

使用导出导入(datapump)方式将普通表切换为分区表

随着数据库数据量的不断增长,有些表需要由普通的堆表转换为分区表的模式。有几种不同的方法来对此进行操作,诸如导出表数据,然后创建分区表再导入数据到分区表;使用EXCHANGE PARTITION方式来转换为分区表以及使用DBMS_REDEFINITION来在线重定义分区表。本
随着数据库数据量的不断增长,有些表需要由普通的堆表转换为分区表的模式。有几种不同的方法来对此进行操作,诸如导出表数据,然后创建分区表再导入数据到分区表;使用EXCHANGE PARTITION方式来转换为分区表以及使用DBMS_REDEFINITION来在线重定义分区表。本文描述的是使用导出导入方式来实现,下面是具体的操作示例。
有关具体的dbms_redefinition在线重定义表的原理及步骤可参考:基于 dbms_redefinition 在线重定义表
1、主要步骤
2、准备环境
--创建用户
SQL> create user leshami identified by xxx;
SQL> grant dba to leshami;
--创建演示需要用到的表空间
SQL> create tablespace tbs_tmp datafile '/u02/database/SYBO2/oradata/tbs_tmp.dbf' size 10m autoextend on;
SQL> alter user leshami default tablespace tbs_tmp;
SQL> create tablespace tbs1 datafile '/u02/database/SYBO2/oradata/tbs1.dbf' size 10m autoextend on;
SQL> create tablespace tbs2 datafile '/u02/database/SYBO2/oradata/tbs2.dbf' size 10m autoextend on;
SQL> create tablespace tbs3 datafile '/u02/database/SYBO2/oradata/tbs3.dbf' size 10m autoextend on;
SQL> conn leshami/xxx
-- 创建一个lookup表
CREATE TABLE lookup (
id NUMBER(10),
description VARCHAR2(50)
);
--添加主键约束
ALTER TABLE lookup ADD (
CONSTRAINT lookup_pk PRIMARY KEY (id)
);
--插入数据
INSERT INTO lookup (id, description) VALUES (1, 'ONE');
INSERT INTO lookup (id, description) VALUES (2, 'TWO');
INSERT INTO lookup (id, description) VALUES (3, 'THREE');
COMMIT;
--创建一个用于切换到分区的大表
CREATE TABLE big_table (
id NUMBER(10),
created_date DATE,
lookup_id NUMBER(10),
data VARCHAR2(50)
);
--填充数据到大表
DECLARE
l_lookup_id lookup.id%TYPE;
l_create_date DATE;
BEGIN
FOR i IN 1 .. 10000 LOOP
IF MOD(i, 3) = 0 THEN
l_create_date := ADD_MONTHS(SYSDATE, -24);
l_lookup_id := 2;
ELSIF MOD(i, 2) = 0 THEN
l_create_date := ADD_MONTHS(SYSDATE, -12);
l_lookup_id := 1;
ELSE
l_create_date := SYSDATE;
l_lookup_id := 3;
END IF;
INSERT INTO big_table (id, created_date, lookup_id, data)
VALUES (i, l_create_date, l_lookup_id, 'This is some data for ' || i);
END LOOP;
COMMIT;
END;
/
--为大表添加主、外键约束,索引,以及添加触发器等.
ALTER TABLE big_table ADD (
CONSTRAINT big_table_pk PRIMARY KEY (id)
);
CREATE INDEX bita_created_date_i ON big_table(created_date);
CREATE INDEX bita_look_fk_i ON big_table(lookup_id);
ALTER TABLE big_table ADD (
CONSTRAINT bita_look_fk
FOREIGN KEY (lookup_id)
REFERENCES lookup(id)
);
CREATE OR REPLACE TRIGGER tr_bf_big_table
BEFORE UPDATE OF created_date
ON big_table
FOR EACH ROW
BEGIN
:new.created_date := TO_CHAR (SYSDATE, 'yyyymmdd hh24:mi:ss');
END tr_bf_big_table;
/
--收集统计信息
EXEC DBMS_STATS.gather_table_stats('LESHAMI', 'LOOKUP', cascade => TRUE);
EXEC DBMS_STATS.gather_table_stats('LESHAMI', 'BIG_TABLE', cascade => TRUE);
3、创建分区表
CREATE TABLE big_table2 ( id NUMBER(10), created_date DATE, lookup_id NUMBER(10), data VARCHAR2(50) ) PARTITION BY RANGE (created_date) (PARTITION big_table_2012 VALUES LESS THAN (TO_DATE('01/01/2013', 'DD/MM/YYYY')) tablespace tbs1, PARTITION big_table_2013 VALUES LESS THAN (TO_DATE('01/01/2014', 'DD/MM/YYYY')) tablespace tbs2, PARTITION big_table_2014 VALUES LESS THAN (MAXVALUE)) tablespace tbs3; --可以直接使用Insert方式来填充数据到分区表,如下 INSERT INTO big_table2 SELECT * FROM big_table;
4、通过datapump方式导出导入数据到分区表
--该方式主要用于从不同的数据库迁移数据,比如源库源表为普通表,而目标库为分区表 $ expdp leshami/xxx directory=db_dump_dir dumpfile=big_table.dmp logfile=exp_big_tb.log tables=big_table content=data_only SQL> rename big_table to big_table_old; Table renamed. SQL> rename big_table2 to big_table; Table renamed. $ impdp leshami/xxx directory=db_dump_dir dumpfile=big_table.dmp logfile=imp__big_tb.log tables=big_table EXEC DBMS_STATS.gather_table_stats('LESHAMI', 'BIG_TABLE', cascade => TRUE); --下面是导入数据之后的结果 SQL> select table_name, partition_name,high_value,num_rows 2 from user_tab_partitions where table_name='BIG_TABLE'; TABLE_NAME PARTITION_NAME HIGH_VALUE NUM_ROWS ------------------------------ ------------------------------ --------------------- ---------- BIG_TABLE2 BIG_TABLE_2012 TO_DATE(' 2013-01-01 3333 BIG_TABLE2 BIG_TABLE_2013 TO_DATE(' 2014-01-01 3334 BIG_TABLE2 BIG_TABLE_2014 MAXVALUE 3333 --如果数据无异常可以删除源表以便为分区表添加相应索引及约束,如果未删除源表,需要使用单独的索引,约束名等 SQL> drop table big_table; Table dropped. ALTER TABLE big_table ADD ( CONSTRAINT big_table_pk PRIMARY KEY (id) ); CREATE INDEX bita_created_date_i ON big_table(created_date) LOCAL; CREATE INDEX bita_look_fk_i ON big_table(lookup_id) LOCAL; ALTER TABLE big_table ADD ( CONSTRAINT bita_look_fk FOREIGN KEY (lookup_id) REFERENCES lookup(id) ); --触发器也需要单独添加到分区表 CREATE OR REPLACE TRIGGER tr_bf_big_table BEFORE UPDATE OF created_date ON big_table FOR EACH ROW BEGIN :new.created_date := TO_CHAR (SYSDATE, 'yyyymmdd hh24:mi:ss'); END tr_bf_big_table2; / 5、后记

更多参考
有关Oracle RAC请参考
有关Oracle 网络配置相关基础以及概念性的问题请参考:
有关基于用户管理的备份和备份恢复的概念请参考
有关RMAN的备份恢复与管理请参考
有关ORACLE体系结构请参考

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7681
7681
 15
1393
52
1209
24
91
11
15
1393
52
1209
24
91
11

 CrystalDiskmarkとはどのようなソフトウェアですか? -crystaldiskmarkの使い方は?
Mar 18, 2024 pm 02:58 PM
CrystalDiskmarkとはどのようなソフトウェアですか? -crystaldiskmarkの使い方は?
Mar 18, 2024 pm 02:58 PM
CrystalDiskMark は、シーケンシャルおよびランダムの読み取り/書き込み速度を迅速に測定する、ハード ドライブ用の小型 HDD ベンチマーク ツールです。次に、編集者が CrystalDiskMark と Crystaldiskmark の使用方法を紹介します。 1. CrystalDiskMark の概要 CrystalDiskMark は、機械式ハード ドライブとソリッド ステート ドライブ (SSD) の読み取りおよび書き込み速度とパフォーマンスを評価するために広く使用されているディスク パフォーマンス テスト ツールです。 ). ランダム I/O パフォーマンス。これは無料の Windows アプリケーションで、使いやすいインターフェイスとハード ドライブのパフォーマンスのさまざまな側面を評価するためのさまざまなテスト モードを提供し、ハードウェアのレビューで広く使用されています。
 foobar2000のダウンロード方法は? -foobar2000の使い方
Mar 18, 2024 am 10:58 AM
foobar2000のダウンロード方法は? -foobar2000の使い方
Mar 18, 2024 am 10:58 AM
foobar2000 は、音楽リソースをいつでも聴くことができるソフトウェアです。あらゆる種類の音楽をロスレス音質で提供します。音楽プレーヤーの強化版により、より包括的で快適な音楽体験を得ることができます。その設計コンセプトは、高度なオーディオをコンピュータ上で再生可能 デバイスを携帯電話に移植し、より便利で効率的な音楽再生体験を提供 シンプルでわかりやすく、使いやすいインターフェースデザイン 過度な装飾や煩雑な操作を排除したミニマルなデザインスタイルを採用また、さまざまなスキンとテーマをサポートし、自分の好みに合わせて設定をカスタマイズし、複数のオーディオ形式の再生をサポートする専用の音楽プレーヤーを作成します。過度の音量による聴覚障害を避けるために、自分の聴覚の状態に合わせて調整してください。次は私がお手伝いさせてください
 WeChat で Douyin プライベート メッセージの絵文字を取得するにはどうすればよいですか?プライベート メッセージの絵文字パッケージをエクスポートするにはどうすればよいですか?
Mar 21, 2024 pm 10:01 PM
WeChat で Douyin プライベート メッセージの絵文字を取得するにはどうすればよいですか?プライベート メッセージの絵文字パッケージをエクスポートするにはどうすればよいですか?
Mar 21, 2024 pm 10:01 PM
ソーシャルメディアの台頭が続く中、Douyinは人気のショートビデオプラットフォームとして多くのユーザーを魅了しています。 Douyin では、ユーザーは自分の生活を公開するだけでなく、他のユーザーと交流することもできます。このインタラクションにおいて、絵文字は徐々にユーザーが感情を表現する重要な手段になってきました。 1. WeChat で Douyin プライベート メッセージ絵文字を取得するにはどうすればよいですか?まず、Douyin プラットフォームでプライベート メッセージ絵文字を取得するには、Douyin アカウントにログインし、気に入った絵文字を参照して選択する必要があります。友達に送信するか、自分で収集するかを選択できます。 Douyin で絵文字パッケージを受信した後、プライベート メッセージ インターフェイスで絵文字パッケージを長押しし、「絵文字に追加」機能を選択できます。このようにして、この顔文字パッケージをDouyinの顔文字ライブラリに追加できます。 3. 次に、Douyin 顔文字ライブラリに単語を追加する必要があります
 NetEase Cloud Music からローカル曲をインポートする方法 ローカル曲をインポートする方法
Mar 13, 2024 am 11:19 AM
NetEase Cloud Music からローカル曲をインポートする方法 ローカル曲をインポートする方法
Mar 13, 2024 am 11:19 AM
このプラットフォームを使用して曲を聴く場合、ほとんどの曲には聴きたい曲がいくつかあるはずです。もちろん、著作権がないため聴けないものもあります。もちろん、一部の曲を直接使用することもできますローカルにインポートされています。そこに行って聞いてください。一部の曲をダウンロードして、mp3 形式に直接変換できるため、携帯電話でスキャンしてインポートしたり、その他の状況に使用したりできます。しかし、ほとんどのユーザーにとって、ローカルの曲コンテンツのインポートについてはよくわからないため、これらの問題をうまく解決するために、今日は編集者も説明します。興味がありますか、
 NetEase メールボックス マスターの使用方法
Mar 27, 2024 pm 05:32 PM
NetEase メールボックス マスターの使用方法
Mar 27, 2024 pm 05:32 PM
NetEase Mailbox は、中国のネットユーザーに広く使用されている電子メール アドレスとして、その安定した効率的なサービスで常にユーザーの信頼を獲得してきました。 NetEase Mailbox Master は、携帯電話ユーザー向けに特別に作成された電子メール ソフトウェアで、電子メールの送受信プロセスが大幅に簡素化され、電子メールの処理がより便利になります。 NetEase Mailbox Master の使い方と具体的な機能について、以下ではこのサイトの編集者が詳しく紹介しますので、お役に立てれば幸いです。まず、モバイル アプリ ストアで NetEase Mailbox Master アプリを検索してダウンロードします。 App Store または Baidu Mobile Assistant で「NetEase Mailbox Master」を検索し、画面の指示に従ってインストールします。ダウンロードとインストールが完了したら、NetEase の電子メール アカウントを開いてログインします。ログイン インターフェイスは次のとおりです。
 Baidu Netdisk アプリの使用方法
Mar 27, 2024 pm 06:46 PM
Baidu Netdisk アプリの使用方法
Mar 27, 2024 pm 06:46 PM
クラウド ストレージは今日、私たちの日常生活や仕事に欠かせない部分になっています。中国有数のクラウド ストレージ サービスの 1 つである Baidu Netdisk は、強力なストレージ機能、効率的な伝送速度、便利な操作体験により多くのユーザーの支持を得ています。また、重要なファイルのバックアップ、情報の共有、オンラインでのビデオの視聴、または音楽の聴きたい場合でも、Baidu Cloud Disk はニーズを満たすことができます。しかし、Baidu Netdisk アプリの具体的な使用方法を理解していないユーザーも多いため、このチュートリアルでは Baidu Netdisk アプリの使用方法を詳しく紹介します。まだ混乱しているユーザーは、この記事に従って詳細を学ぶことができます。 Baidu Cloud Network Disk の使用方法: 1. インストール まず、Baidu Cloud ソフトウェアをダウンロードしてインストールするときに、カスタム インストール オプションを選択してください。
 BTCC チュートリアル: BTCC 取引所で MetaMask ウォレットをバインドして使用する方法は?
Apr 26, 2024 am 09:40 AM
BTCC チュートリアル: BTCC 取引所で MetaMask ウォレットをバインドして使用する方法は?
Apr 26, 2024 am 09:40 AM
MetaMask (中国語ではリトル フォックス ウォレットとも呼ばれます) は、無料で評判の高い暗号化ウォレット ソフトウェアです。現在、BTCC は MetaMask ウォレットへのバインドをサポートしており、バインド後は MetaMask ウォレットを使用してすぐにログイン、値の保存、コインの購入などが可能になり、初回バインドで 20 USDT のトライアル ボーナスも獲得できます。 BTCCMetaMask ウォレットのチュートリアルでは、MetaMask の登録方法と使用方法、および BTCC で Little Fox ウォレットをバインドして使用する方法を詳しく紹介します。メタマスクウォレットとは何ですか? 3,000 万人を超えるユーザーを抱える MetaMask Little Fox ウォレットは、現在最も人気のある暗号通貨ウォレットの 1 つです。無料で使用でき、拡張機能としてネットワーク上にインストールできます。
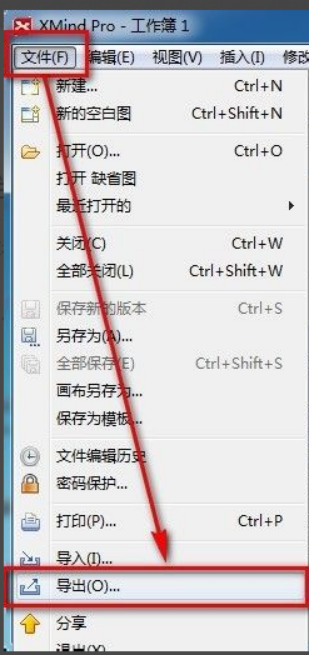 xmind ファイルを PDF ファイルにエクスポートする方法
Mar 20, 2024 am 10:30 AM
xmind ファイルを PDF ファイルにエクスポートする方法
Mar 20, 2024 am 10:30 AM
xmind は、非常に実用的なマインド マッピング ソフトウェアです。人々の思考とインスピレーションを使用して作成されたマップ形式です。xmind ファイルを作成した後、通常、誰もが配布して使用できるように、PDF ファイル形式に変換します。次に、xmind ファイルをエクスポートする方法PDFファイルに?以下に具体的な手順を示しますので、ご参照ください。 1. まず、マインド マップを PDF ドキュメントにエクスポートする方法を説明します。 [ファイル]-[エクスポート]機能ボタンを選択します。 2. 新しく表示されたインターフェースで[PDFドキュメント]を選択し、[次へ]ボタンをクリックします。 3. エクスポート インターフェイスで、用紙サイズ、方向、解像度、ドキュメントの保存場所などの設定を選択します。設定が完了したら、[完了]ボタンをクリックします。 4. [完了]ボタンをクリックした場合
