
Cours Intermédiaire 11382
Introduction au cours:"Tutoriel vidéo d'auto-apprentissage sur l'équilibrage de charge Linux du réseau informatique" implémente principalement l'équilibrage de charge Linux en effectuant des opérations de script sur le Web, lvs et Linux sous nagin.

Cours Avancé 17696
Introduction au cours:"Tutoriel vidéo Shang Xuetang MySQL" vous présente le processus depuis l'installation jusqu'à l'utilisation de la base de données MySQL, et présente en détail les opérations spécifiques de chaque lien.

Cours Avancé 11395
Introduction au cours:« Tutoriel vidéo d'affichage d'exemples front-end de Brothers Band » présente des exemples de technologies HTML5 et CSS3 à tout le monde, afin que chacun puisse devenir plus compétent dans l'utilisation de HTML5 et CSS3.
2023-09-05 11:18:47 0 1 884
Expérimentez le tri après la limite de requête
2023-09-05 14:46:42 0 1 769
Grille CSS : créer une nouvelle ligne lorsque le contenu enfant dépasse la largeur de la colonne
2023-09-05 15:18:28 0 1 650
Fonctionnalité de recherche en texte intégral PHP utilisant les opérateurs AND, OR et NOT
2023-09-05 15:06:32 0 1 620
Le moyen le plus court de convertir tous les types PHP en chaîne
2023-09-05 15:34:44 0 1 1035

Introduction au cours:L'apprentissage par renforcement profond (DeepReinforcementLearning) est une technologie avancée qui combine l'apprentissage en profondeur et l'apprentissage par renforcement. Elle est largement utilisée dans la reconnaissance vocale, la reconnaissance d'images, le traitement du langage naturel et d'autres domaines. En tant que langage de programmation rapide, efficace et fiable, le langage Go peut apporter une aide à la recherche sur l’apprentissage par renforcement profond. Cet article expliquera comment utiliser le langage Go pour mener des recherches sur l'apprentissage par renforcement profond. 1. Installez le langage Go et les bibliothèques associées et commencez à utiliser le langage Go pour un apprentissage par renforcement en profondeur.
2023-06-10 commentaire 0 1220
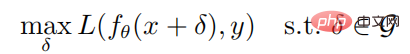
Introduction au cours:01 Introduction Cet article porte sur le travail d'apprentissage par renforcement profond contre les attaques. Dans cet article, l'auteur étudie la robustesse des stratégies d'apprentissage par renforcement profond face aux attaques adverses dans la perspective d'une optimisation robuste. Dans le cadre d'une optimisation robuste, l'attaque adverse optimale est obtenue en minimisant le retour attendu de la stratégie et, par conséquent, un bon mécanisme de défense est obtenu en améliorant les performances de la stratégie face au pire des cas. Considérant que les attaquants sont généralement incapables d'attaquer dans l'environnement d'entraînement, l'auteur propose un algorithme d'attaque glouton qui tente de minimiser le retour attendu de la stratégie sans interagir avec l'environnement. De plus, l'auteur propose également un algorithme de défense qui permet l'entraînement contradictoire ; algorithmes d'apprentissage par renforcement profond utilisant des jeux max-min. Les résultats expérimentaux dans l'environnement de jeu Atari montrent que
2023-04-08 commentaire 0 1326
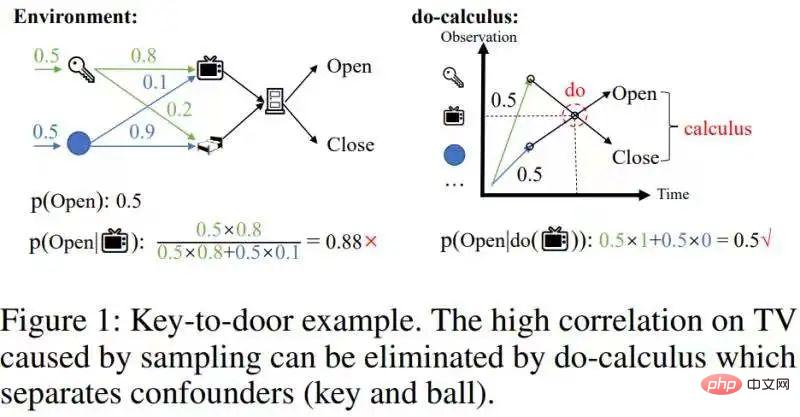
Introduction au cours:Cet article « Inférence contrefactuelle rapide pour l'apprentissage par renforcement basé sur l'histoire » propose un algorithme d'inférence causale rapide qui réduit considérablement la complexité informatique de l'inférence causale - à un niveau qui peut être combiné avec l'apprentissage par renforcement en ligne. Les contributions théoriques de cet article comprennent principalement deux points : 1. Proposer le concept d'effets causals moyennés dans le temps. 2. Étendre le fameux critère de porte dérobée de l'estimation univariée de l'effet d'intervention à l'estimation multivariable de l'effet d'intervention, appelé critère de porte dérobée par étapes ; Le contexte nécessite la préparation de connaissances de base sur l’apprentissage par renforcement partiellement observable et l’inférence causale. Sans entrer ici dans trop d’introduction, donnons quelques portails : Amélioration partiellement observable
2023-04-15 commentaire 0 1081

Introduction au cours:L'apprentissage par renforcement inverse (IRL) est une technique d'apprentissage automatique qui utilise le comportement observé pour déduire la motivation sous-jacente qui le sous-tend. Contrairement à l’apprentissage par renforcement traditionnel, l’IRL ne nécessite pas de signaux de récompense explicites, mais déduit plutôt des fonctions de récompense potentielles à travers le comportement. Cette méthode constitue un moyen efficace de comprendre et de simuler le comportement humain. Le principe de fonctionnement de l'IRL est basé sur le cadre du processus de décision de Markov (MDP). Dans MDP, l'agent interagit avec l'environnement en choisissant différentes actions. L'environnement donnera un signal de récompense basé sur les actions de l'agent. Le but de l'IRL est de déduire une fonction de récompense inconnue à partir du comportement observé de l'agent pour expliquer le comportement de l'agent. En analysant les actions choisies par un agent dans différents états, IRL peut modéliser les actions d’un agent.
2024-01-22 commentaire 0 885

Introduction au cours:Les tests AB sont une technique largement utilisée dans les expériences en ligne. Son objectif principal est de comparer deux ou plusieurs versions d'une page ou d'une application afin de déterminer quelle version atteint les meilleurs objectifs commerciaux. Ces objectifs peuvent être des taux de clics, des taux de conversion, etc. En revanche, l’apprentissage par renforcement est une méthode d’apprentissage automatique qui utilise l’apprentissage par essais et erreurs pour optimiser les stratégies de prise de décision. L'apprentissage par renforcement par gradient de politiques est une méthode spéciale d'apprentissage par renforcement qui vise à maximiser les récompenses cumulatives en apprenant des politiques optimales. Les deux ont des applications différentes dans l’optimisation des objectifs commerciaux. Dans les tests AB, nous considérons les différentes versions de page comme différentes actions, et les objectifs commerciaux peuvent être considérés comme des indicateurs importants de signaux de récompense. Afin d'atteindre le maximum d'objectifs commerciaux, nous devons concevoir une stratégie capable de choisir
2024-01-24 commentaire 0 995
