birth of Intelligence » Daeyeol Lee a discuté de différents modèles d'apprentissage par renforcement chez les humains et les animaux, de l'intelligence artificielle et de l'intelligence naturelle, ainsi que des orientations de recherche futures. Apprentissage par renforcement sans modèle À la fin du XIXe siècle, la « loi de l'effet » proposée par le psychologue Edward Thorndike est devenue la base de l'apprentissage par renforcement sans modèle. Ème
2023-05-09
commentaire 0
877

Huang Hongbo, expert technique en IA de Xishanju : Intégration pratique de l'apprentissage par renforcement et des arbres de comportement dans les jeux
Présentation de l'article:Du 6 au 7 août 2022, la conférence mondiale sur les technologies d'intelligence artificielle AISummit se tiendra comme prévu. Lors du sous-forum « Exploration des frontières de l'intelligence artificielle » tenu dans l'après-midi du 7, Huang Hongbo, un expert technique en IA de Xishanju, a partagé le thème « Combinaison pratique de l'apprentissage par renforcement et des arbres de comportement dans les jeux » et a partagé en détail le impact de l’apprentissage par renforcement dans le domaine du jeu. Huang Hongbo a déclaré que la mise en œuvre de la technologie d'apprentissage par renforcement ne consiste pas à modifier l'algorithme pour le rendre plus puissant, mais à combiner la technologie d'apprentissage par renforcement avec l'apprentissage en profondeur et la planification de jeux pour former un ensemble complet de solutions et les mettre en œuvre. L'apprentissage par renforcement rend les jeux plus intelligents. La mise en œuvre de l'apprentissage par renforcement dans les jeux peut rendre les jeux plus intelligents et plus jouables.
2023-04-09
commentaire 0
1829

PromptPG : Quand l'apprentissage par renforcement rencontre des modèles de langage à grande échelle
Présentation de l'article:Le raisonnement mathématique est une capacité essentielle de l’intelligence humaine, mais la pensée abstraite et le raisonnement logique restent un défi de taille pour les machines. Les modèles linguistiques pré-entraînés à grande échelle, tels que GPT-3 et GPT-4, ont fait des progrès significatifs dans le raisonnement mathématique basé sur du texte (comme les problèmes de mots mathématiques). Cependant, il n’est pas encore clair si ces modèles peuvent traiter des problèmes plus complexes impliquant des informations hétérogènes telles que des données tabulaires. Pour combler cette lacune, des chercheurs de l'UCLA et de l'Allen Institute for Artificial Intelligence (AI2) introduisent les Tabular Math Word Problems (TabMWP), un ensemble de données de 38 431 problèmes en domaine ouvert qui nécessitent
2023-04-07
commentaire 0
1232

Jusqu'où Transformer a-t-il évolué en matière d'apprentissage par renforcement ? L'Université Tsinghua, l'Université de Pékin et d'autres ont publié conjointement une revue de TransformRL
Présentation de l'article:L'apprentissage par renforcement (RL) fournit une forme mathématique pour la prise de décision séquentielle, et l'apprentissage par renforcement profond (DRL) a également fait de grands progrès ces dernières années. Cependant, les problèmes d’efficacité des échantillons entravent l’application généralisée des méthodes d’apprentissage par renforcement profond dans le monde réel. Pour résoudre ce problème, un mécanisme efficace consiste à introduire un biais inductif dans le cadre DRL. Dans l’apprentissage par renforcement profond, les approximateurs de fonctions sont très importants. Cependant, par rapport à la conception architecturale en apprentissage supervisé (SL), les problématiques de conception architecturale en DRL sont encore rarement étudiées. La plupart des travaux existants sur les architectures RL ont été menés par la communauté d'apprentissage supervisé/semi-supervisé. Par exemple, pour traiter les entrées basées sur des images de grande dimension dans DRL, une approche courante consiste à introduire des réseaux de neurones convolutifs (CNN) [
2023-04-13
commentaire 0
781
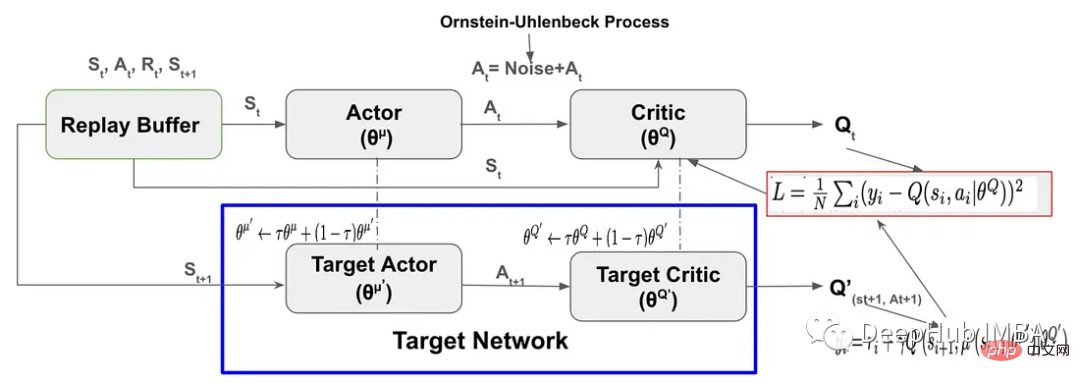
Implémentation du code PyTorch et explication étape par étape de l'apprentissage par renforcement DDPG
Présentation de l'article:Deep Deterministic Policy Gradient (DDPG) est un algorithme de renforcement profond sans modèle et sans politique inspiré de Deep Q-Network. Il est basé sur Actor-Critic utilisant le gradient de politique. Cet article utilisera pytorch pour l'implémenter pleinement et expliquera le. Les composants clés de DDPG sont Replay BufferActor-Critic neural networkExploration NoiseTarget networkSoft Target Updates pour Target Netwo
2023-04-13
commentaire 0
1764

Qu'est-ce que l'apprentissage par renforcement profond en Python ?
Présentation de l'article:Qu’est-ce que l’apprentissage par renforcement profond en Python ? L’apprentissage par renforcement profond (DRL) est devenu ces dernières années un axe de recherche clé dans le domaine de l’intelligence artificielle, en particulier dans des applications telles que les jeux, les robots et le traitement du langage naturel. Les bibliothèques d'apprentissage par renforcement et de deep learning basées sur le langage Python, comme TensorFlow, PyTorch, Keras, etc., nous permettent d'implémenter plus facilement les algorithmes DRL. Le fondement théorique de l’apprentissage par renforcement profond
2023-06-04
commentaire 0
1826

Comment mettre à niveau les amateurs de pêche vers des didacticiels d'équipement avancés permettant aux amateurs de pêche de mettre à niveau leur équipement
Présentation de l'article:Il s'agit d'un tutoriel destiné aux amateurs de pêche pour améliorer leur équipement. Je pense que de nombreux joueurs sont également très attentifs à la manière d'améliorer leur équipement. Jetons un coup d'œil au contenu spécifique de cette section, j'espère qu'il vous plaira. 1. Commencez le renforcement. Cliquez sur la canne à pêche dans l'interface de votre propre équipement, puis vous verrez le bouton de renforcement, comme indiqué sur l'image. Cliquez pour accéder à l'interface de renforcement. 2. L'amélioration ordinaire a deux options : l'amélioration ordinaire et l'amélioration en espèces peuvent échouer, tandis que l'amélioration en espèces peut garantir un succès à 100 %. La mise à niveau n'échouera pas avant +4, il est donc recommandé aux joueurs d'utiliser d'abord des pièces d'or pour la renforcer. 3. Renforcement réussi Après un renforcement réussi, les dommages de la canne à pêche seront accrus. Les dégâts affecteront l'étendue de la force physique du poisson consommée à chaque fois. Plus les dégâts sont élevés, plus la force physique sera consommée à chaque fois. Si vous voulez attraper de gros poissons rares, vous devez
2024-07-20
commentaire 0
511

L'application d'apprentissage automatique de Golang pour l'apprentissage par renforcement
Présentation de l'article:Introduction à l'application d'apprentissage automatique de Golang dans l'apprentissage par renforcement L'apprentissage par renforcement est une méthode d'apprentissage automatique qui apprend un comportement optimal en interagissant avec l'environnement et en fonction des commentaires de récompense. Le langage Go possède des fonctionnalités telles que le parallélisme, la concurrence et la sécurité de la mémoire, ce qui lui confère un avantage dans l'apprentissage par renforcement. Cas pratique : Apprentissage par renforcement Go Dans ce tutoriel, nous utiliserons le langage Go et l'algorithme AlphaZero pour implémenter un modèle d'apprentissage par renforcement Go. Étape 1 : Installer les dépendances gogetgithub.com/tensorflow/tensorflow/tensorflow/gogogetgithub.com/golang/protobuf/ptypes/times
2024-05-08
commentaire 0
510

Problèmes de conception de récompense dans l'apprentissage par renforcement
Présentation de l'article:Le problème de la conception des récompenses dans l'apprentissage par renforcement nécessite des exemples de code spécifiques. L'apprentissage par renforcement est une méthode d'apprentissage automatique dont l'objectif est d'apprendre à prendre des mesures qui maximisent les récompenses cumulatives grâce à l'interaction avec l'environnement. Dans l’apprentissage par renforcement, la récompense joue un rôle crucial. Elle constitue un signal dans le processus d’apprentissage de l’agent et sert à guider son comportement. Cependant, la conception des récompenses est un problème difficile, et une conception raisonnable des récompenses peut grandement affecter les performances des algorithmes d’apprentissage par renforcement. Dans l’apprentissage par renforcement, les récompenses peuvent être considérées comme l’agent contre l’environnement.
2023-10-08
commentaire 0
1448
