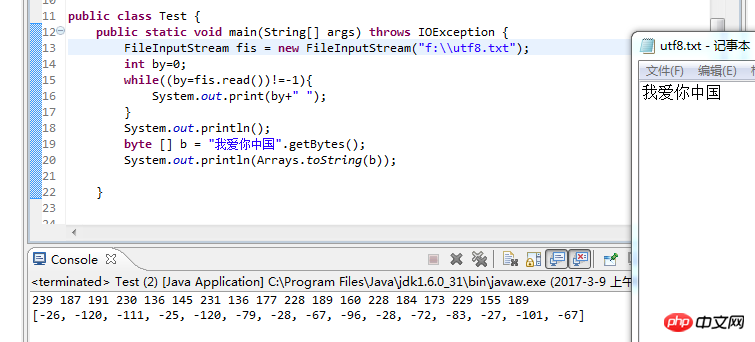
Assurez-vous d'abord que l'encodage est unifié, que l'encodage du fichier est UTF-8, utilisez UTF-8 pour lire le fichier et getBytes transmettez également UTF-8 De plus, n'utilisez pas le Bloc-notes ! N'utilisez pas le Bloc-notes ! N'utilisez pas le Bloc-notes ! Dites les choses importantes trois fois ! ! !
Dans la documentation Java8, il est dit que String.getBytes() est codé selon le jeu de caractères par défaut de la plateforme. Dans le cas de Windows, le jeu de caractères par défaut n'est pas utf-8, mais gbk. Linux dépend de la configuration (je ne sais pas exactement comment).
Encode cette chaîne en une séquence d'octets en utilisant le jeu de caractères par défaut de la plate-forme, en stockant le résultat dans un nouveau tableau d'octets.
Le comportement de cette méthode lorsque cette chaîne ne peut pas être codée dans le jeu de caractères par défaut n'est pas spécifié. La classe CharsetEncoder doit être utilisée lorsqu'un plus grand contrôle sur le processus d'encodage est requis.















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




Assurez-vous d'abord que l'encodage est unifié, que l'encodage du fichier est
UTF-8, utilisezUTF-8pour lire le fichier etgetBytestransmettez égalementUTF-8De plus, n'utilisez pas le Bloc-notes ! N'utilisez pas le Bloc-notes ! N'utilisez pas le Bloc-notes ! Dites les choses importantes trois fois ! ! !
Dans la documentation Java8, il est dit que
String.getBytes()est codé selon le jeu de caractères par défaut de la plateforme. Dans le cas de Windows, le jeu de caractères par défaut n'est pas utf-8, mais gbk. Linux dépend de la configuration (je ne sais pas exactement comment).Portail : String.getBytes()