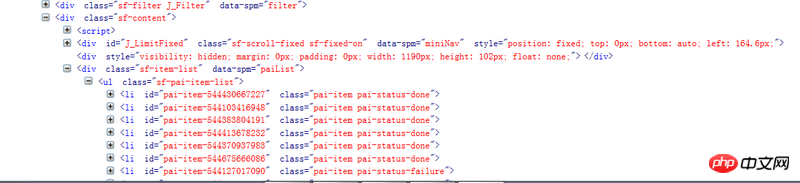
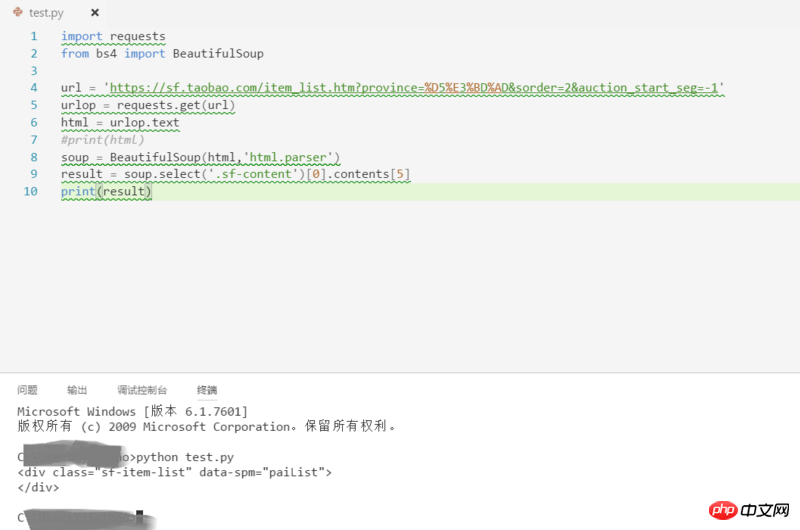
Questionneur, si vous utilisez Chrome F12 pour le visualiser, il y aura du contenu chargé dynamiquement, et vous ne pouvez pas obtenir ce contenu en demandant directement l'URL de la page. Il est recommandé de cliquer avec le bouton droit pour afficher le code source de la page Web et de le comparer avec le contenu de F12. S'il n'y a pas de contenu dans le code source, vérifiez les autres requêtes du réseau pour voir s'il y a des données que vous avez. besoin.
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




N'avez-vous jamais envisagé le chargement dynamique avec javascript ?
Questionneur, si vous utilisez Chrome F12 pour le visualiser, il y aura du contenu chargé dynamiquement, et vous ne pouvez pas obtenir ce contenu en demandant directement l'URL de la page. Il est recommandé de cliquer avec le bouton droit pour afficher le code source de la page Web et de le comparer avec le contenu de F12. S'il n'y a pas de contenu dans le code source, vérifiez les autres requêtes du réseau pour voir s'il y a des données que vous avez. besoin.