Dans TensorFlow, je souhaite créer un modèle de régression logistique avec la fonction de coût suivante :
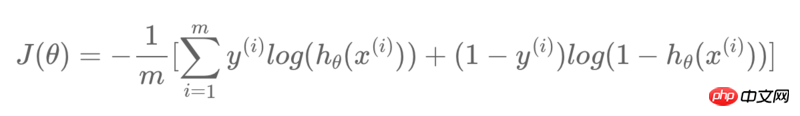
La capture d'écran de l'ensemble de données utilisé est la suivante :
Mon code est le suivant :
train_X = train_data[:, :-1]
train_y = train_data[:, -1:]
feature_num = len(train_X[0])
sample_num = len(train_X)
print("Size of train_X: {}x{}".format(sample_num, feature_num))
print("Size of train_y: {}x{}".format(len(train_y), len(train_y[0])))
X = tf.placeholder(tf.float32)
y = tf.placeholder(tf.float32)
W = tf.Variable(tf.zeros([feature_num, 1]))
b = tf.Variable([-.3])
db = tf.matmul(X, tf.reshape(W, [-1, 1])) + b
hyp = tf.sigmoid(db)
cost0 = y * tf.log(hyp)
cost1 = (1 - y) * tf.log(1 - hyp)
cost = (cost0 + cost1) / -sample_num
loss = tf.reduce_sum(cost)
optimizer = tf.train.GradientDescentOptimizer(0.1)
train = optimizer.minimize(loss)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
print(0, sess.run(W).flatten(), sess.run(b).flatten())
sess.run(train, {X: train_X, y: train_y})
print(1, sess.run(W).flatten(), sess.run(b).flatten())
sess.run(train, {X: train_X, y: train_y})
print(2, sess.run(W).flatten(), sess.run(b).flatten())La capture d'écran des résultats en cours est la suivante :
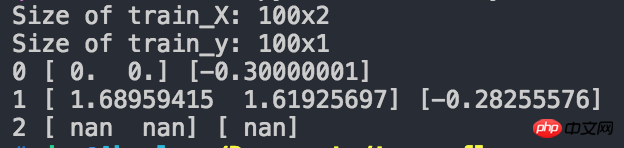
Vous pouvez voir qu'après deux itérations, nous avons obtenu W和b都变成了nan Quel est le problème ?














![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




Après quelques recherches, j'ai trouvé le problème.
Dans la phrase sur la sélection de la méthode d'itération :
Vous pouvez vous entraîner normalement ici
0.1的学习率过大,导致不知什么原因在损失函数中出现了log(0)的情况,结果导致了损失函数的值为nan,解决方法是减小学习率,比如降到1e-5或者1e-6J'ai ajusté le taux d'apprentissage à 1e-3 en fonction de ma propre situation, et le programme fonctionne parfaitement.Ci-joint le résultat final de l'essayage :