
Cours Avancé 13831
Introduction au cours:Ce numéro est toujours un enseignement diffusé en direct par des experts du secteur, ciblant les étudiants n'ayant aucune connaissance de base ou les étudiants qui sont passés du back-end au front-end. La conception du cours est divisée en quatre étapes, avec un total de 50 jours d'apprentissage, basées sur le projet HTML5+CSS3+JS+Vue3+Vant original. Le Vue3+Vite+TS+ElementPlus actuellement le plus populaire a été ajouté pour compléter le développement multi-fin du front-end du centre commercial, du système de gestion back-end du centre commercial, des mini-programmes, des applications, etc. Pour des demandes détaillées, veuillez contacter WeChat : phpcn01 (Professeur Yueyue)

Cours Intermédiaire 11272
Introduction au cours:"Tutoriel vidéo d'auto-apprentissage sur l'équilibrage de charge Linux du réseau informatique" implémente principalement l'équilibrage de charge Linux en effectuant des opérations de script sur le Web, lvs et Linux sous nagin.

Cours Avancé 17597
Introduction au cours:"Tutoriel vidéo Shang Xuetang MySQL" vous présente le processus depuis l'installation jusqu'à l'utilisation de la base de données MySQL, et présente en détail les opérations spécifiques de chaque lien.
Mettre à jour la version Bootstrap dans un grand projet Laravel
2023-09-03 19:24:13 0 1 606
2018-06-04 13:03:08 32 848 64206
2018-10-17 09:05:25 1 1 2974
2018-01-22 11:04:52 29 418 53877
Pourquoi __all__ de Python ne peut-il pas empêcher « le contenu non exporté n'est pas accessible » ?
2017-05-18 10:50:54 0 2 747
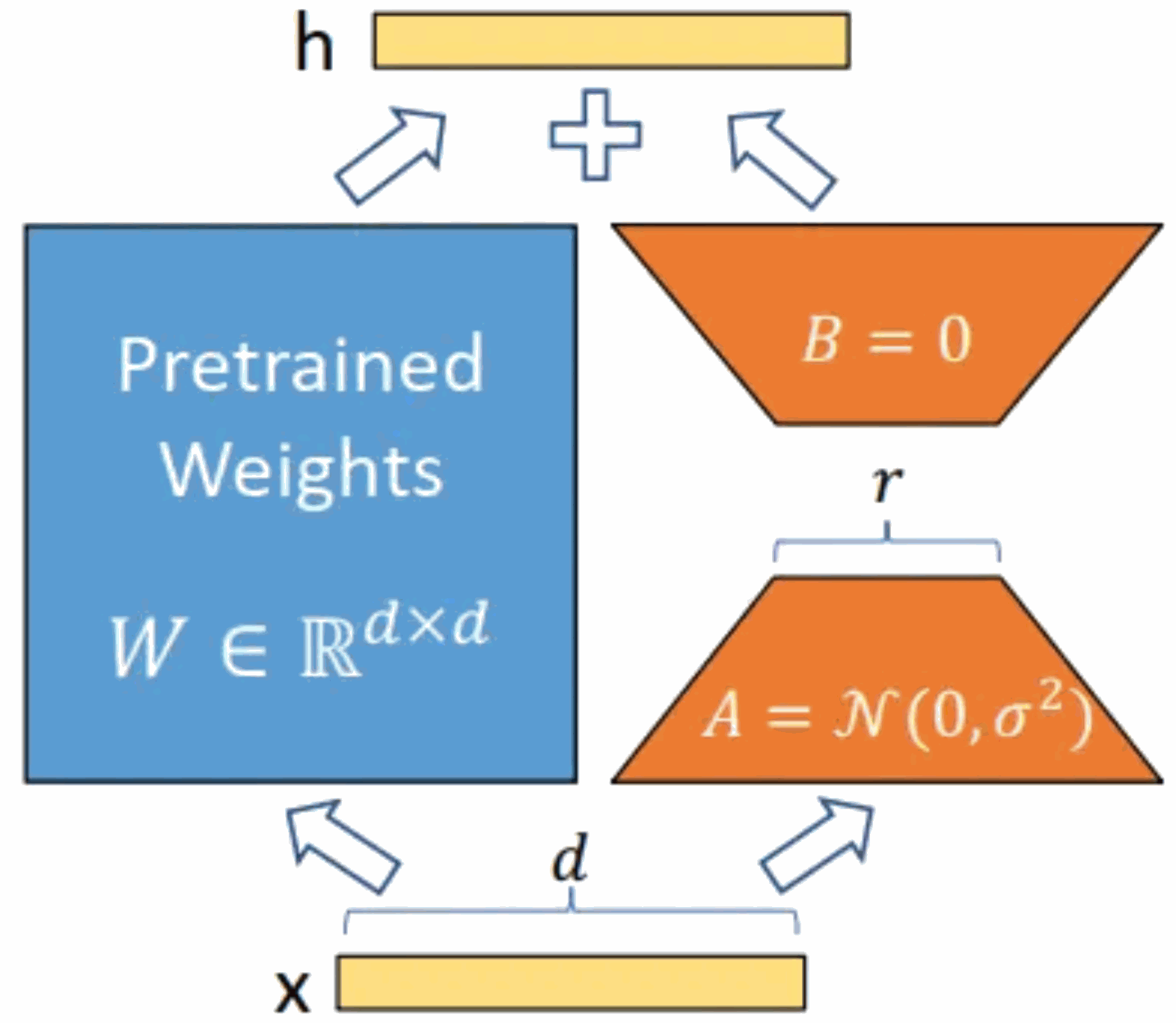
Introduction au cours:Introduction du modèle : Le modèle Alpaca est un modèle open source LLM (Large Language Model, big language) développé par l'Université de Stanford. Il est affiné à partir du modèle LLaMA7B (7B open source de la société Meta) sur 52 000 instructions. paramètres du modèle (plus les paramètres du modèle sont grands, plus les paramètres du modèle sont grands), plus la capacité de raisonnement du modèle est forte, bien sûr, plus le coût de formation du modèle est élevé). LoRA, le nom anglais complet est Low-RankAdaptation of Large Language Models, traduit littéralement par adaptation de bas niveau de grands modèles de langage. Il s'agit d'une technologie développée par les chercheurs de Microsoft pour résoudre le réglage fin des grands modèles de langage. Si vous souhaitez qu'un grand modèle de langage pré-entraîné soit capable d'exécuter un domaine spécifique
2023-06-01 commentaire 0 1828

Introduction au cours:Les grands modèles de langage et les modèles d’intégration de mots sont deux concepts clés du traitement du langage naturel. Ils peuvent tous deux être appliqués à l’analyse et à la génération de texte, mais les principes et les scénarios d’application sont différents. Les modèles linguistiques à grande échelle sont principalement basés sur des modèles statistiques et probabilistes et conviennent à la génération continue de textes et à une compréhension sémantique. Le modèle d'intégration de mots peut capturer la relation sémantique entre les mots en mappant les mots sur un espace vectoriel, et convient à l'inférence de signification de mot et à la classification de texte. 1. Modèle d'incorporation de mots Le modèle d'incorporation de mots est une technologie qui traite les informations textuelles en mappant les mots dans un espace vectoriel de faible dimension. Il convertit les mots d'une langue sous forme vectorielle afin que les ordinateurs puissent mieux comprendre et traiter le texte. Les modèles d'intégration de mots couramment utilisés incluent Word2Vec et GloVe. Ces modèles sont largement utilisés dans les tâches de traitement du langage naturel
2024-01-23 commentaire 0 1460

Introduction au cours:Les modèles linguistiques à grande échelle constituent une technologie clé dans le domaine du traitement du langage naturel, affichant de solides performances dans diverses tâches. La stratégie de décodage est l'un des aspects importants de la génération de texte par le modèle. Cet article détaillera les stratégies de décodage dans les grands modèles de langage et discutera de leurs avantages et inconvénients. 1. Aperçu des stratégies de décodage Dans les grands modèles de langage, les stratégies de décodage sont des méthodes permettant de générer des séquences de texte. Les stratégies de décodage courantes incluent la recherche gourmande, la recherche par faisceau et la recherche aléatoire. La recherche gourmande est une méthode simple et directe qui sélectionne à chaque fois le mot avec la probabilité la plus élevée comme mot suivant, mais peut ignorer d'autres possibilités. La recherche par faisceau ajoute une restriction de largeur sur la base d'une recherche gourmande, ne conservant que les mots candidats ayant la probabilité la plus élevée, augmentant ainsi la diversité. La recherche aléatoire sélectionne au hasard le mot suivant, ce qui peut produire des résultats plus diversifiés.
2024-01-22 commentaire 0 1201

Introduction au cours:Le plus grand risque auquel est actuellement confrontée la technologie de l’intelligence artificielle est que la vitesse de développement et d’application des grands modèles linguistiques (LLM) et de la technologie de l’intelligence artificielle générative a largement dépassé la vitesse de la sécurité et de la gouvernance. L’utilisation de produits d’IA générative et de grands modèles de langage d’entreprises comme OpenAI, Anthropic, Google et Microsoft connaît une croissance exponentielle. Dans le même temps, les solutions open source de grands modèles de langage connaissent également une croissance rapide. Les communautés d'intelligence artificielle open source telles que HuggingFace fournissent un grand nombre de modèles open source, d'ensembles de données et d'applications d'IA. Afin de promouvoir le développement de l'intelligence artificielle, des organisations industrielles telles que l'OWASP, OpenSSF et CISA développent et fournissent activement des actifs clés pour la sécurité et la gouvernance de l'intelligence artificielle, tels que OWASPAIExchange,
2024-04-17 commentaire 0 1058

Introduction au cours:Cet article examine les métriques les plus largement utilisées et les plus fiables pour évaluer les grands modèles de langage (LLM). L'article traite des différentes catégories de métriques, notamment BLEU, ROUGE, METEOR et NIST, et de la manière dont elles mesurent les performances de L.
2024-08-13 commentaire 0 1058
