
环境:
windows 10
PyCharm 2016.3.2
遇到问题:
刚开始学python,想用BeautifulSoup解析网页,但出现报错:
UserWarning: No parser was explicitly specified, so I'm using the best available HTML parser for this system ("lxml"). This usually isn't a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.
The code that caused this warning is on line 4 of the file C:/Users/excalibur/PycharmProjects/learn/getMyIP.py. To get rid of this warning, change code that looks like this:
BeautifulSoup([your markup])
to this:
BeautifulSoup([your markup], "lxml")
markup_type=markup_type))然后根据提示和官网的文档加上:BeautifulSoup(markup, "html.parser")
结果出现了这样的报错:

在Google搜了下,都是说要导入路径,但是在 Settings -> Project -> Project Interpreter 里是这样的
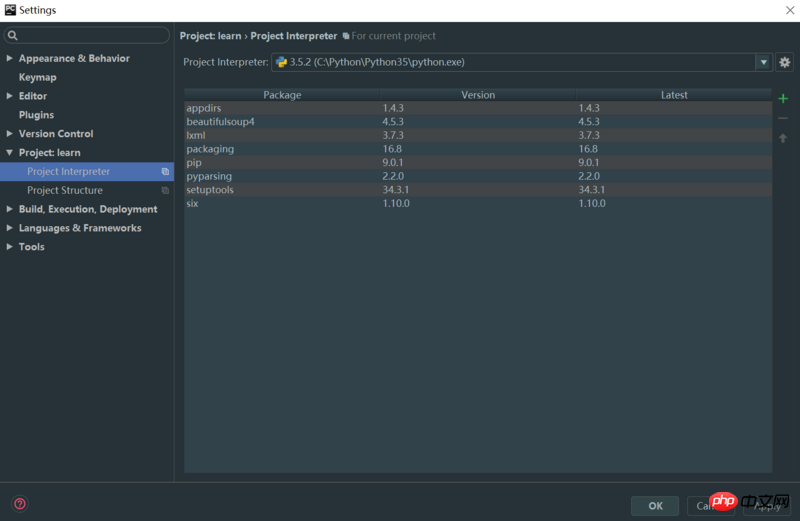
显示BeautifulSoup已经导入了
请问我要怎么做才能解决这个问题呢?
万分感谢!














![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




J'ai regardé le code d'autres personnes et j'ai finalement compris quel était le problème
Ce n'est pas un problème de chemin, mais un problème de passage de paramètres
le balisage est en fait le contenu à analyser, par exemple :
ou
PS. Il n'y a pas de liste de paramètres de fonction dans le document. Je ne sais pas si je la cherche au mauvais endroit...