source_ip = line.split('- -')[0].strip()
if re.match('[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}',source_ip):
if source_ip_dict.get(source_ip,'-')=='-':
source_ip_dict[source_ip]=1
else:
source_ip_dict[source_ip]=source_ip_dict[source_ip]+1Extrayez l'adresse IP du journal Apache via le code ci-dessus et effectuez une déduplication statistique
Les données IP extraites sont les suivantes : 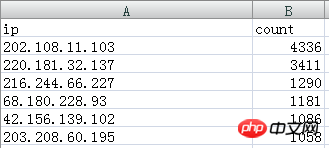
Alors, comment nommer et classer ces adresses IP,
Par exemple,
202.108.11.103 et 220.181.32.137 sont des IP Baidu Spider
L'effet souhaité est le suivant
Nommez ces deux IP comme Baidu Spider, puis comparez leurs données statistiques. Ajouter 4336+3411
Baidu Spider 7747
Comment faire fonctionner ceci














![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




Vous pouvez essayer de créer un grand dictionnaire avec le dictionnaire comme clé et le nom du robot comme valeur ;
Tableau croisé dynamique utilisant des pandas
Comme c'est fatiguant !
Pourquoi ne pas créer une table distincte pour ce groupe IP, nommée IPGroup (id, ip, groupname)
Après cela, cela peut être fait avec un seul SQL, comme c'est simple (laissez l'affiche utiliser IPStastics)