

MongoDB入门学习(四):MongoDB的索引

上一篇讲到了MongoDB的基本操作增删查改,对于查询来说,必须按照我们的查询要求去集合中,并将查找到的结果返回,在这个过程中其实是对整个集合中每个文档进行了扫描,如果满足我们的要求就添加到结果集中最后返回。对于小集合来说,这个过程没什么,但是集
上一篇讲到了MongoDB的基本操作增删查改,对于查询来说,必须按照我们的查询要求去集合中,并将查找到的结果返回,在这个过程中其实是对整个集合中每个文档进行了扫描,如果满足我们的要求就添加到结果集中最后返回。对于小集合来说,这个过程没什么,但是集合中数据很大的时候,进行表扫描是一个非常恐怖的事情,于是有了索引一说,索引是用来加速查询的,相当于书籍的目录,有了目录可以很精准的定位要查找内容的位置,从而减少无谓的查找。
1.索引的类型
创建索引可以是在单个字段上,也可以是在多个字段上,这个根据自己的实际情况来选择,创建索引时字段的顺序也是有讲究的。创建索引是通过ensureIndex()方法,需要给该方法传递一个文档形式的数据,其中指定索引的字段和顺序,1代表升序,-1代表降序。
1).默认索引
还记得"_id"吗,这个字段的数据是不能重复的,它就是MongoDB的默认索引,而且不能被删除。
2).单列索引
在单个字段上创建的索引就是单列索引,在查询的过程中可以对该加速对该键的查询,然而对其他键的查询是没有帮助的。单列索引的顺序是不会影响对该键的随即查询,创建单列索引:
> db.people.ensureIndex({"name" : 1})3).组合索引
还可以在多个键上创建组合索引,此时键的位置和索引的顺序都会影响查询的效率,看下面创建组合索引:
> db.people.ensureIndex({"name" : 1, "age" : 1})
> db.people.ensureIndex({"age" : 1, "name" : 1})第一种情况会对name排序组织,当name一样时在对age排序,所以对{"name" : 1}和{“name” : 1, "age" : 1}的查询更高效,而第二种情况则对age排序,当age一样再对name排序,所以对{"age" : 1}和{"age" : 1, "name" : 1}的查询更高效。当组合索引包含很多字段的时候,会对前几个键的查询有帮助。
4).内嵌文档索引
还可以对内嵌文档创建索引,和普通键创建索引一样差不多,也可以对内嵌文档创建组合索引:
> db.people.ensureIndex({"friends.name" : 1})
> db.people.ensureIndex({"friends.name" : 1, "friends.age" : 1})在来看看其他几种形式的索引:
唯一索引
> db.people.ensureIndex({"name" : 1}, {"unique" : true})
> db.people.ensureIndex({"name" : 1}, {"unique" : true, "dropDups" : true})
松散索引
> db.people.ensureIndex({"name" : 1}, {"sparse" : true})
多值索引
> db.people.find()
{"name" : ["mary", "rose"]}
> db.people.ensureIndex({"name" : 1})唯一索引unique可以保证该键对应的值在集合中是唯一的,如果创建唯一索引的时候,该字段原来就存在了重复的数据,那么就会创建失败,可以加上dropDups字段来消除重复数据,它会保留发现的第一个文档,其他有重复数据的文档都将被删除。
集合中有的文档不存在某些字段,或者某些字段的值为null,那么我们在该字段上创建索引的时候不希望让这些空值的文档参与,那么就定义为松散索引sparse,比如在name上创建索引时,发现有的人在数据库中只有学号,没有名字,那么我们不希望把它们也包含进来,此时就定义为松散索引。
一个键对应的值是一个数组,在该键上创建索引时是一个多值索引,会为数组中每个值生成一个索引元素,相当于分裂成了几个独立的索引项,但是它们还是对应同一个文档数据。
2.索引的管理
索引固然是为查询而生,而且可以为每个键都创建索引,但是索引是需要存储空间的,所以索引不是越多越好,而且创建索引后,每次的插入,更新和删除文档都会产生额外的开销,因为数据库中不但要执行这些操作,而且还要在集合索引中标记这些操作。所以要根据实际情况来创建索引,索引没用之后将其删除。
创建索引是ensureIndex()方法,创建完成后可以通过getIndexes()来查看集合中创建的索引情况:
> db.people.ensureIndex({"name" : 1, "age" : 1})
> db.people.getIndexes()
[
{
"v" : 1,
"key" : {
"_id" : 1
},
"ns" : "test.people",
"name" : "_id_"
},
{
"v" : 1,
"key" : {
"name" : 1,
"age" : 1
},
"ns" : "test.people",
"name" : "name_1_age_1"
}
]可以看到people集合创建了两个索引,一个是"_id",这个是默认索引,另外一个是name和age的组合索引,名字为keyname1_dir_keyname2_dir_...,keyname代表索引的键,dir代表方向,1代表升序,-1代表降序。当然我们也可以自定义索引的名称:
> db.people.ensureIndex({"name" : 1, "age" : 1}, {"name" : "myIndex"})
> db.people.getIndexes()
[
{
"v" : 1,
"key" : {
"_id" : 1
},
"ns" : "test.people",
"name" : "_id_"
},
{
"v" : 1,
"key" : {
"name" : 1,
"age" : 1
},
"ns" : "test.people",
"name" : "myIndex"
}
]删除索引是通过dropIndex():
方式一:
> db.people.dropIndex({"name" : 1, "age" : 1})
{ "nIndexesWas" : 2, "ok" : 1 }
方式二:
> db.runCommand({"dropIndexes" : "people", "index" : "myIndex"})
{ "nIndexesWas" : 2, "ok" : 1 }索引的元信息存储在每个数据库的system.indexes集合中,不能对其进行插入和删除文档的操作,只能通过ensureIndex和dropIndex进行。
> db.system.indexes.find()
{ "v" : 1, "key" : { "_id" : 1 }, "ns" : "test.people", "name" : "_id_" }
{ "v" : 1, "key" : { "name" : 1, "age" : 1 }, "ns" : "test.people", "name" : "myIndex" }清空集合中所有的文档是不会将索引删除的,原来创建的索引依然存在,但是直接删除集合的话,该集合的索引也是会被删除的。
3.索引的效率
如果我们定义了很多的索引,那么MongoDB会根据我们的查询选项重新排序,并智能的选择一个最优的来使用,比如我们创建了{"name" : 1, "age" : 1}和{"age" : 1, "class" : 1}两个索引,但是我们的查询项为find({"age" : 10, "name" : "mary"}),那么MongoDB会自动重新排序为find({"name" : "mary", "age" : 10}),并且利用索引{"name" : 1, "age" : 1}来查询。
MongoDB提供了explain工具来帮助我们获得查询方面的很多有用信息,只要对游标调用这个方法就可以得到查询的细节。下面给math集合中添加10W个文档,再来看看使用索引前后的效率对比:
> var arr = [];
> for(var i = 0; i < 100000; i++){
... var doc = {};
... var value = Math.floor(Math.random() * 1000);
... doc["number"] = value;
... arr.push(doc);
... }
100000
> db.math.insert(arr)
> db.math.count()
100000
> db.math.find().limit(10)
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fe5"), "number" : 462 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fe6"), "number" : 123 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fe7"), "number" : 90 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fe8"), "number" : 46 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fe9"), "number" : 244 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fea"), "number" : 972 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61feb"), "number" : 925 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fec"), "number" : 110 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fed"), "number" : 739 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fee"), "number" : 945 }通过for循环给arr数组中添加10W条数据,然后再批量插入这些数据到math集合中,查看前10条数据,因为是随即生成的值,所以number字段的值会有重复值,我们就来查询462这个值:
创建索引前:
> db.math.find({"number" : 462}).explain()
{
"cursor" : "BasicCursor",
"isMultiKey" : false,
"n" : 94,
"nscannedObjects" : 100000,
"nscanned" : 100000,
"nscannedObjectsAllPlans" : 100000,
"nscannedAllPlans" : 100000,
"scanAndOrder" : false,
"indexOnly" : false,
"nYields" : 0,
"nChunkSkips" : 0,
"millis" : 35,
"indexBounds" : {
},
"server" : "server0.169:9352"
}
创建索引后:
> db.math.ensureIndex({"number" : 1})
> db.math.find({"number" : 462}).explain()
{
"cursor" : "BtreeCursor number_1",
"isMultiKey" : false,
"n" : 94,
"nscannedObjects" : 94,
"nscanned" : 94,
"nscannedObjectsAllPlans" : 94,
"nscannedAllPlans" : 94,
"scanAndOrder" : false,
"indexOnly" : false,
"nYields" : 0,
"nChunkSkips" : 0,
"millis" : 0,
"indexBounds" : {
"number" : [
[
462,
462
]
]
},
"server" : "server0.169:9352"
}这里来看一下有用的信息,"cursor"指用的哪个索引,"nscanned"代表查找了多少个文档,"n"指返回文档的数量,"millis"表示查询所花时间,单位是毫秒。可以看出创建索引前没有使用索引,在全部的文档中查询的,花费了35毫秒,而创建索引后,使用了number_1索引查询,索引存储在B树结构中,只在94个文档中查询,几乎不花时间。
如果有很多索引的话,MongoDB会自动选一个来查询,你也可以通过hint来强制使用某个索引,这里强制使用{"age" : 1, "name" : 1}这个索引:
> db.people.find({"age" : {"$gt" : 10}, "name" : "mary"}).hint({"age" : 1, "name" : 1})
ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7700
7700
 15
1640
14
1393
52
1287
25
1230
29
15
1640
14
1393
52
1287
25
1230
29

 AIの活用 | AIが一人暮らしの女の子の生活ビデオブログを作成、3日間で数万件の「いいね!」を獲得
Aug 07, 2024 pm 10:53 PM
AIの活用 | AIが一人暮らしの女の子の生活ビデオブログを作成、3日間で数万件の「いいね!」を獲得
Aug 07, 2024 pm 10:53 PM
Machine Power Report 編集者: Yang Wen 大型モデルや AIGC に代表される人工知能の波は、私たちの生活や働き方を静かに変えていますが、ほとんどの人はまだその使い方を知りません。そこで、直感的で興味深く、簡潔な人工知能のユースケースを通じてAIの活用方法を詳しく紹介し、皆様の思考を刺激するコラム「AI in Use」を立ち上げました。また、読者が革新的な実践的な使用例を提出することも歓迎します。ビデオリンク: https://mp.weixin.qq.com/s/2hX_i7li3RqdE4u016yGhQ 最近、Xiaohongshu で一人暮らしの女の子の生活 vlog が人気になりました。イラスト風のアニメーションといくつかの癒しの言葉を組み合わせれば、数日で簡単に習得できます。
 行列とグラフの間には等価関係があるということを、ライン生成を学んでいたときになぜ知らなかったのでしょうか?
Aug 19, 2024 pm 04:52 PM
行列とグラフの間には等価関係があるということを、ライン生成を学んでいたときになぜ知らなかったのでしょうか?
Aug 19, 2024 pm 04:52 PM
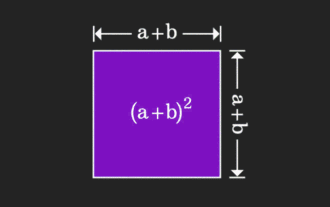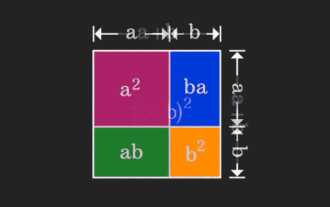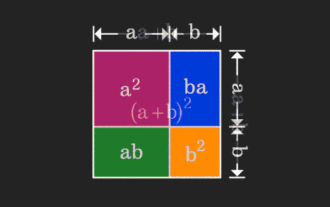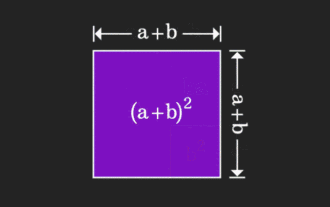
マトリックスはわかりにくいですが、別の視点から見ると違うのかもしれません。数学を学ぶとき、私たちは学んだ知識の難しさや抽象性にイライラすることがよくありますが、視点を変えるだけで問題に対するシンプルで直感的な解決策を見つけることができることがあります。たとえば、私たちが子供の頃に二乗和 (a+b)² の公式を習ったとき、それがなぜ a²+2ab+b² に等しいのか理解できなかったかもしれません。この本と先生は、私たちにこのように覚えるように言いました。ある日、このアニメーションを見るまでは、幾何学的な観点からそれを理解できることに突然気づきました。ここで、この啓発的な感覚が再び起こります。非負行列は、対応する有向グラフに等価的に変換できるのです。以下の図に示すように、左側の 3×3 行列は実際には次のようになります。
 DebianでMongoDB自動拡張を構成する方法
Apr 02, 2025 am 07:36 AM
DebianでMongoDB自動拡張を構成する方法
Apr 02, 2025 am 07:36 AM
この記事では、自動拡張を実現するためにDebianシステムでMongodbを構成する方法を紹介します。主な手順には、Mongodbレプリカセットとディスクスペース監視のセットアップが含まれます。 1。MongoDBのインストール最初に、MongoDBがDebianシステムにインストールされていることを確認してください。次のコマンドを使用してインストールします。sudoaptupdatesudoaptinstinstall-yymongodb-org2。mongodbレプリカセットMongodbレプリカセットの構成により、自動容量拡張を達成するための基礎となる高可用性とデータ冗長性が保証されます。 Mongodbサービスを開始:Sudosystemctlstartmongodsudosys
 DebianでMongodbの高可用性を確保する方法
Apr 02, 2025 am 07:21 AM
DebianでMongodbの高可用性を確保する方法
Apr 02, 2025 am 07:21 AM
この記事では、Debianシステムで非常に利用可能なMongoDBデータベースを構築する方法について説明します。データのセキュリティとサービスが引き続き動作し続けるようにするための複数の方法を探ります。キー戦略:レプリカセット:レプリカセット:レプリカセットを使用して、データの冗長性と自動フェールオーバーを実現します。マスターノードが失敗すると、レプリカセットが自動的に新しいマスターノードを選択して、サービスの継続的な可用性を確保します。データのバックアップと回復:MongoDumpコマンドを定期的に使用してデータベースをバックアップし、データ損失のリスクに対処するために効果的な回復戦略を策定します。監視とアラーム:監視ツール(プロメテウス、グラファナなど)を展開して、MongoDBの実行ステータスをリアルタイムで監視し、
 MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
Hash値として保存されているため、Navicatを介してMongoDBパスワードを直接表示することは不可能です。紛失したパスワードを取得する方法:1。パスワードのリセット。 2。構成ファイルを確認します(ハッシュ値が含まれる場合があります)。 3.コードを確認します(パスワードをハードコードできます)。
 MongoDBおよびリレーショナルデータベース:包括的な比較
Apr 08, 2025 pm 06:30 PM
MongoDBおよびリレーショナルデータベース:包括的な比較
Apr 08, 2025 pm 06:30 PM
MongoDBおよびリレーショナルデータベース:詳細な比較この記事では、NOSQLデータベースMongoDBと従来のリレーショナルデータベース(MySQLやSQLServerなど)の違いを詳細に調べます。リレーショナルデータベースは、行と列のテーブル構造を使用してデータを整理しますが、MongoDBは柔軟なドキュメント指向モデルを使用して、最新のアプリケーションのニーズをより適切に適しています。主にデータ構造を区別します。リレーショナルデータベースは、事前定義されたスキーマテーブルを使用してデータを保存し、テーブル間の関係は一次キーと外部キーを通じて確立されます。 MongoDBはJSONのようなBSONドキュメントを使用してコレクションに保存します。各ドキュメント構造は、パターンのないデザインを実現するために独立して変更できます。アーキテクチャデザイン:リレーショナルデータベースは、事前に定義された固定スキーマが必要です。 Mongodbサポート
 Debian Mongodbでデータを暗号化する方法
Apr 12, 2025 pm 08:03 PM
Debian Mongodbでデータを暗号化する方法
Apr 12, 2025 pm 08:03 PM
DebianシステムでMongoDBデータベースを暗号化するには、次の手順に従う必要があります。ステップ1:MongoDBのインストール最初に、DebianシステムがMongoDBをインストールしていることを確認してください。そうでない場合は、インストールについては公式のMongoDBドキュメントを参照してください:https://docs.mongodb.com/manual/tutorial/install-mongodb-onedbian/-step 2:暗号化キーファイルを作成し、暗号化キーを含むファイルを作成し、正しい許可を設定します。
 Centos Mongodbバックアップ戦略とは何ですか?
Apr 14, 2025 pm 04:51 PM
Centos Mongodbバックアップ戦略とは何ですか?
Apr 14, 2025 pm 04:51 PM
MongoDB効率的なバックアップ戦略の詳細な説明CENTOSシステムでは、この記事では、データセキュリティとビジネスの継続性を確保するために、CENTOSシステムにMongoDBバックアップを実装するためのさまざまな戦略を詳細に紹介します。 Dockerコンテナ環境でのマニュアルバックアップ、タイミング付きバックアップ、自動スクリプトバックアップ、バックアップメソッドをカバーし、バックアップファイル管理のベストプラクティスを提供します。マニュアルバックアップ:MongoDumpコマンドを使用して、マニュアルフルバックアップを実行します。たとえば、Mongodump-Hlocalhost:27017-U Username-P Password-Dデータベース名-O/バックアップディレクトリこのコマンドは、指定されたデータベースのデータとメタデータを指定されたバックアップディレクトリにエクスポートします。
