

简析三层架构

三层架构3-tier architecture 通过几个问题,来初步的学习一下三层架构。 1、什么是三层架构 2、应用场景为什么要用三层架构? 3、三层作用 4、各个层之间的关系 5、三层联系引用 6、各层是如何调用的 7、三层和二层的对比 这几个都是学习三层中最基本的问题
三层架构——3-tier architecture
通过几个问题,来初步的学习一下三层架构。1、什么是三层架构 2、应用场景——为什么要用三层架构? 3、三层作用 4、各个层之间的关系 5、三层联系——引用 6、各层是如何调用的 7、三层和二层的对比 这几个都是学习三层中最基本的问题,只有把这些问题搞清楚,才算是打开了三层的门。
1、什么是三层架构
在软件体系架构设计中,分层式结构是最常见,也是最重要的一种结构。三层从下至上分别为:数据访问层(DAL)、业务逻辑层(BLL)、表示层(UI)。

表现层(UI):展现给用户的界面,即用户在使用一个系统的时候他的所见所得。
业务逻辑层(BLL):对数据层的操作,对数据业务逻辑处理。
数据访问层(DAL):对数据库的操作,数据的增添、删除、修改、查找等。
2、应用场景——为什么要用三层架构?
为什么要用三层架构?
解耦!
不是所有的程序都需要使用三层架构,没必要把简单的问题复杂化。
先来说一下解耦,举例:修电脑
电脑硬盘坏了?我们要做的就是换掉电脑硬盘
内存条坏了?只要换内存条就好
这些部件出现问题,都不会影响别的部件的正常使用,这个就是让他们之间解耦。而和电脑不同的收音机,任何部件坏了,都会影响别的部件,这个体现的就是他们之间的耦合比较高。从这个例子里面就可以看出解耦的好处,在三层中就是用的解耦的思想。
3、三层作用
数据访问层:从数据源加载(Select),写入(Insert/Update),删除(Delete)数据。仅限于和数据源打交道,让程序简单明了。
显示层(UI):向用户展现特定业务数据,采集用户的输入信息和操作。
原则:用户至上,兼顾简洁。
业务逻辑层(BLL):从DAL中获取数据,以供UI显示用,从UI中获取用户指令和数据,执行业务逻辑、从UI中获取用户指令和数据,通过DAL写入数据源。
4、各个层之间的关系:
UI->BLL->UI:UI提供数据指令到业务逻辑,若自己可以搞定,则直接反馈到UI
UI->BLL->DAL->BLL->DAL:UI提供用户指令和数据,提出请求并搜集一定的数据BLL,BLL处理不了时,要访问数据源,则转给DAL

5、三层联系——引用
以登陆为例子,说明三层之间的引用关系:
实体层(entity):定义的用户名和密码。
U层:向对应的文本框中输入账号和密码
B层:判断U层输入的账号和密码是否存在。
D层:连接数据库的语句,查询数据库。
他们之间的联系是通过实体传递来进行的,。
DAL所在程序集不引用BLL和UI
BLL需要引用DAL
UI直接引用DAL,可能引用BLL
非常忌讳互相引用,为了避免这个问题所有出现了实体层(业务数据模型,里面的数据和数据库的有所差异)
应用原则:
DAL只提供基本的数据访问,不包含任何业务相关的逻辑处理。UI只负责显示和采集用户操作,不包含任何的业务相关的逻辑处理,BLL负责处理业务逻辑,通过获取UI传来的操作指令,决定执行业务逻辑,在需要访问数据源的时候直接交给DAL处理。处理完成后,返回必要数据给UI。
6、各层是如何调用的
表示层(UI)是用户需要的界面,用户有什么需求都是在这个上面进行的改动,一旦有改动,首先U层向B层发送用户请求的说明,到达B层,B层再将U层的用户请求发送到D层,D层接受到用户请求的指令后,对它进行处理,发送数据反馈到B层,B层再发给U层,将这一变化反应出来。
举例:
小菜和大鸟吃羊肉串的例子,小菜和大鸟就是用户,服务员为表示层(U层),烤肉师父为业务逻辑层(U层引用B层的方法或者参数),老板娘为数据访问层(D层),负责给烤肉师父从库房拿烤串。大鸟点了羊肉串5串(参数),服务员把羊肉串5串(参数传递)传递给烤肉师父(数据请求),烤肉师父再传递给老板娘(对参数进行处理),老板娘得到请求后,拿羊肉串给烤肉师父(数据反馈),烤肉师父将烤好的羊肉串给服务员(数据反馈),服务员再将5串羊肉串给大鸟(U层展现出来),他们之间通过调用来实现联系。
7、三层PK二层
二层架构:
业务逻辑简单,没有真正的数据存储层
三层架构:
抽象出业务逻辑层,当业务复杂到一定程度,当数据存储到相应的存储介质,数据存储脱离开业务逻辑,把业务逻辑脱离开UI单独存在,UI只需要呼叫业务访问层,就可以实现跟用户的交互。
三层的好处:
1、开发人员可以只关注整个结构中的其中某一层;
2、可以很容易的用新的实现来替换原有层次的实现;
3、可以降低层与层之间的依赖;
4、有利于标准化;
5、利于各层逻辑的复用。
6、结构更加的明确
7、在后期维护的时候,极大地降低了维护成本和维护时间。
这几点的中心思想就是“高内聚,低耦合”,类之间的耦合越弱,越有利于复用,一个处在弱耦合的类被修改,不会对有关系的类造成波及。
以上是对三层的简单认识,有的地方可能写的不对,欢迎指出!

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7454
7454
 15
1375
52
77
11
14
9
15
1375
52
77
11
14
9

 深層学習アーキテクチャの比較分析
May 17, 2023 pm 04:34 PM
深層学習アーキテクチャの比較分析
May 17, 2023 pm 04:34 PM
深層学習の概念は人工ニューラル ネットワークの研究に由来しており、複数の隠れ層を含む多層パーセプトロンが深層学習構造です。ディープラーニングは、低レベルの特徴を組み合わせて、データのカテゴリや特性を表すより抽象的な高レベルの表現を形成します。データの分散された特徴表現を検出できます。ディープラーニングは機械学習の一種であり、機械学習は人工知能を実現する唯一の方法です。では、さまざまな深層学習システム アーキテクチャの違いは何でしょうか? 1. 完全接続ネットワーク (FCN) 完全接続ネットワーク (FCN) は、一連の完全接続層で構成され、各層のすべてのニューロンが別の層のすべてのニューロンに接続されています。その主な利点は、「構造に依存しない」ことです。つまり、入力に関する特別な仮定が必要ありません。この構造にとらわれないことにより、完全な
 この「間違い」は実際には間違いではありません。Transformer アーキテクチャ図の何が「間違っている」のかを理解するには、4 つの古典的な論文から始めてください。
Jun 14, 2023 pm 01:43 PM
この「間違い」は実際には間違いではありません。Transformer アーキテクチャ図の何が「間違っている」のかを理解するには、4 つの古典的な論文から始めてください。
Jun 14, 2023 pm 01:43 PM
少し前に、Transformer のアーキテクチャ図と Google Brain チームの論文「Attending IsAllYouNeed」のコードとの間の矛盾を指摘したツイートが多くの議論を引き起こしました。セバスチャンの発見は意図せぬ間違いだったのではないかと考える人もいるが、これもまた驚くべきことである。結局のところ、Transformer 論文の人気を考慮すると、この矛盾については何千回も言及されるべきでした。 Sebastian Raschka氏はネチズンのコメントに答えて、「最もオリジナルな」コードは確かにアーキテクチャ図と一致していたが、2017年に提出されたコードバージョンは修正されたものの、アーキテクチャ図は同時に更新されていなかったと述べた。これが議論の「齟齬」の根本原因でもある。
 マルチパス、マルチドメイン、すべてを網羅! Google AI がマルチドメイン学習一般モデル MDL をリリース
May 28, 2023 pm 02:12 PM
マルチパス、マルチドメイン、すべてを網羅! Google AI がマルチドメイン学習一般モデル MDL をリリース
May 28, 2023 pm 02:12 PM
視覚タスク (画像分類など) の深層学習モデルは、通常、単一の視覚領域 (自然画像やコンピューター生成画像など) からのデータを使用してエンドツーエンドでトレーニングされます。一般に、複数のドメインのビジョン タスクを完了するアプリケーションは、個別のドメインごとに複数のモデルを構築し、それらを個別にトレーニングする必要があります。データは異なるドメイン間で共有されません。推論中、各モデルは特定のドメインの入力データを処理します。たとえそれらが異なる分野を指向しているとしても、これらのモデル間の初期層のいくつかの機能は類似しているため、これらのモデルの共同トレーニングはより効率的です。これにより、遅延と消費電力が削減され、各モデル パラメーターを保存するためのメモリ コストが削減されます。このアプローチはマルチドメイン学習 (MDL) と呼ばれます。さらに、MDL モデルは単一モデルよりも優れたパフォーマンスを発揮します。
 Spring Data JPA のアーキテクチャと動作原理は何ですか?
Apr 17, 2024 pm 02:48 PM
Spring Data JPA のアーキテクチャと動作原理は何ですか?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA は JPA アーキテクチャに基づいており、マッピング、ORM、トランザクション管理を通じてデータベースと対話します。そのリポジトリは CRUD 操作を提供し、派生クエリによりデータベース アクセスが簡素化されます。さらに、遅延読み込みを使用して必要な場合にのみデータを取得するため、パフォーマンスが向上します。
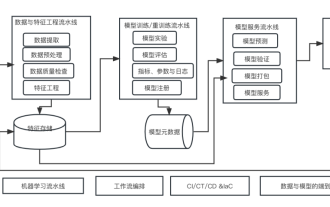 機械学習システムアーキテクチャの 10 の要素
Apr 13, 2023 pm 11:37 PM
機械学習システムアーキテクチャの 10 の要素
Apr 13, 2023 pm 11:37 PM
今は AI エンパワーメントの時代であり、機械学習は AI を実現するための重要な技術的手段です。では、普遍的な機械学習システム アーキテクチャは存在するのでしょうか?経験豊富なプログラマの認識範囲内では、特にシステム アーキテクチャに関しては何でもありません。ただし、ほとんどの機械学習駆動システムまたはユースケースに適用できる場合、スケーラブルで信頼性の高い機械学習システム アーキテクチャを構築することは可能です。機械学習のライフサイクルの観点から見ると、このいわゆるユニバーサル アーキテクチャは、機械学習モデルの開発から、トレーニング システムやサービス システムの運用環境への展開まで、主要な機械学習段階をカバーします。このような機械学習システムのアーキテクチャを 10 個の要素の次元から記述してみることができます。 1.
 1.3ミリ秒には1.3ミリ秒かかります。清華社の最新オープンソース モバイル ニューラル ネットワーク アーキテクチャ RepViT
Mar 11, 2024 pm 12:07 PM
1.3ミリ秒には1.3ミリ秒かかります。清華社の最新オープンソース モバイル ニューラル ネットワーク アーキテクチャ RepViT
Mar 11, 2024 pm 12:07 PM
論文のアドレス: https://arxiv.org/abs/2307.09283 コードのアドレス: https://github.com/THU-MIG/RepViTRepViT は、モバイル ViT アーキテクチャで優れたパフォーマンスを発揮し、大きな利点を示します。次に、この研究の貢献を検討します。記事では、主にモデルがグローバル表現を学習できるようにするマルチヘッド セルフ アテンション モジュール (MSHA) のおかげで、軽量 ViT は一般的に視覚タスクにおいて軽量 CNN よりも優れたパフォーマンスを発揮すると述べられています。ただし、軽量 ViT と軽量 CNN のアーキテクチャの違いは十分に研究されていません。この研究では、著者らは軽量の ViT を効果的なシステムに統合しました。
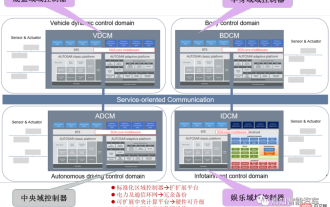 SOA におけるソフトウェア アーキテクチャ設計とソフトウェアとハードウェアの分離方法論
Apr 08, 2023 pm 11:21 PM
SOA におけるソフトウェア アーキテクチャ設計とソフトウェアとハードウェアの分離方法論
Apr 08, 2023 pm 11:21 PM
次世代の集中電子および電気アーキテクチャでは、セントラル + ゾーンの中央コンピューティング ユニットと地域コントローラー レイアウトの使用が、さまざまな OEM または Tier1 プレーヤーにとって必須のオプションとなっています。中央コンピューティング ユニットのアーキテクチャに関しては、3 つあります。方法: SOC の分離、ハードウェアの分離、ソフトウェアの仮想化。集中型の中央コンピューティング ユニットは、自動運転、スマート コックピット、車両制御の 3 つの主要領域の中核となるビジネス機能を統合し、標準化された地域コントローラーは、配電、データ サービス、地域ゲートウェイの 3 つの主要な役割を担います。したがって、中央演算装置には高スループットのイーサネット スイッチが統合されます。車両全体の統合度がますます高くなるにつれて、より多くの ECU 機能が徐々に地域コントローラーに吸収されるようになります。そしてプラットフォーム化
 Golang フレームワーク アーキテクチャの学習曲線はどれくらい急ですか?
Jun 05, 2024 pm 06:59 PM
Golang フレームワーク アーキテクチャの学習曲線はどれくらい急ですか?
Jun 05, 2024 pm 06:59 PM
Go フレームワーク アーキテクチャの学習曲線は、Go 言語とバックエンド開発への慣れ、選択したフレームワークの複雑さ、つまり Go 言語の基本の十分な理解によって決まります。バックエンドの開発経験があると役立ちます。フレームワークの複雑さが異なると、学習曲線も異なります。
