

mongodb入门-8查询3

mongodb入门-8查询3 继续学下mongodb的查询 $or $nor $or或者的意思 只要有一个符合就查出了. $nor与$or相反,只要是$or能够查出来的$nor作为去除的部分. [html] db.user.find() { _id : ObjectId(5198c286c686eb50e2c843b2), name : user0, age : 0 } { _id
mongodb入门-8查询3
继续学下mongodb的查询
$or $nor
$or或者的意思 只要有一个符合就查出了. $nor与$or相反,只要是$or能够查出来的$nor作为去除的部分.
[html]
> db.user.find()
{ "_id" : ObjectId("5198c286c686eb50e2c843b2"), "name" : "user0", "age" : 0 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b3"), "name" : "user1", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 3 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 4 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b7"), "name" : "user5", "age" : 5 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b8"), "name" : "user6", "age" : 6 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b9"), "name" : "user7", "age" : 7 }
{ "_id" : ObjectId("5198c286c686eb50e2c843ba"), "name" : "user8", "age" : 8 }
{ "_id" : ObjectId("5198c286c686eb50e2c843bb"), "name" : "user9", "age" : 9 }
{ "_id" : ObjectId("5198c286c686eb50e2c843bc"), "name" : "user10", "age" : 10 }
{ "_id" : ObjectId("5198c3cac686eb50e2c843bd"), "name" : "user0", "age" : 20 }
> db.user.find({$or:[{name:"user1"},{age:20}]}) -->这里可以看到$or和其它的$开头方法不同,其它一般都是作为一个键的值,这个是之间作为键的,可能这里解释的不是很清楚,大家理解了就好
{ "_id" : ObjectId("5198c286c686eb50e2c843b3"), "name" : "user1", "age" : 1 }
{ "_id" : ObjectId("5198c3cac686eb50e2c843bd"), "name" : "user0", "age" : 20 }
同样$nor就是查询出其它的部分:
[html]
> db.user.find({$nor:[{name:"user1"},{age:20}]})
{ "_id" : ObjectId("5198c286c686eb50e2c843b2"), "name" : "user0", "age" : 0 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 3 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 4 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b7"), "name" : "user5", "age" : 5 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b8"), "name" : "user6", "age" : 6 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b9"), "name" : "user7", "age" : 7 }
{ "_id" : ObjectId("5198c286c686eb50e2c843ba"), "name" : "user8", "age" : 8 }
{ "_id" : ObjectId("5198c286c686eb50e2c843bb"), "name" : "user9", "age" : 9 }
{ "_id" : ObjectId("5198c286c686eb50e2c843bc"), "name" : "user10", "age" : 10 }
$size 查询数组的长度等于给定数组长度的文档
[html]
> db.phone.find()
{ "_id" : ObjectId("5198e20220c9b0dc40419385"), "num" : [ 1, 2, 3 ] }
{ "_id" : ObjectId("5198e21820c9b0dc40419386"), "num" : [ 4, 2, 3 ] }
{ "_id" : ObjectId("5198e22120c9b0dc40419387"), "num" : [ 1, 2, 5 ] }
{ "_id" : ObjectId("5198e51a20c9b0dc40419388"), "state" : 1 }
{ "_id" : ObjectId("519969952b76790566165de2"), "num" : [ 2, 3 ] }
> db.phone.find({num:{$size:4}}) -->num数组长度为4的结果没有
> db.phone.find({num:{$size:3}}) -->长度为3的有三个
{ "_id" : ObjectId("5198e20220c9b0dc40419385"), "num" : [ 1, 2, 3 ] }
{ "_id" : ObjectId("5198e21820c9b0dc40419386"), "num" : [ 4, 2, 3 ] }
{ "_id" : ObjectId("5198e22120c9b0dc40419387"), "num" : [ 1, 2, 5 ] }
$where 自定义的查询
$where的值是一个function,我们可以自己写这个function然后去判断哪些值是我们需要的.它会循环扫描集合中的文档,然后执行函数中的判断,只要我们返回true,此文档就会被查出.但是有一点这个方法的性能不是很好,比如下面的查询我能明显感到一些停顿(与上面讲过的方法比较),有兴趣的考研自己试一下.建议只有在其他$方法不能满足查询的时候,在使用$where查询.
[html]
> db.user.find()
{ "_id" : ObjectId("5198c286c686eb50e2c843b2"), "name" : "user0", "age" : 0 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b3"), "name" : "user1", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 3 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 4 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b7"), "name" : "user5", "age" : 5 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b8"), "name" : "user6", "age" : 6 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b9"), "name" : "user7", "age" : 7 }
{ "_id" : ObjectId("5198c286c686eb50e2c843ba"), "name" : "user8", "age" : 8 }
{ "_id" : ObjectId("5198c286c686eb50e2c843bb"), "name" : "user9", "age" : 9 }
{ "_id" : ObjectId("5198c286c686eb50e2c843bc"), "name" : "user10", "age" : 10 }
{ "_id" : ObjectId("5198c3cac686eb50e2c843bd"), "name" : "user0", "age" : 20 }
> db.user.find({$where:function(){return this.age == 3 || this.age == 4}})
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 3 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 4 }
$type 根据数据类型查询
在mongodb中每一种数据类型都有对应的数字,我们在使用$type的时候需要使用这些数字,文档中给出如下的表示
类型 编号
双精度 1
字符串 2
对象 3
数组 4
二进制数据 5
对象 ID 7
布尔值 8
日期 9
空 10
正则表达式 11
JavaScript 13
符号 14
JavaScript(带范围) 15
32 位整数 16
时间戳 17
64 位整数 18
最小键 255
最大键 127 一段例子代码:
[html]
> db.user.find()
{ "_id" : ObjectId("5198c286c686eb50e2c843b2"), "name" : "user0", "age" : 0 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b3"), "name" : "user1", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 3 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 4 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b7"), "name" : "user5", "age" : 5 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b8"), "name" : "user6", "age" : 6 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b9"), "name" : "user7", "age" : 7 }
{ "_id" : ObjectId("5198c286c686eb50e2c843ba"), "name" : "user8", "age" : 8 }
{ "_id" : ObjectId("5198c286c686eb50e2c843bb"), "name" : "user9", "age" : 9 }
{ "_id" : ObjectId("5198c286c686eb50e2c843bc"), "name" : "user10", "age" : 10 }
{ "_id" : ObjectId("5198c3cac686eb50e2c843bd"), "name" : "user0", "age" : 20 }
{ "_id" : ObjectId("51996ef22b76790566165e47"), "name" : 23, "age" : 33 }
> db.user.find({name:{$type:1}}) -->查找name为双精度的文档
{ "_id" : ObjectId("51996ef22b76790566165e47"), "name" : 23, "age" : 33 }
在命令行中type的一些值是不起作用的,这可能与命令行环境有关系,如果谁清楚这个,还请给我留言.
正则表达式
mongodb中查询也支持正则,跟javascript中的正则基本一样,但是不建议使用,因为性能不算是很好.
[html]
> db.user.find()
{ "_id" : ObjectId("5198c286c686eb50e2c843b2"), "name" : "user0", "age" : 0 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b3"), "name" : "user1", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 3 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 4 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b7"), "name" : "user5", "age" : 5 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b8"), "name" : "user6", "age" : 6 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b9"), "name" : "user7", "age" : 7 }
{ "_id" : ObjectId("5198c286c686eb50e2c843ba"), "name" : "user8", "age" : 8 }
{ "_id" : ObjectId("5198c286c686eb50e2c843bb"), "name" : "user9", "age" : 9 }
{ "_id" : ObjectId("5198c286c686eb50e2c843bc"), "name" : "user10", "age" : 10 }
{ "_id" : ObjectId("5198c3cac686eb50e2c843bd"), "name" : "user0", "age" : 20 }
{ "_id" : ObjectId("51996ef22b76790566165e47"), "name" : 23, "age" : 33 }
> db.user.find({name:/user*/i}) -->查询name以user开头不区分大小写的文档
{ "_id" : ObjectId("5198c286c686eb50e2c843b2"), "name" : "user0", "age" : 0 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b3"), "name" : "user1", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 3 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 4 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b7"), "name" : "user5", "age" : 5 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b8"), "name" : "user6", "age" : 6 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b9"), "name" : "user7", "age" : 7 }
{ "_id" : ObjectId("5198c286c686eb50e2c843ba"), "name" : "user8", "age" : 8 }
{ "_id" : ObjectId("5198c286c686eb50e2c843bb"), "name" : "user9", "age" : 9 }
{ "_id" : ObjectId("5198c286c686eb50e2c843bc"), "name" : "user10", "age" : 10 }
{ "_id" : ObjectId("5198c3cac686eb50e2c843bd"), "name" : "user0", "age" : 20 }
排序
在mongodb中排序很简单,使用sort方法,传递给它你想按照哪个字段的哪种方式排序即可.这里1代表升序,-1代表降序.
[html]
> db.user.find()
{ "_id" : ObjectId("5198c286c686eb50e2c843b2"), "name" : "user0", "age" : 0 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b3"), "name" : "user1", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 3 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 4 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b7"), "name" : "user5", "age" : 5 }
> db.user.find().sort({age:1})
{ "_id" : ObjectId("5198c286c686eb50e2c843b2"), "name" : "user0", "age" : 0 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b3"), "name" : "user1", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 3 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 4 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b7"), "name" : "user5", "age" : 5 }
> db.user.find().sort({age:-1})
{ "_id" : ObjectId("5198c286c686eb50e2c843b7"), "name" : "user5", "age" : 5 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 4 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 3 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b3"), "name" : "user1", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b2"), "name" : "user0", "age" : 0 }
group 分组查询
mongodb中的group可以实现类似关系型数据库中的分组的功能,但是mongodb中的group远比关系型数据库中的group强大,可以实现map-reduce功能,至于map-reduce读者自己百度吧,现在比较火.
group中的json参数类似这样{key:{字段:1},initial:{变量:初始值},$reduce:function(doc,prev){函数代码}}.
其中的字段代表,需要按哪个字段分组.变量表示这一个分组中会使用的变量,并且给一个初始值.可以在后面的$reduce函数中使用.$reduce的两个参数,分别代表当前的文档和上个文档执行完函数后的结果.如下我们按年龄分组,同级不同年龄的用户的多少:
[html]
> db.user.find()
{ "_id" : ObjectId("5198c286c686eb50e2c843b2"), "name" : "user0", "age" : 0 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b3"), "name" : "user1", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b7"), "name" : "user5", "age" : 2 }
> db.user.group({key:{age:1},initial:{count:0},$reduce:function(doc,prev){prev.count++}})
[
{
"age" : 0,
"count" : 1
},
{
"age" : 1,
"count" : 3
},
{
"age" : 2,
"count" : 2
}
]
group更加详细的介绍请看http://www.2cto.com/database/201305/212159.html这篇文章
distinct
去除查询结果中的重复数据,对原有数据不会产生影响,返回的结果是一个数组.
[html]
> db.user.find()
{ "_id" : ObjectId("5198c286c686eb50e2c843b2"), "name" : "user0", "age" : 0 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b3"), "name" : "user1", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b7"), "name" : "user5", "age" : 2 }
> db.user.distinct("age")
[ 0, 1, 2 ]
分页查询
在mongodb中实现分页比较简单,需要使用到skip 和limit方法.skip表示跳过前面的几个文档,limit表示显示几个文档.
[html]
> db.user.find()
{ "_id" : ObjectId("5198c286c686eb50e2c843b2"), "name" : "user0", "age" : 0 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b3"), "name" : "user1", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b7"), "name" : "user5", "age" : 2 }
> db.user.find().skip(2).limit(3) -->跳过前两个文档查询后面的三个文档,经过测试这两个方法的使用顺序没有影响
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 1 }
> db.user.find().limit(3).skip(2)
{ "_id" : ObjectId("5198c286c686eb50e2c843b4"), "name" : "user2", "age" : 2 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b5"), "name" : "user3", "age" : 1 }
{ "_id" : ObjectId("5198c286c686eb50e2c843b6"), "name" : "user4", "age" : 1 }

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7504
7504
 15
1378
52
78
11
19
55
15
1378
52
78
11
19
55

 ワンクリックでPPTを生成!キミ: まずは「PPT出稼ぎ労働者」を普及させましょう
Aug 01, 2024 pm 03:28 PM
ワンクリックでPPTを生成!キミ: まずは「PPT出稼ぎ労働者」を普及させましょう
Aug 01, 2024 pm 03:28 PM
キミ: たった 1 文の PPT がわずか 10 秒で完成します。 PPTはとても面倒です!会議を開催するには PPT が必要であり、週次報告書を作成するには PPT が必要であり、投資を勧誘するには PPT を提示する必要があり、不正行為を告発するには PPT を送信する必要があります。大学は、PPT 専攻を勉強するようなものです。授業中に PPT を見て、授業後に PPT を行います。おそらく、デニス オースティンが 37 年前に PPT を発明したとき、PPT がこれほど普及する日が来るとは予想していなかったでしょう。 PPT 作成の大変な経験を話すと涙が出ます。 「20 ページを超える PPT を作成するのに 3 か月かかり、何十回も修正しました。PPT を見ると吐きそうになりました。」 「ピーク時には 1 日に 5 枚の PPT を作成し、息をすることさえありました。」 PPTでした。」 即席の会議をするなら、そうすべきです
 ベアメタルから 700 億のパラメータを備えた大規模モデルまで、チュートリアルとすぐに使えるスクリプトがここにあります
Jul 24, 2024 pm 08:13 PM
ベアメタルから 700 億のパラメータを備えた大規模モデルまで、チュートリアルとすぐに使えるスクリプトがここにあります
Jul 24, 2024 pm 08:13 PM
LLM が大量のデータを使用して大規模なコンピューター クラスターでトレーニングされていることはわかっています。このサイトでは、LLM トレーニング プロセスを支援および改善するために使用される多くの方法とテクノロジが紹介されています。今日、私たちが共有したいのは、基礎となるテクノロジーを深く掘り下げ、オペレーティング システムさえ持たない大量の「ベア メタル」を LLM のトレーニング用のコンピューター クラスターに変える方法を紹介する記事です。この記事は、機械がどのように考えるかを理解することで一般的な知能の実現に努めている AI スタートアップ企業 Imbue によるものです。もちろん、オペレーティング システムを持たない大量の「ベア メタル」を LLM をトレーニングするためのコンピューター クラスターに変換することは、探索と試行錯誤に満ちた簡単なプロセスではありませんが、Imbue は最終的に 700 億のパラメータを備えた LLM のトレーニングに成功しました。プロセスが蓄積する
 AIの活用 | AIが一人暮らしの女の子の生活ビデオブログを作成、3日間で数万件の「いいね!」を獲得
Aug 07, 2024 pm 10:53 PM
AIの活用 | AIが一人暮らしの女の子の生活ビデオブログを作成、3日間で数万件の「いいね!」を獲得
Aug 07, 2024 pm 10:53 PM
Machine Power Report 編集者: Yang Wen 大型モデルや AIGC に代表される人工知能の波は、私たちの生活や働き方を静かに変えていますが、ほとんどの人はまだその使い方を知りません。そこで、直感的で興味深く、簡潔な人工知能のユースケースを通じてAIの活用方法を詳しく紹介し、皆様の思考を刺激するコラム「AI in Use」を立ち上げました。また、読者が革新的な実践的な使用例を提出することも歓迎します。ビデオリンク: https://mp.weixin.qq.com/s/2hX_i7li3RqdE4u016yGhQ 最近、Xiaohongshu で一人暮らしの女の子の生活 vlog が人気になりました。イラスト風のアニメーションといくつかの癒しの言葉を組み合わせれば、数日で簡単に習得できます。
 ソラレベルのプレイヤーがまた登場します!ソラとケリングと比較してみました。
Aug 02, 2024 am 10:19 AM
ソラレベルのプレイヤーがまた登場します!ソラとケリングと比較してみました。
Aug 02, 2024 am 10:19 AM
ソラが出てこられなかったとき、OpenAI の敵対者は武器を使用して街路を破壊しました。 Sora を使用しないと本当に盗まれます。本日、サンフランシスコのスタートアップ LumaAI が切り札となり、新世代の AI ビデオ生成モデル DreamMachine を発表しました。無料で誰でも利用できます。レポートによると、このモデルは、Sora に匹敵する効果を持つ、簡単なテキストの説明に基づいて、高品質でリアルなビデオを生成できます。このニュースが発表されるとすぐに、多くのユーザーがそれを試してみようと公式ウェブサイトに殺到しました。関係者は、このモデルはわずか 2 分で 120 フレームのビデオを生成できると主張していますが、多くのユーザーはアクセス数が急増したため、公式 Web サイトで何時間も待たされています。 Luma の製品成長責任者である BarkleyDai 氏は Discord についてコメントする必要がありました
 Kuaishou Keling AI は世界中で内部テストに完全にオープンし、モデル効果が再びアップグレードされました
Jul 24, 2024 pm 08:34 PM
Kuaishou Keling AI は世界中で内部テストに完全にオープンし、モデル効果が再びアップグレードされました
Jul 24, 2024 pm 08:34 PM
7 月 24 日、Kuaishou ビデオ生成大型モデル Keling AI は、基本モデルが再度アップグレードされ、内部テストが完全にオープンになったと発表しました。 Kuaishou 氏は、より多くのユーザーが Keling AI を使用できるようにし、クリエイターのさまざまなレベルの使用ニーズをより適切に満たすために、今後は完全にオープンな内部テストに基づいて、さまざまなカテゴリの会員システムを正式に開始すると述べました。メンバーに対応する専用の機能サービスを提供します。同時に、Keling AI の基本モデルも再度アップグレードされ、ユーザー エクスペリエンスがさらに向上しました。ユーザーエクスペリエンスをさらに向上させるために、Keling AI は 1 か月以上前にリリースされて以来、何度もアップグレードされ、今回のメンバーシップ システムの開始により、Keling AI の基本モデル効果は一度アップグレードされました。再び変身を遂げた。 1つ目は、ベーシックモデルのアップグレードにより画質が大幅に向上したことです。
 行列とグラフの間には等価関係があるということを、ライン生成を学んでいたときになぜ知らなかったのでしょうか?
Aug 19, 2024 pm 04:52 PM
行列とグラフの間には等価関係があるということを、ライン生成を学んでいたときになぜ知らなかったのでしょうか?
Aug 19, 2024 pm 04:52 PM
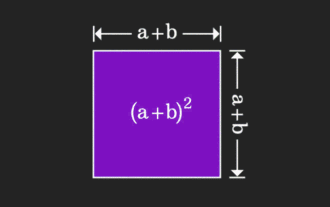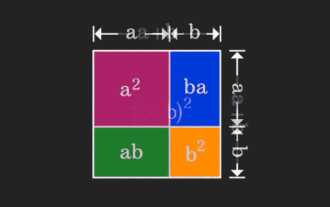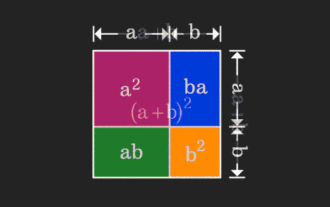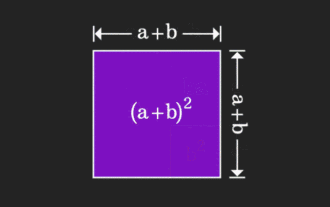
マトリックスはわかりにくいですが、別の視点から見ると違うのかもしれません。数学を学ぶとき、私たちは学んだ知識の難しさや抽象性にイライラすることがよくありますが、視点を変えるだけで問題に対するシンプルで直感的な解決策を見つけることができることがあります。たとえば、私たちが子供の頃に二乗和 (a+b)² の公式を習ったとき、それがなぜ a²+2ab+b² に等しいのか理解できなかったかもしれません。この本と先生は、私たちにこのように覚えるように言いました。ある日、このアニメーションを見るまでは、幾何学的な観点からそれを理解できることに突然気づきました。ここで、この啓発的な感覚が再び起こります。非負行列は、対応する有向グラフに等価的に変換できるのです。以下の図に示すように、左側の 3×3 行列は実際には次のようになります。
 体験しようと70万人が殺到!動画生成の新たな王様「Keling AI」が再びアップグレード
Jul 20, 2024 am 05:09 AM
体験しようと70万人が殺到!動画生成の新たな王様「Keling AI」が再びアップグレード
Jul 20, 2024 am 05:09 AM
AIが作るショートドラマの時代が本当に来るのか?最近、さまざまな動画生成AIが公開するデモは目を見張るものがあります。ミームや長さのパズルで遊ぶことから、実際の物理的ロジックに注意を払うことまで、人工知能の無限の創造性を区別するのは難しく、それらすべてがソラと競争しなければなりません。このとき、誰かが突然一歩を踏み出して、現実的な光と影の効果から、豊かな想像力、要素まで、「映画レベル」のパフォーマンスを作成しました。それはすべて可能です。予想外なことに、AI の目から見て、ジョーカーの神経を保てなくなるのは実際にはバットマンです。出典: https://x.com/blizaine/status/18
 Doubao Big Model Team が、VLM キャプション評価の信頼性を向上させるための新しい詳細画像キャプション評価ベンチマークをリリース
Jul 18, 2024 pm 08:10 PM
Doubao Big Model Team が、VLM キャプション評価の信頼性を向上させるための新しい詳細画像キャプション評価ベンチマークをリリース
Jul 18, 2024 pm 08:10 PM
AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出電子メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com 現在の視覚言語モデル (VLM) は、主に QA の質問と回答形式を通じてパフォーマンス評価を実行しますが、信頼できる評価方法など、モデルの基本的な理解の評価が不足しています。詳細画像キャプションのパフォーマンス。この問題を受けて、中国科学院は、
