
根据网页所给的字符编码将其字节数据decode('gb2312')
用的是scrapy,从给出的url获取body
def parse(self, response):
body = response.body.decode('gb2312')
print(body)
学分:1.5 # body就是这样之类的,中间的冒号是中文的冒号
# 想弄成的效果就是['学分','1.5']
body = body.split(':') # 就这样使用中文的冒号符来分割,但是出错
SyntaxError: (unicode error) 'utf-8' codec can't decode byte 0xa3 in position 0: invalid start byte
请问怎么解决?















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




En regardant à nouveau l'erreur ci-dessus, il s'agit de
octet 0xa3Je l'ai donc essayé plusieurs fois sur le terminal et j'ai découvert que les deux points étaient encodés en gb2312
>>> b'\xa3\xba'.decode('gb2312') ':'Il devrait donc être que python utilise l'utf-8 par défaut pour décoder le corps de gb2312, donc une façon à laquelle je peux penser est de modifier la valeur d'encodage par défaut, qui est l'instruction sur la première ligne :
# -*- codage : gb2312 -*-Alors l'opération a réussi. Existe-t-il une autre méthode ?
Python3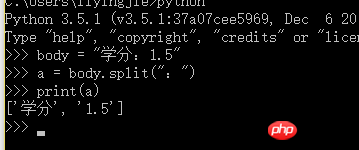
Après le décodage, le corps doit être encodé en Unicode, utilisez la méthode suivante :
Un autre problème d'encodage, vous pouvez vous référer à : Encodage de caractères pour l'interaction homme-machine et Vaincre l'encodage de caractères Python en cinq minutes.
#! /usr/bin/env python # -*- codage : utf-8 -*- # Imitez les données que vous obtenez de la page Web data = "Crédit : 1,5".decode("utf-8").encode('gb2312') # data = u"Crédit : 1,5".encode('gb2312') type d'impression (données) corps = data.decode('gb2312') type d'impression (corps) #type unicode # Deux solutions print body.split(u':') #unicode correspond à unicode print body.encode("utf-8").split(":") # utf-8 correspond à utf-8