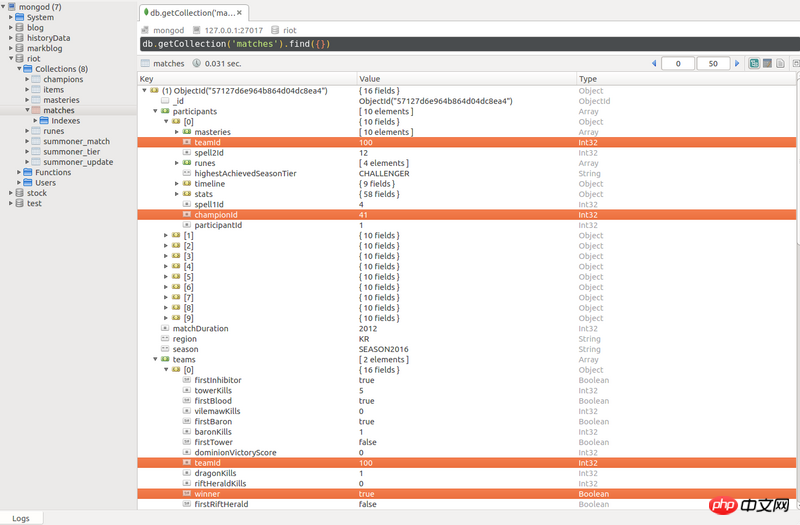
图为mongodb中一条document结构,记录的是LOL的一场比赛对局详情
participants中有10个玩家,前5个teamID为100,后5个teamId为200.比赛的结果哪个队伍取胜是记录在teams那个子文档中的。
我现在的想要查询championId为64(盲僧), 157(亚索)这两个英雄在同一个队伍时的胜利场次,(规定游戏版本号>6.7),查询语句我是这样写的:
db.getCollection('matches').count({
$and: [
{ "matchVersion": {$gte:"6.7"} }
, {
$or:
[
{
$and:
[
{ "participants": {$elemMatch: {"teamId": 100, "championId": 64 } } }
, { "participants": {$elemMatch: {"teamId": 100, "championId": 157 } } }
, { "teams":{ $elemMatch: {"teamId": 100, "winner":true} } }
]
},
{
$and:
[
{ "participants": {$elemMatch: {"teamId": 200, "championId": 64 } } }
, { "participants": {$elemMatch: {"teamId": 200, "championId": 157 } } }
, { "teams":{ $elemMatch: {"teamId": 200, "winner":true} } }
]
}
]
}
]
}
)数据规模为14万,可是执行这样一个查询要花费3秒。已经对对应的查询建立了索引。对查询explain的结果如下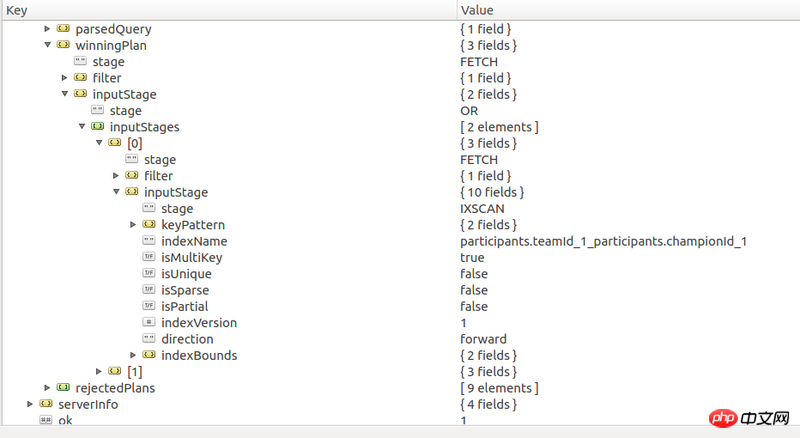
不过好像有些索引也没有用到,比如teams.teamId, teams.winner的复合索引,matchVersion的索引
请问这个查询该如何优化呢?我觉得这个数据规模花费这么久时间应该是我的使用姿势不对吧?















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




L'index de votre plan d'exécution est utilisé, mais on peut voir que l'efficacité n'est pas élevée, mais de nombreuses informations clés sont pliées et le contenu détaillé ne peut pas être vu. La prochaine fois, il est préférable d'envoyer directement le JSON original car il sera plus facile à comprendre. De même, si vous disposez d'un échantillon de données, il est préférable de l'envoyer en JSON, afin que d'autres puissent avoir une copie des données de test lors de la résolution du problème, ce qui sera beaucoup plus pratique.
$andCette chose n'a pas besoin d'apparaître la plupart du temps. Deux éléments parallèles dans un objet sont la relation entre et. Cela simplifie la structure de votre requête et la rend plus facile à consulter pour les autres. Votre requête a donc été simplifiée comme suit :Le dernier et le plus critique problème d'index est qu'il est supposé que l'index qui vous est le plus utile devrait être l'index conjoint de
participants.teamId+participants.championId+teams.teamId+teams.winner+matchVersion. Il doit être filtré en fonction de la filtrabilité des conditions. Mettez en premier lieu de meilleures conditions sexuelles. Supprimez même certaines conditions pour améliorer l’efficacité de l’écriture. Mais cela dépend de la distribution de vos données.Pourquoi votre index n'est-il pas utilisé ? Bien que mongodb 2.6 et versions ultérieures prennent en charge l'indexation croisée et que plusieurs index puissent être utilisés pour satisfaire la même requête, le système d'évaluation du plan d'exécution actuel rend difficile le déclenchement de l'indexation croisée. Essayez donc d'utiliser un index pour satisfaire votre requête.