
Je viens d'apprendre à obtenir du contenu json, mais le site Web que j'ai exploré aujourd'hui ne renvoie pas de contenu json et un nombre aléatoire est généré après chaque lien de demande
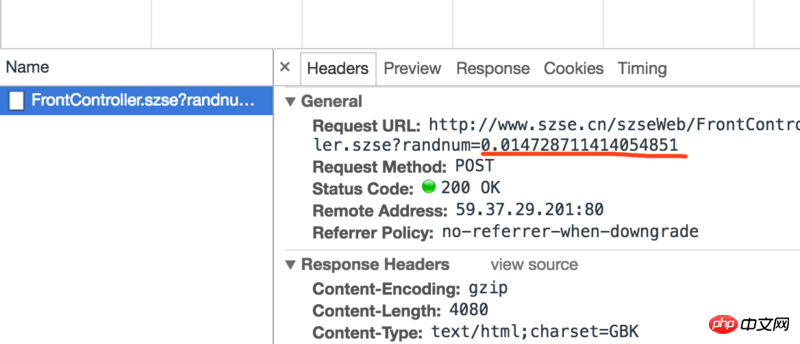
Je ne sais pas si cela affectera le contenu que je souhaite explorer
Le contenu que vous devez obtenir est le contenu au milieu de l'image ci-dessous
Lien vers le site http://www.szse.cn/main/discl...
Code que j'ai moi-même essayé :
import requests
dir = '/Users/S1Lence/Desktop/new_html/szse/许可类重组问询函'
headers = {'Host': 'www.szse.cn',
'Referer': 'http://www.szse.cn/main/disclosure/jgxxgk/wxhj/',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.109 Safari/537.36'
}
payload= {'ACTIONID': '7',
'AJAX': 'AJAX-TRUE',
'CATALOGID': 'main_wxhj',
'TABKEY': 'tab1',
'selecthjlb': '许可类重组问询函',
'tab1PAGENO': '1',
'tab1PAGECOUNT': '7',
'tab1RECORDCOUNT': '63',
'REPORT_ACTION': 'navigate'}
res = requests.post('http://www.szse.cn/szseWeb/FrontControllere', data=payload)
print(res.text)
Le contenu de sortie n'est pas celui que je souhaite. Comment dois-je l'explorer ?















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




Copiez ses informations d'en-tête et utilisez-les. .
L'adresse URL de votre message est erronée, elle devrait l'être