

Hbase的协处理器

1.起因(Why HBase Coprocessor) HBase作为列族数据库最经常被人诟病的特性包括:无法轻易建立“二级索引”,难以执行求和、计数、排序等操作。比如,在旧版本的(0.92)Hbase中,统计数据表的总行数,需要使用Counter方法,执行一次MapReduce Job才能得到。虽
1.起因(Why HBase Coprocessor)
HBase作为列族数据库最经常被人诟病的特性包括:无法轻易建立“二级索引”,难以执行求和、计数、排序等操作。比如,在旧版本的(
2.灵感来源( Source of Inspration)
HBase协处理器的灵感来自于Jeff Dean 09年的演讲( P66-67)。它根据该演讲实现了类似于bigtable的协处理器,包括以下特性:
- 每个表服务器的任意子表都可以运行代码
- 客户端的高层调用接口(客户端能够直接访问数据表的行地址,多行读写会自动分片成多个并行的RPC调用)
- 提供一个非常灵活的、可用于建立分布式服务的数据模型
- 能够自动化扩展、负载均衡、应用请求路由
3.细节剖析(Implementation)
协处理器分两种类型,系统协处理器可以全局导入region server上的所有数据表,表协处理器即是用户可以指定一张表使用协处理器。协处理器框架为了更好支持其行为的灵活性,提供了两个不同方面的插件。一个是观察者(observer),类似于关系数据库的触发器。另一个是终端(endpoint),动态的终端有点像存储过程。
3.1观察者(Observer)
观察者的设计意图是允许用户通过插入代码来重载协处理器框架的upcall方法,而具体的事件触发的callback方法由HBase的核心代码来执行。协处理器框架处理所有的callback调用细节,协处理器自身只需要插入添加或者改变的功能。
以HBase0.92版本为例,它提供了三种观察者接口:
- RegionObserver:提供客户端的数据操纵事件钩子:Get、Put、Delete、Scan等。
- WALObserver:提供WAL相关操作钩子。
- MasterObserver:提供DDL-类型的操作钩子。如创建、删除、修改数据表等。
这些接口可以同时使用在同一个地方,按照不同优先级顺序执行.用户可以任意基于协处理器实现复杂的HBase功能层。HBase有很多种事件可以触发观察者方法,这些事件与方法从HBase0.92版本起,都会集成在HBase API中。不过这些API可能会由于各种原因有所改动,不同版本的接口改动比较大,具体参考Java Doc。
RegionObserver工作原理,如图1所示。更多关于Observer细节请参见HBaseBook的第9.6.3章节。

图1 RegionObserver工作原理
3.2终端(Endpoint)
终端是动态RPC插件的接口,它的实现代码被安装在服务器端,从而能够通过HBase RPC唤醒。客户端类库提供了非常方便的方法来调用这些动态接口,它们可以在任意时候调用一个终端,它们的实现代码会被目标region远程执行,结果会返回到终端。用户可以结合使用这些强大的插件接口,为HBase添加全新的特性。终端的使用,如下面流程所示:
- 定义一个新的protocol接口,必须继承CoprocessorProtocol.
- 实现终端接口,该实现会被导入region环境执行。
- 继承抽象类BaseEndpointCoprocessor.
- 在客户端,终端可以被两个新的HBase Client API调用 。单个region:HTableInterface.coprocessorProxy(Class
protocol, byte[] row) 。rigons区域:HTableInterface.coprocessorExec(Class protocol, byte[] startKey, byte[] endKey, Batch.Call callable)
整体的终端调用过程范例,如图2所示:
图2 终端调用过程范例
4.编程实践(Code Example)
在该实例中,我们通过计算HBase表中行数的一个实例,来真实感受协处理器 的方便和强大。在旧版的HBase我们需要编写MapReduce代码来汇总数据表中的行数,在0.92以上的版本HBase中,只需要编写客户端的代码即可实现,非常适合用在WebService的封装上。
4.1启用协处理器 Aggregation(Enable Coprocessor Aggregation)
我们有两个方法:1.启动全局aggregation,能过操纵所有的表上的数据。通过修改hbase-site.xml这个文件来实现,只需要添加如下代码:
<span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)"><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(128,0,0)">property</span><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)">></span> <span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)"><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(128,0,0)">name</span><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)">></span>hbase.coprocessor.user.region.classes<span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)"></span><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(128,0,0)">name</span><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)">></span> <span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)"><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(128,0,0)">value</span><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)">></span>org.apache.hadoop.hbase.coprocessor.AggregateImplementation<span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)"></span><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(128,0,0)">value</span><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)">></span> <span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)"></span><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(128,0,0)">property</span><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)">></span></span></span></span>
2.启用表aggregation,只对特定的表生效。通过HBase Shell 来实现。
(1)disable指定表。hbase> disable 'mytable'
(2)添加aggregation hbase> alter 'mytable', METHOD => 'table_att','coprocessor'=>'|org.apache.hadoop.hbase.coprocessor.AggregateImplementation||'
(3)重启指定表 hbase> enable 'mytable'
4.2统计行数代码(Code Snippet)
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.client.coprocessor.AggregationClient;
import org.apache.hadoop.hbase.client.coprocessor.LongColumnInterpreter;
import org.apache.hadoop.hbase.coprocessor.ColumnInterpreter;
import org.apache.hadoop.hbase.util.Bytes;
public class MyAggregationClient {
private static final byte[] TABLE_NAME = Bytes.toBytes("bigtable1w");
private static final byte[] CF = Bytes.toBytes("bd");
public static void main(String[] args) throws Throwable {
Configuration customConf = new Configuration();
customConf.set("hbase.zookeeper.quorum",
"192.168.58.101");
//提高RPC通信时长
customConf.setLong("hbase.rpc.timeout", 600000);
//设置Scan缓存
customConf.setLong("hbase.client.scanner.caching", 1000);
Configuration configuration = HBaseConfiguration.create(customConf);
AggregationClient aggregationClient = new AggregationClient(
configuration);
Scan scan = new Scan();
//指定扫描列族,唯一值
scan.addFamily(CF);
//long rowCount = aggregationClient.rowCount(TABLE_NAME, null, scan);
long rowCount = aggregationClient.rowCount(TableName.valueOf("bigtable1w"), new LongColumnInterpreter(), scan);
System.out.println("row count is " + rowCount);
}
}
4.3 典型例子
协处理器其中的一个作用是使用Observer创建二级索引。先举个实际例子:
我们要查询指定店铺指定客户购买的订单,首先有一张订单详情表,它以被处理后的订单id作为rowkey;其次有一张以客户nick为rowkey的索引表,结构如下:
rowkey family
dp_id+buy_nick1 tid1:null tid2:null ...
dp_id+buy_nick2 tid3:null
...
该表可以通过Coprocessor来构建,实例代码:


- public class TestCoprocessor extends BaseRegionObserver {
- @Override
- public void prePut(final ObserverContextRegionCoprocessorEnvironment> e,
- final Put put, final WALEdit edit, final boolean writeToWAL)
- throws IOException {
- Configuration conf = new Configuration();
- HTable table = new HTable(conf, "index_table");
- ListKeyValue> kv = put.get("data".getBytes(), "name".getBytes());
- IteratorKeyValue> kvItor = kv.iterator();
- while (kvItor.hasNext()) {
- KeyValue tmp = kvItor.next();
- Put indexPut = new Put(tmp.getValue());
- indexPut.add("index".getBytes(), tmp.getRow(), Bytes.toBytes(System.currentTimeMillis()));
- table.put(indexPut);
- }
- table.close();
- }
- }
即继承BaseRegionObserver类,实现prePut方法,在插入订单详情表之前,向索引表插入索引数据。
4.4索引表的使用
先在索引表get索引表,获取tids,然后根据tids查询订单详情表。当有多个查询条件(多张索引表),根据逻辑运算符(and 、or)确定tids。
4.5使用时注意
1.索引表是一张普通的hbase表,为安全考虑需要开启Hlog记录日志。
2.索引表的rowkey最好是不可变量,避免索引表中产生大量的脏数据。
3.如上例子,column是横向扩展的(宽表),rowkey设计除了要考虑region均衡,也要考虑column数量,即表不要太宽。建议不超过3位数。
4.如上代码,一个put操作其实是先后向两张表put数据,为保证一致性,需要考虑异常处理,建议异常时重试。
4.6效率情况
put操作效率不高,如上代码,每插入一条数据需要创建一个新的索引表连接(可以使用htablepool优化),向索引表插入数据。即耗时是双倍的,对hbase的集群的压力也是双倍的。当索引表有多个时,压力会更大。
查询效率比filter高,毫秒级别,因为都是rowkey的查询。
如上是估计的效率情况,需要根据实际业务场景和集群情况而定,最好做预先测试。
4.7Coprocessor二级索引方案优劣
优点:在put压力不大、索引region均衡的情况下,查询很快。
缺点:业务性比较强,若有多个字段的查询,需要建立多张索引表,需要保证多张表的数据一致性,且在hbase的存储和内存上都会有更高的要求

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7461
7461
 15
1376
52
77
11
17
17
15
1376
52
77
11
17
17

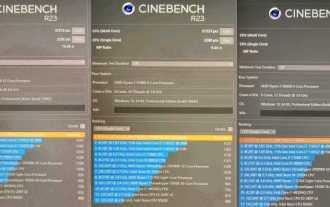 AMD Ryzen 9900X、9700X、9600X プロセッサ Cinebench R23 の実行スコアが公開、平均 10 ~ 15% 増加
Jul 29, 2024 am 11:38 AM
AMD Ryzen 9900X、9700X、9600X プロセッサ Cinebench R23 の実行スコアが公開、平均 10 ~ 15% 増加
Jul 29, 2024 am 11:38 AM
7 月 29 日のこの Web サイトのニュースによると、AMD Ryzen 9000 シリーズ プロセッサが JD.com で予約可能になり、4 つのモデルの最初のバッチが発売され、8 月 15 日に発売される予定です。これらのプロセッサの評価データは発売前日の8月14日に解禁されるが、一部のメディアや機関が事前にサンプルを入手してテストを開始しているため、R99900X、R79700X、R59600Xプロセッサの動作スコアデータは公開されていない。漏洩された。 ▲画像出典:@9550pro 全体として、Zen4 から Zen5 への移行により、シングルコアのパフォーマンスが 10% ~ 15%、マルチコアのパフォーマンスが 10% ~ 13% 向上すると予想されますが、TDP は若干Ryzen 7000 シリーズよりも低く、これは AMD の公式 IPC 改善データとも一致しています。ライゼン
 Jingyue の実測値: AMD R7 8700F、R5 8400F コアレス グラフィックス プロセッサのパフォーマンスは 8700G および 7500F と同等
Apr 06, 2024 am 09:01 AM
Jingyue の実測値: AMD R7 8700F、R5 8400F コアレス グラフィックス プロセッサのパフォーマンスは 8700G および 7500F と同等
Apr 06, 2024 am 09:01 AM
4月5日のこのウェブサイトのニュースによると、Jingyue氏は、先月公開されたAMDR78700FおよびR58400Fコアレスグラフィックスプロセッサが中国に特別に供給されたモデルであることを正式に確認し、ネットワーク全体で最初のテストビデオを公開し、両方ともコアグラフィックスがなく、 TDP 構成はすべて 65W です。スペック的には、AMD Ryzen78700Fは8コア16スレッド、ベース周波数4.1GHz、加速周波数5.05GHzとRyzen78700Gより0.10/0.05GHz低く、16MBのL3キャッシュを搭載しています。 AMD Ryzen58400Fは、周波数4.2~4.75GHzの6コア12スレッド設計を採用しており、R57500Fと比較して、ベース周波数が0.1GHz増加し、加速周波数が0減少しています。
 144コア、3DスタックSRAM:富士通、次世代データセンタープロセッサMONAKAの詳細を発表
Jul 29, 2024 am 11:40 AM
144コア、3DスタックSRAM:富士通、次世代データセンタープロセッサMONAKAの詳細を発表
Jul 29, 2024 am 11:40 AM
7月28日の当サイトのニュースによると、海外メディアTechRaderは、富士通が2027年に出荷予定の「FUJITSU-MONAKA」(以下、MONAKA)プロセッサを詳しく紹介したと報じた。 MONAKACPUは「クラウドネイティブ3Dメニーコア」アーキテクチャをベースとし、Arm命令セットを採用しており、AIコンピューティングに適しており、メインフレームレベルのRAS1を実現できます。富士通は、MONAKAはエネルギー効率と性能の飛躍的な向上を達成すると述べた。超低電圧(ULV)技術などの技術のおかげで、CPUは2027年には競合製品の2倍のエネルギー効率を達成でき、冷却には水冷が必要ない; さらに、プロセッサのアプリケーションパフォーマンスが相手の2倍に達することもあります。命令に関しては、MONAKAにはvectorが搭載されています。
 AMD Ryzen 9 9950X は 6.6 GHz にオーバークロックされ、CineBench R23 は 55296 ポイントの最大スコアを達成しました
Jul 17, 2024 pm 09:49 PM
AMD Ryzen 9 9950X は 6.6 GHz にオーバークロックされ、CineBench R23 は 55296 ポイントの最大スコアを達成しました
Jul 17, 2024 pm 09:49 PM
7 月 16 日のこの Web サイトのニュースによると、AMDXOC チームは、Zen5 Technology Day で招待されたメディアとゲストにオーバークロック Ryzen 99950X プロセッサーをデモンストレーションし、このプロセッサーは液体窒素 (LN2) を使用してオーバークロックされ、CineBenchR23 で 5.5 を超えるスコアを獲得しました。 、消費電力は552Wにもなります。 XOC チームが使用するオーバークロック プラットフォームは、ASUS X670EROG CorsshairGene マザーボードです。これは、オーバークロック プレーヤー向けに特別に設計され、2 つの DDR5DIMM を搭載したマザーボードです。液体窒素を使用した後、Ryzen 99950Xプロセッサーの動作温度は摂氏マイナス90度に下がり、消費電力は552W、CPUは6.4GHzでオーバークロックされ、CineBenchR23のスコアは55296を超えました
 マルチコアが 100,000 を超え、AMD EPYC 9755 プロセッサの CPU-Z 実行スコアが明らかに: EPYC 9654 より 14% 高速
Jul 25, 2024 am 10:46 AM
マルチコアが 100,000 を超え、AMD EPYC 9755 プロセッサの CPU-Z 実行スコアが明らかに: EPYC 9654 より 14% 高速
Jul 25, 2024 am 10:46 AM
7月25日のこのサイトのニュースによると、ソースのHXL(@9550pro)が昨日(7月24日)ツイートし、CPU-Zベンチマークテストで優れた結果を達成したZen5ベースのAMDEPYC9755「Turin」CPUに関する情報を共有しました。 。 AMDEPYC9755 "Turin" CPU 情報 EPYC9755 は、AMD の第 5 世代 EPYC ファミリ製品で、Zen5 アーキテクチャに 128 コアと 256 スレッドを搭載しています。 EPYC9755 プロセッサのベース クロック周波数は 2.70 GHz で、アクセラレーション クロック周波数は 4.10 GHz に達します。前世代と比較して、コア/スレッドの数は 33% 増加し、クロック周波数は 11% 増加しました。 EPYC9755
 AMD、数百万台のRyzenおよびEPYCプロセッサに影響する「Sinkclose」の重大度の高い脆弱性を発表
Aug 10, 2024 pm 10:31 PM
AMD、数百万台のRyzenおよびEPYCプロセッサに影響する「Sinkclose」の重大度の高い脆弱性を発表
Aug 10, 2024 pm 10:31 PM
8月10日の当サイトのニュースによると、AMDは一部のEPYCおよびRyzenプロセッサにコード「CVE-2023-31315」の「Sinkclose」と呼ばれる新たな脆弱性が存在し、世界中の数百万のAMDユーザーが関与する可能性があることを正式に確認したとのこと。では、シンククローズとは何でしょうか? 『WIRED』の報道によると、この脆弱性により侵入者は「システム管理モード(SMM)」で悪意のあるコードを実行することが可能になるという。伝えられるところによると、侵入者はブートキットと呼ばれるマルウェアの一種を使用して相手のシステムを制御する可能性があり、このマルウェアはウイルス対策ソフトウェアでは検出できません。このサイトからの注: システム管理モード (SMM) は、高度な電源管理とオペレーティング システムに依存しない機能を実現するために設計された特別な CPU 動作モードです。
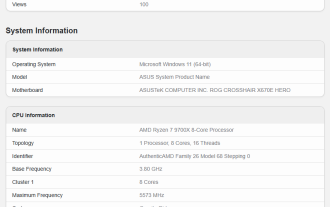 AMD Ryzen 7 9700X プロセッサーが Geekbench に登場: シングルコアの実行スコアは R7 7700X より 14% 高い
Jul 12, 2024 pm 01:59 PM
AMD Ryzen 7 9700X プロセッサーが Geekbench に登場: シングルコアの実行スコアは R7 7700X より 14% 高い
Jul 12, 2024 pm 01:59 PM
7月9日のこのWebサイトのニュースによると、AMD Ryzen 79700Xプロセッサを搭載したASUSテストマシンがGeekbenchデータベースに登場し、ROG CROSSHAIRX670EHEROマザーボードと32GBDDR56000メモリを搭載しました。 AMD Ryzen 79700Xは8コアと16スレッド、3.8GHzの基本周波数、5.5GHzの加速周波数、40MBのキャッシュ(このサイトの注:32MBL3+8MBL2)、65WのTDP設計を備えていますが、AMDがTDPを120Wに増加したというニュースもあります。図に示すように、テスト プラットフォームは、Geekbench6.3.0 で 3312 ポイントと 16431 ポイントのシングル コア スコアとマルチコア スコアを実行しました。これは、R77700 よりも優れています。
 Kirin 8000 プロセッサが Snapdragon シリーズと競合: 誰が王になれるでしょうか?
Mar 25, 2024 am 09:03 AM
Kirin 8000 プロセッサが Snapdragon シリーズと競合: 誰が王になれるでしょうか?
Mar 25, 2024 am 09:03 AM
モバイルインターネットの時代において、スマートフォンは人々の日常生活に欠かせないものになりました。多くの場合、スマートフォンのパフォーマンスはユーザー エクスペリエンスの品質に直接影響します。スマートフォンの「頭脳」であるプロセッサーの性能は特に重要です。市場では、Qualcomm Snapdragon シリーズは常に強力なパフォーマンス、安定性、信頼性の代表格であり、最近では Huawei も独自の Kirin 8000 プロセッサを発売し、優れたパフォーマンスを備えていると言われています。一般ユーザーにとって、性能の良い携帯電話をいかに選ぶかは重要な課題となっている。今日はそうします
