Il n'y a pas de problème si vous téléchargez sur le lecteur D, mais il y a un problème si vous téléchargez dans le répertoire que j'ai créé (principalement parce que je souhaite créer un répertoire sur le lecteur D nommé avec le numéro devant le point d'interrogation dans l'URL, telle que (http://v.yupoo) .com/photos/196...') ne fonctionnera tout simplement pas, car il existe de nombreux liens et le numéro de chaque lien que je souhaite utiliser. ce numéro comme nom du dossier pour stocker les images téléchargées depuis ce lien)
Le code source est le suivant : 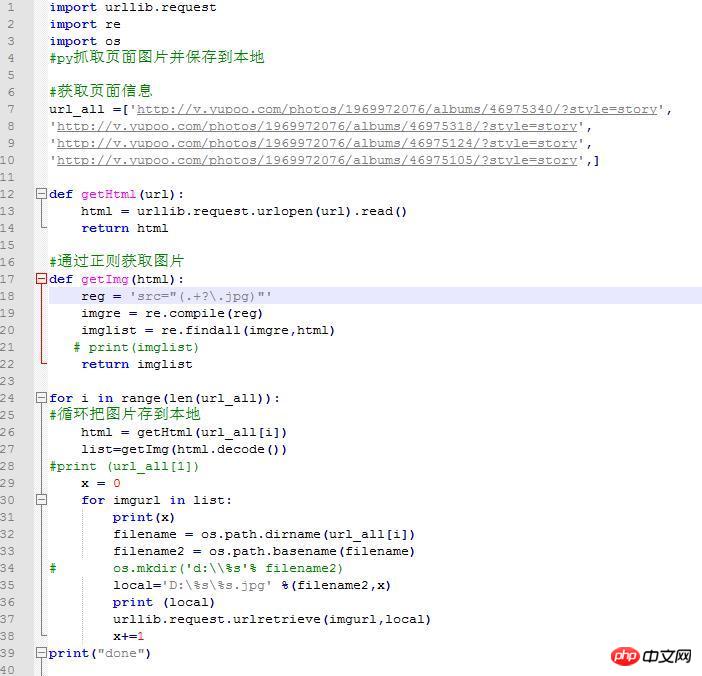
import urllib.request
import re
import os
url_all =['http://v.yupoo.com/photos/196...',
'http://v.yupoo.com/photos/196...',
'http://v .yupoo.com/photos/196...',
'http://v.yupoo.com/photos/196...',]
def getHtml(url):
html = urllib.request.urlopen(url).read()
return html
def getImg(html):
reg = 'src="(.+?\.jpg)"'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)# imprimer(imglist)
return imglist
pour moi à portée(len(url_all)):
html = getHtml(url_all[i])
list=getImg(html.decode())x = 0
for imgurl in list:
print(x)
filename = os.path.dirname(url_all[i])
filename2 = os.path.basename(filename) local='D:\%s\%s.jpg' %(filename2,x)
print (local)
urllib.request.urlretrieve(imgurl,local)
x+=1Erreur d'exécution : (système win10 64 bits, python3.6)
Fichier "C:Python36liburlllibrequest.py", ligne 258, dans urlretrieve
tfp = open(nom de fichier, 'wb')
La dernière phrase écrite ainsi peut être affichée : urllib.request.urlretrieve(imgurl,'d:%s.jpg'% str(i*10+x))
local='d:%s%s.jpg' %(filename2,x)
urllib.request.urlretrieve(imgurl,local)
Le message d'erreur est le suivant : (Idem que ci-dessus)
Fichier "C:Python36liburlllibrequest.py", ligne 258, dans urlretrieve
tfp = open(nom de fichier, 'wb')
FileNotFoundError : [Errno 2] Aucun fichier ou répertoire de ce type : 'd:46975340
S'il vous plaît, dites-moi, y a-t-il un problème avec ce chemin ? Comment faut-il l'écrire.















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




Avant de sauvegarder, vérifiez si le répertoire existe, et créez-le s'il n'existe pas