

cvKMeans2均值聚类分析+代码解析+灰度彩色图像聚类

1 K-均聚类算法的基本思想 K-均聚类算法 是著名的划分聚类分割方法。划分方法的基本思想是:给定一个有N个元组或者纪录的数据集,分裂法将构造K个分组,每一个分组就代表一个聚类,KN。而且这K个分组满足下列条件:(1) 每一个分组至少包含一个数据纪录;(
1 K-均值聚类算法的基本思想
K-均值聚类算法是著名的划分聚类分割方法。划分方法的基本思想是:给定一个有N个元组或者纪录的数据集,分裂法将构造K个分组,每一个分组就代表一个聚类,K K-means算法的工作原理:算法首先随机从数据集中选取 K个点作为初始聚类中心,然后计算各个样本到聚类中心的距离,把样本归到离它最近的那个聚类中心所在的类。计算新形成的每一个聚类的数据对象的平均值来得到新的聚类中心,如果相邻两次的聚类中心没有任何变化,说明样本调整结束,聚类准则函数 已经收敛。本算法的一个特点是在每次迭代中都要考察每个样本的分类是否正确。若不正确,就要调整,在全部样本调整完后,再修改聚类中心,进入下一次迭代。这个过程将不断重复直到满足某个终止条件,终止条件可以是以下任何一个: (1)没有对象被重新分配给不同的聚类。 (2)聚类中心再发生变化。 (3)误差平方和局部最小。 K-means聚类算法的一般步骤: (1)从 n个数据对象任意选择 k 个对象作为初始聚类中心; (2)循环(3)到(4)直到每个聚类不再发生变化为止; (3)根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分; (4)重新计算每个(有变化)聚类的均值(中心对象),直到聚类中心不再变化。这种划分使得下式最小 K-均值聚类法的缺点: (1)在 K-means 算法中 K 是事先给定的,这个 K 值的选定是非常难以估计的。 (2)在 K-means 算法中,首先需要根据初始聚类中心来确定一个初始划分,然后对初始划分进行优化。 (3) K-means算法需要不断地进行样本分类调整不断地计算调整后的新的聚类中心因此当数据量非常大时算法的时间开销是非常大的。 (4)K-means算法对一些离散点和初始k值敏感,不同的距离初始值对同样的数据样本可能得到不同的结果。
2 OpenCV中K均值函数分析:
CV_IMPL int
cvKMeans2( const CvArr* _samples, intcluster_count, CvArr* _labels,
CvTermCriteria termcrit, int attempts, CvRNG*,
intflags, CvArr* _centers, double* _compactness )
_samples:输入样本的浮点矩阵,每个样本一行,如对彩色图像进行聚类,每个通道一行,CV_32FC3
cluster_count:所给定的聚类数目
_labels:输出整数向量:每个样本对应的类别标识,其范围为0- (cluster_count-1),必须满足以下条件:
cv::Mat data = cv::cvarrToMat(_samples),labels = cv::cvarrToMat(_labels);
CV_Assert(labels.isContinuous() && labels.type() == CV_32S &&
(labels.cols == 1 || labels.rows == 1)&&
labels.cols + labels.rows - 1 ==data.rows );
termcrit:指定聚类的最大迭代次数和/或精度(两次迭代引起的聚类中心的移动距离),其执行 k-means 算法搜索 cluster_count 个类别的中心并对样本进行分类,输出 labels(i) 为样本i的类别标识。其中CvTermCriteria为OpenCV中的迭代算法的终止准则,其结构如下:
#define CV_TERMCRIT_ITER 1
#define CV_TERMCRIT_NUMBER CV_TERMCRIT_ITER
#define CV_TERMCRIT_EPS 2
typedef struct CvTermCriteria
{
int type; int max_iter; double epsilon;
} CvTermCriteria;
max_iter:最大迭代次数。 epsilon:结果的精确性 。
attempts:
flags: 与labels和centers相关
_centers: 输出聚类中心,可以不用设置输出聚类中心,但如果想输出聚类中心必须满足以下条件:
CV_Assert(!centers.empty() );
CV_Assert( centers.rows == cluster_count );
CV_Assert( centers.cols ==data.cols );
CV_Assert( centers.depth() == data.depth() );
聚类中心的获得方式:(以三类为例)
double cent0 = centers->data.fl[0];
double cent1 = centers->data.fl[1];
double cent2 = centers->data.fl[2];
CV_IMPL int
cvKMeans2( const CvArr* _samples,int cluster_count,CvArr* _labels,
CvTermCriteriatermcrit, intattempts, CvRNG*,
int flags, CvArr* _centers, double* _compactness )
{
cv::Mat data = cv::cvarrToMat(_samples), labels= cv::cvarrToMat(_labels), centers;
if( _centers )
{
centers= cv::cvarrToMat(_centers);
// 将centers和data转换为行向量
centers= centers.reshape(1);
data= data.reshape(1);
// centers必须满足的条件
CV_Assert(!centers.empty());
CV_Assert(centers.rows== cluster_count );
CV_Assert(centers.cols== data.cols);
CV_Assert(centers.depth()== data.depth());
}
// labels必须满足的条件
CV_Assert(labels.isContinuous()&& labels.type()== CV_32S &&
(labels.cols == 1 || labels.rows == 1) &&
labels.cols + labels.rows - 1 == data.rows );
// 调用kmeans实现聚类,如果定义了输出聚类中心矩阵,那么输出centers
double compactness = cv::kmeans(data, cluster_count, labels,termcrit, attempts,
flags, _centers? cv::_OutputArray(centers) : cv::_OutputArray() );
if( _compactness )
*_compactness= compactness;
return 1;
}
double cv::kmeans( InputArray_data, int K,
InputOutputArray_bestLabels,
TermCriteriacriteria, intattempts,
intflags, OutputArray_centers )
{
const int SPP_TRIALS =3;
Mat data = _data.getMat();
// 判断data是否为行向量
bool isrow = data.rows == 1 && data.channels() > 1;
int N = !isrow ? data.rows : data.cols;
int dims = (!isrow? data.cols: 1)*data.channels();
int type = data.depth();
attempts= std::max(attempts, 1);
CV_Assert(data.dimstype == CV_32F && K> 0 );
CV_Assert(N >= K);
_bestLabels.create(N, 1, CV_32S, -1, true);
Mat _labels, best_labels = _bestLabels.getMat();
// 使用已初始化的labels
if( flags & CV_KMEANS_USE_INITIAL_LABELS)
{
CV_Assert((best_labels.cols== 1 || best_labels.rows== 1) &&
best_labels.cols*best_labels.rows == N&&
best_labels.type() == CV_32S&&
best_labels.isContinuous());
best_labels.copyTo(_labels);
}
else
{
if( !((best_labels.cols== 1 || best_labels.rows== 1) &&
best_labels.cols*best_labels.rows == N&&
best_labels.type() == CV_32S&&
best_labels.isContinuous()))
best_labels.create(N, 1, CV_32S);
_labels.create(best_labels.size(), best_labels.type());
}
int* labels = _labels.ptrint>();
Mat centers(K, dims, type), old_centers(K, dims, type), temp(1, dims, type);
vectorint> counters(K);
vectorVec2f> _box(dims);
Vec2f* box = &_box[0];
double best_compactness = DBL_MAX,compactness = 0;
RNG&rng = theRNG();
int a, iter, i, j, k;
// 对终止条件进行修改
if( criteria.type& TermCriteria::EPS)
criteria.epsilon = std::max(criteria.epsilon, 0.);
else
criteria.epsilon = FLT_EPSILON;
criteria.epsilon *= criteria.epsilon;
if( criteria.type& TermCriteria::COUNT)
criteria.maxCount = std::min(std::max(criteria.maxCount, 2), 100);
else
criteria.maxCount = 100;
// 聚类数目为1类的时候
if( K == 1 )
{
attempts= 1;
criteria.maxCount = 2;
}
const float* sample = data.ptrfloat>(0);
for( j = 0; j dims; j++ )
box[j] = Vec2f(sample[j], sample[j]);
for( i = 1; i N; i++ )
{
sample= data.ptrfloat>(i);
for( j = 0; j dims; j++ )
{
floatv = sample[j];
box[j][0] = std::min(box[j][0], v);
box[j][1] = std::max(box[j][1], v);
}
}
for( a = 0; a attempts; a++ )
{
double max_center_shift = DBL_MAX;
for( iter = 0;; )
{
swap(centers, old_centers);
/*enum
{
KMEANS_RANDOM_CENTERS=0, // Chooses random centers for k-Meansinitialization
KMEANS_PP_CENTERS=2, // Usesk-Means++ algorithm for initialization
KMEANS_USE_INITIAL_LABELS=1 // Uses the user-provided labels for K-Meansinitialization
};*/
if(iter == 0 && (a > 0 || !(flags& KMEANS_USE_INITIAL_LABELS)) )
{
if(flags & KMEANS_PP_CENTERS)
generateCentersPP(data, centers, K, rng, SPP_TRIALS);
else
{
for(k = 0; kK; k++)
generateRandomCenter(_box, centers.ptrfloat>(k), rng);
}
}
else
{
if(iter == 0 && a == 0 && (flags& KMEANS_USE_INITIAL_LABELS) )
{
for(i = 0; iN; i++)
CV_Assert( (unsigned)labels[i] unsigned)K);
}
//compute centers
centers= Scalar(0);
for(k = 0; kK; k++)
counters[k] = 0;
for(i = 0; iN; i++)
{
sample= data.ptrfloat>(i);
k= labels[i];
float*center = centers.ptrfloat>(k);
j=0;
#ifCV_ENABLE_UNROLLED
for(;j dims- 4; j += 4 )
{
float t0 = center[j] + sample[j];
float t1 = center[j+1] + sample[j+1];
center[j] = t0;
center[j+1] = t1;
t0 = center[j+2] + sample[j+2];
t1 = center[j+3] + sample[j+3];
center[j+2] = t0;
center[j+3] = t1;
}
#endif
for(; j dims;j++ )
center[j] += sample[j];
counters[k]++;
}
if(iter > 0 )
max_center_shift= 0;
for(k = 0; kK; k++)
{
if(counters[k]!= 0 )
continue;
// if somecluster appeared to be empty then:
// 1. find the biggest cluster
// 2. find the farthest from the center pointin the biggest cluster
// 3. exclude the farthest point from thebiggest cluster and form a new 1-point cluster.
intmax_k = 0;
for(int k1 = 1; k1 K; k1++ )
{
if( counters[max_k] counters[k1] )
max_k = k1;
}
doublemax_dist = 0;
intfarthest_i = -1;
float*new_center = centers.ptrfloat>(k);
float*old_center = centers.ptrfloat>(max_k);
float*_old_center = temp.ptrfloat>();// normalized
floatscale = 1.f/counters[max_k];
for(j = 0; jdims; j++)
_old_center[j] = old_center[j]*scale;
for(i = 0; iN; i++)
{
if(labels[i]!= max_k )
continue;
sample = data.ptrfloat>(i);
double dist = normL2Sqr_(sample,_old_center, dims);
if( max_dist dist )
{
max_dist = dist;
farthest_i = i;
}
}
counters[max_k]--;
counters[k]++;
labels[farthest_i] = k;
sample= data.ptrfloat>(farthest_i);
for(j = 0; jdims; j++)
{
old_center[j] -= sample[j];
new_center[j] += sample[j];
}
}
for(k = 0; kK; k++)
{
float*center = centers.ptrfloat>(k);
CV_Assert(counters[k]!= 0 );
floatscale = 1.f/counters[k];
for(j = 0; jdims; j++)
center[j] *= scale;
if(iter > 0 )
{
double dist = 0;
const float* old_center = old_centers.ptrfloat>(k);
for( j = 0; j dims; j++ )
{
double t = center[j] - old_center[j];
dist += t*t;
}
max_center_shift= std::max(max_center_shift, dist);
}
}
}
if(++iter == MAX(criteria.maxCount,2) || max_center_shift criteria.epsilon)
break;
// assignlabels
Matdists(1, N,CV_64F);
double*dist = dists.ptrdouble>(0);
parallel_for_(Range(0, N),
KMeansDistanceComputer(dist,labels, data,centers));
compactness= 0;
for(i = 0; iN; i++)
{
compactness+= dist[i];
}
}
if( compactness best_compactness)
{
best_compactness= compactness;
if(_centers.needed())
centers.copyTo(_centers);
_labels.copyTo(best_labels);
}
}
return best_compactness;
}
3 采用cvKMeans2对灰度图像进行聚类分析
//灰度图像聚类分析
BOOL GrayImageSegmentByKMeans2(const IplImage* pImg, IplImage*pResult, intsortFlag)
{
assert(pImg != NULL&& pImg->nChannels== 1);
//创建样本矩阵,CV_32FC1代表位浮点通道(灰度图像)
CvMat*samples = cvCreateMat((pImg->width)* (pImg->height),1, CV_32FC1);
//创建类别标记矩阵,CV_32SF1代表位整型通道
CvMat*clusters = cvCreateMat((pImg->width)* (pImg->height),1, CV_32SC1);
//创建类别中心矩阵
CvMat*centers = cvCreateMat(nClusters, 1, CV_32FC1);
// 将原始图像转换到样本矩阵
{
intk = 0;
CvScalars;
for(int i = 0; i pImg->width; i++)
{
for(int j=0;j pImg->height; j++)
{
s.val[0] = (float)cvGet2D(pImg, j, i).val[0];
cvSet2D(samples,k++, 0, s);
}
}
}
//开始聚类,迭代次,终止误差.0
cvKMeans2(samples, nClusters,clusters, cvTermCriteria(CV_TERMCRIT_ITER + CV_TERMCRIT_EPS,100, 1.0), 1, 0, 0, centers);
// 无需排序直接输出时
if (sortFlag == 0)
{
intk = 0;
intval = 0;
floatstep = 255 / ((float)nClusters - 1);
CvScalars;
for(int i = 0; i pImg->width; i++)
{
for(int j = 0;j pImg->height; j++)
{
val = (int)clusters->data.i[k++];
s.val[0] = 255- val * step;//这个是将不同类别取不同的像素值,
cvSet2D(pResult,j, i, s); //将每个像素点赋值
}
}
returnTRUE;
}
4 利用OpenCV对彩色图像进行颜色聚类:
BOOL ColorImageSegmentByKMeans2(const IplImage* img, IplImage* pResult, int sortFlag)
{
assert(img != NULL&& pResult != NULL);
assert(img->nChannels== 3 && pResult->nChannels == 1);
int i,j;
CvMat*samples=cvCreateMat((img->width)*(img->height),1,CV_32FC3);//创建样本矩阵,CV_32FC3代表位浮点通道(彩色图像)
CvMat*clusters=cvCreateMat((img->width)*(img->height),1,CV_32SC1);//创建类别标记矩阵,CV_32SF1代表位整型通道
int k=0;
for (i=0;iimg->width;i++)
{
for(j=0;jimg->height;j++)
{
CvScalars;
//获取图像各个像素点的三通道值(RGB)
s.val[0]=(float)cvGet2D(img,j,i).val[0];
s.val[1]=(float)cvGet2D(img,j,i).val[1];
s.val[2]=(float)cvGet2D(img,j,i).val[2];
cvSet2D(samples,k++,0,s);//将像素点三通道的值按顺序排入样本矩阵
}
}
cvKMeans2(samples,nClusters,clusters,cvTermCriteria(CV_TERMCRIT_ITER,100,1.0));//开始聚类,迭代次,终止误差.0
k=0;
int val=0;
float step=255/(nClusters-1);
for (i=0;iimg->width;i++)
{
for(j=0;jimg->height;j++)
{
val=(int)clusters->data.i[k++];
CvScalars;
s.val[0]=255-val*step;//这个是将不同类别取不同的像素值,
cvSet2D(pResult,j,i,s); //将每个像素点赋值
}
}
cvReleaseMat(&samples);
cvReleaseMat(&clusters);
return TRUE;
}

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7467
7467
 15
1376
52
77
11
19
20
15
1376
52
77
11
19
20

 Oracle エラー 3114 の詳細な説明: 迅速に解決する方法
Mar 08, 2024 pm 02:42 PM
Oracle エラー 3114 の詳細な説明: 迅速に解決する方法
Mar 08, 2024 pm 02:42 PM
Oracle エラー 3114 の詳細な説明: 迅速に解決する方法、具体的なコード例が必要です Oracle データベースの開発および管理中に、さまざまなエラーが頻繁に発生しますが、その中でもエラー 3114 は比較的一般的な問題です。エラー 3114 は通常、データベース接続に問題があることを示します。これは、ネットワーク障害、データベース サービスの停止、または不適切な接続文字列設定が原因である可能性があります。この記事では、エラー 3114 の原因とこの問題を迅速に解決する方法を詳しく説明し、特定のコードを添付します
 PHPにおけるmidpointの意味と使い方の分析
Mar 27, 2024 pm 08:57 PM
PHPにおけるmidpointの意味と使い方の分析
Mar 27, 2024 pm 08:57 PM
【PHPにおけるミッドポイントの意味と使い方の分析】 PHPでは、ミッドポイント(.)は2つの文字列やオブジェクトのプロパティやメソッドを接続するためによく使われる演算子です。この記事では、PHP における中間点の意味と使用法を詳しく掘り下げ、具体的なコード例を示して説明します。 1. 文字列中間点演算子の接続 PHP での最も一般的な使用法は、2 つの文字列を接続することです。 2 つの文字列の間に . を置くと、それらをつなぎ合わせて新しい文字列を形成できます。 $string1=&qu
 解析ワームホール NTT: あらゆるトークンのオープン フレームワーク
Mar 05, 2024 pm 12:46 PM
解析ワームホール NTT: あらゆるトークンのオープン フレームワーク
Mar 05, 2024 pm 12:46 PM
Wormhole は、ブロックチェーンの相互運用性のリーダーであり、所有権、制御、許可のないイノベーションを優先する、回復力があり、将来性のある分散システムの作成に重点を置いています。このビジョンの基盤は、技術的専門知識、倫理原則、コミュニティの連携への取り組みであり、シンプルさ、明確さ、そして幅広いマルチチェーン ソリューションで相互運用性の状況を再定義します。ゼロ知識証明、スケーリング ソリューション、機能豊富なトークン標準の台頭により、ブロックチェーンはより強力になり、相互運用性の重要性がますます高まっています。この革新的なアプリケーション環境では、新しいガバナンス システムと実用的な機能が、ネットワーク全体の資産に前例のない機会をもたらします。プロトコル構築者は現在、この新たなマルチチェーンでどのように運用するかに取り組んでいます。
 Linux の「.a」ファイルを作成して実行する
Mar 20, 2024 pm 04:46 PM
Linux の「.a」ファイルを作成して実行する
Mar 20, 2024 pm 04:46 PM
Linux オペレーティング システムでファイルを操作するには、開発者がファイル、コード、プログラム、スクリプトなどを効率的に作成および実行できるようにするさまざまなコマンドとテクニックを使用する必要があります。 Linux 環境では、拡張子「.a」を持つファイルは静的ライブラリとして非常に重要です。これらのライブラリはソフトウェア開発において重要な役割を果たし、開発者が複数のプログラム間で共通の機能を効率的に管理および共有できるようにします。 Linux 環境で効果的なソフトウェア開発を行うには、「.a」ファイルの作成方法と実行方法を理解することが重要です。この記事では、Linux の「.a」ファイルのインストールと構成方法を包括的に紹介します。Linux の「.a」ファイルの定義、目的、構造、作成および実行方法について見てみましょう。 Lとは何ですか
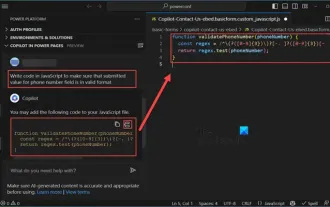 Copilot を使用してコードを生成する方法
Mar 23, 2024 am 10:41 AM
Copilot を使用してコードを生成する方法
Mar 23, 2024 am 10:41 AM
プログラマーとして、私はコーディング体験を簡素化するツールに興奮しています。人工知能ツールの助けを借りて、デモ コードを生成し、要件に応じて必要な変更を加えることができます。 Visual Studio Code に新しく導入された Copilot ツールを使用すると、自然言語によるチャット対話を備えた AI 生成コードを作成できます。機能を説明することで、既存のコードの意味をより深く理解できます。 Copilot を使用してコードを生成するにはどうすればよいですか?始めるには、まず最新の PowerPlatformTools 拡張機能を入手する必要があります。これを実現するには、拡張機能のページに移動し、「PowerPlatformTool」を検索して、[インストール] ボタンをクリックする必要があります。
 Win11の新機能分析:Microsoftアカウントへのログインをスキップする方法
Mar 27, 2024 pm 05:24 PM
Win11の新機能分析:Microsoftアカウントへのログインをスキップする方法
Mar 27, 2024 pm 05:24 PM
Win11 の新機能の分析: Microsoft アカウントへのログインをスキップする方法 Windows 11 のリリースにより、多くのユーザーは、Windows 11 がより便利で新しい機能をもたらしたことに気づきました。ただし、ユーザーによっては、自分のシステムが Microsoft アカウントに関連付けられることを好まず、この手順をスキップしたい場合があります。この記事では、ユーザーが Windows 11 で Microsoft アカウントへのログインをスキップし、よりプライベートで自律的なエクスペリエンスを実現するのに役立ついくつかの方法を紹介します。まず、一部のユーザーが Microsoft アカウントにログインすることに抵抗がある理由を理解しましょう。一方で、一部のユーザーは次のことを心配しています。
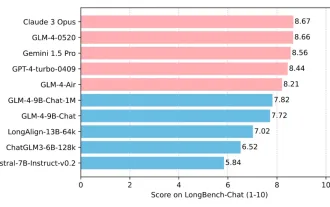 清華大学と Zhipu AI オープンソース GLM-4: 自然言語処理に新たな革命を起こす
Jun 12, 2024 pm 08:38 PM
清華大学と Zhipu AI オープンソース GLM-4: 自然言語処理に新たな革命を起こす
Jun 12, 2024 pm 08:38 PM
2023 年 3 月 14 日に ChatGLM-6B が発売されて以来、GLM シリーズ モデルは幅広い注目と認知を得てきました。特にChatGLM3-6Bがオープンソース化されてからは、Zhipu AIが投入する第4世代モデルに対する開発者の期待が高まっている。 GLM-4-9B のリリースにより、この期待はついに完全に満たされました。 GLM-4-9B の誕生 小型モデル (10B 以下) により強力な機能を提供するために、GLM 技術チームはこの新しい第 4 世代 GLM シリーズ オープン ソース モデル、GLM-4-9B をほぼ半年の期間を経て発売しました。探検。このモデルは、精度を確保しながらモデルサイズを大幅に圧縮し、推論速度の高速化と効率化を実現しています。 GLM 技術チームの調査はまだ終わっていない
 エージェントを一文で作成!ロビン・リー: 誰もが開発者になる時代が来る
Apr 17, 2024 pm 02:28 PM
エージェントを一文で作成!ロビン・リー: 誰もが開発者になる時代が来る
Apr 17, 2024 pm 02:28 PM
すべてを覆す大きなモデルが、ついに編集者の頭にたどり着いた。たった一文でできたエージェントでもあります。このように、彼に記事を与えると、1 秒以内に新鮮なタイトルの候補が出てきます。私と比較すると、この効率は稲妻のように速く、ナマケモノのように遅いとしか言いようがありません... さらに驚くべきことに、このエージェントの作成には実際には数分しかかからないということです。プロンプトは江おばさんのものです。そして、この破壊的な感覚も体験したい場合は、百度が立ち上げた新しいウェンシン インテリジェント エージェント プラットフォームに基づいて、誰でも無料で独自のインテリジェント アシスタントを作成できます。検索エンジン、スマート ハードウェア プラットフォーム、音声認識、地図、自動車、その他の Baidu モバイル エコロジー チャネルを使用して、より多くの人があなたの創造性を活用できるようにすることができます。ロビン・リー自身
