
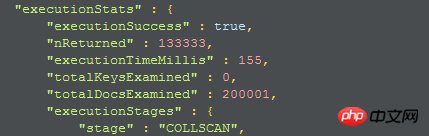
Lorsque j'utilise directement find pour renvoyer tous les champs, les résultats sont les suivants et le temps de requête est de 155

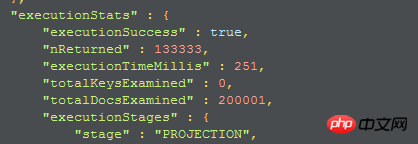
Si le champ de retour est limité, le temps de requête sera plus long, le temps de requête est de 251

Pourquoi ? Si je limite les champs renvoyés, les octets des caractères de requête seront plus petits, la transmission ne devrait-elle pas être plus rapide ?















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




Le plan d'exécution que vous avez posté révèle principalement les informations suivantes :
1. Le premier plan d'exécution :
Étant donné qu'aucun index n'est utilisé, collscan révèle qu'il s'agit d'une analyse de collection complète, vous pouvez donc envisager de créer un index
2. Le deuxième plan d'exécution :
Il s'agit toujours d'une analyse de collection complète, et les documents qui remplissent les conditions sont numérisés dans la mémoire, et la projection est terminée dans la mémoire, le champ spécifié est sélectionné et le champ est renvoyé. Il semble que cela prendra plus de temps.
Bien que seul le champ spécifié soit renvoyé, lors de la lecture du stockage ou de la numérisation de l'intégralité de la collection, seuls l'intégralité des documents peuvent être renvoyés. Il s'agit probablement de quelques principes de base des bases de données : lire et écrire selon des documents ; de plus, certaines bases de données en colonnes sont enregistrées selon des colonnes, ce qui est la situation que vous avez imaginée, mais de nombreuses bases de données sont enregistrées selon des lignes ou des documents.
Si vous créez un index couvert sur un champ spécifié et renvoyez uniquement le champ spécifié, c'est le plus efficace, car seule l'analyse de l'index peut renvoyer le champ spécifié.
Pour référence.
J'adore MongoDB ! Amusez-vous!