

Hadoop-Nutch学习整理(持续更新)

Nutch学习整理第一部分 单机尝试1、安装部署Nutch的部署和其他Hadoop生态产品的部署流程基本相:下载软件,上传到服务器,解压文件,修改配置文件。网上有很多类资料,不再赘述。Nutch的配置文件主要有两个: domain-urlfilter.txt 是用来配置所爬取网站的范
Nutch学习整理 第一部分 单机尝试 1、安装部署 Nutch的部署和其他Hadoop生态产品的部署流程基本相似:下载软件,上传到服务器,解压文件,修改配置文件。网上有很多类似资料,不再赘述。 Nutch的配置文件主要有两个:- domain-urlfilter.txt
是用来配置所爬取网站的范围,域名和它的子网页的正则表达式,类似于爬取规则。一般配置为:
# accept hosts in MY.DOMAIN.NAME
+^http://([a-z0-9]*\.)*MY.DOMAIN.NAME/
- nutch-site.xml
这类似于对我要爬取的网站进行一下声明,不声明的话,会导致爬取失败。
2、单机主要爬取命令 简单命令格式,不赘述。 bin/nutch crawl[-dir d] [-threads n] [-depth i] [-topN]
3、爬取结果解析 nutch爬取下来的网页信息,保存路径格式如下:
主要爬取信息保存在路径segments下:
喎?http://www.2cto.com/kf/ware/vc/" target="_blank" class="keylink">vcD4KPHVsPgo8bGk+Q3Jhd2xkYsrHy/nT0NDo0qrXpcihtcSzrMGsvdPQxc+iKLTmt8XPwtTYtcRVUkyjrLywz8LU2LXEyNXG2qOs08PAtNKzw+a4/NDCvOyy6cqxvOSjrNK7sOPU2sXAyKHE2sjdveLO9sq9sru74dPDtb2jqTxsaT5MaW5rZGLW0LTmt8W1xMrHy/nT0LOsway907ywxuTDv7j2way907XEwazI67XY1re6zcOqzsSxvqGjPGxpPlNlZ21lbnRztOa3xdelyKG1xNKzw+ajrNPryc/D5sG0vdPJ7rbIIGRlcHRoIM/gudijrGRlcHRoyejOqry41PLU2iBzZWdtZW50c8/Cyfqzyby4uPbS1MqxvOTD/MP7tcTX087EvP680KGjz8LA/b3YzbzKxwogLWRlcHRoPTMKCjxpbWcgc3JjPQ=="http://www.2cto.com/uploadfile/Collfiles/20141127/2014112709151123.jpg" alt="\">
Segments下的文件夹含义:- crawl_generate :names a set of urls to be fetched
- crawl_fetch : contains the status of fetching each url
- crawl_parse : contains the outlink urls, used to update the crawldb
- content : contains the content of each url
- parse_text : contains the parsed text of each url
- parse_data : contains
outlinks and metadata parsed from each url
Segments是每轮抓取的时候根据crawldb生成的。存放的信息包括6种content、crawl_fetch、crawl_generate、crawl_parse、parse_data、parse_text。其中content是抓取下来的网页内容;crawl_generate最初生成(待下载URL集合);crawl_fetch(每个下载URL的状态)、content在抓取时生成;crawl_parse(包含用来更新crawldb的外链)、parse_data、parse_text在解析抓取的数据文件时生成。 在进行爬取结果导出的时候,六个参数(-nocontent -nofetch -noparse -noparsedata -noparsetext -nogenerate)分别对应需要导出的内容。 导出命令例: [root@master local]# bin/nutch readseg -dump data_1125/segments/20141125020224 data_dump -nocontent -nofetch -nogenerate -noparse -noparsedata
- nutch-site.xml
这类似于对我要爬取的网站进行一下声明,不声明的话,会导致爬取失败。






ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7564
7564
 15
1386
52
87
11
28
100
15
1386
52
87
11
28
100

 Blizzard Battle.net アップデートが 45% で止まってしまう問題を修正するにはどうすればよいですか?
Mar 16, 2024 pm 06:52 PM
Blizzard Battle.net アップデートが 45% で止まってしまう問題を修正するにはどうすればよいですか?
Mar 16, 2024 pm 06:52 PM
Blizzard Battle.net のアップデートが 45% で止まってしまいます。解決するにはどうすればよいですか?最近、ソフトウェア更新時にプログレスバーが 45% で止まってしまうことが多く、何度再起動しても進まないことがありますが、この状況を解決するにはどうすればよいでしょうか? クライアントの再インストール、リージョンの切り替え、ファイルの削除などが考えられます。このソフトウェアチュートリアルでは、より多くの人に役立つことを願って、操作手順を共有します。 Blizzard Battle.net のアップデートが 45% で止まってしまいます、どうすれば解決しますか? 1. クライアント 1. まず、クライアントが公式 Web サイトからダウンロードされた正式バージョンであることを確認する必要があります。 2. そうでない場合、ユーザーはアジアのサーバー Web サイトにアクセスしてダウンロードできます。 3. 入力後、右上隅の「ダウンロード」をクリックします。注: インストール時に簡体字中国語を選択しないようにしてください。
 Ubuntu 24.04 に Angular をインストールする方法
Mar 23, 2024 pm 12:20 PM
Ubuntu 24.04 に Angular をインストールする方法
Mar 23, 2024 pm 12:20 PM
Angular.js は、動的アプリケーションを作成するための無料でアクセスできる JavaScript プラットフォームです。 HTML の構文をテンプレート言語として拡張することで、アプリケーションのさまざまな側面を迅速かつ明確に表現できます。 Angular.js は、コードの作成、更新、テストに役立つさまざまなツールを提供します。さらに、ルーティングやフォーム管理などの多くの機能も提供します。このガイドでは、Ubuntu24 に Angular をインストールする方法について説明します。まず、Node.js をインストールする必要があります。 Node.js は、ChromeV8 エンジンに基づく JavaScript 実行環境で、サーバー側で JavaScript コードを実行できます。ウブにいるために
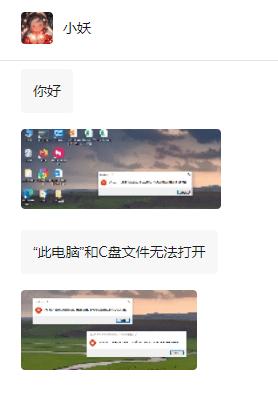 Windows は指定されたデバイス、パス、またはファイルにアクセスできません
Jun 18, 2024 pm 04:49 PM
Windows は指定されたデバイス、パス、またはファイルにアクセスできません
Jun 18, 2024 pm 04:49 PM
友人のコンピュータにはこのような障害があり、「この PC」と C ドライブのファイルを開くと、「Explorer.EXE Windows は指定されたデバイス、パス、またはファイルにアクセスできません。プロジェクトにアクセスするための適切な権限がない可能性があります。」と表示されます。フォルダ、ファイル、このコンピュータ、ごみ箱などを含め、ダブルクリックするとこのようなウィンドウが表示されますが、通常は右クリックで開きます。システムのアップデートが原因でこの状況が発生した場合は、以下のエディターで解決方法を説明します。 1. レジストリ エディターを開いて Win+R と入力し、「regedit」と入力するか、スタート メニューを右クリックして実行し、「regedit」と入力します。 2. レジストリ「Computer\HKEY_CLASSES_ROOT\PackagedCom\ClassInd」を見つけます。
 MSI グラフィックス カード ドライバーを更新するにはどうすればよいですか? MSI グラフィックス カード ドライバーのダウンロードとインストールの手順
Mar 13, 2024 pm 08:49 PM
MSI グラフィックス カード ドライバーを更新するにはどうすればよいですか? MSI グラフィックス カード ドライバーのダウンロードとインストールの手順
Mar 13, 2024 pm 08:49 PM
MSI グラフィックス カードは、市場で主流のグラフィックス カード ブランドです。パフォーマンスを実現し、互換性を確保するには、グラフィックス カードにドライバーをインストールする必要があることがわかっています。では、MSI グラフィックス カード ドライバーを最新バージョンに更新するにはどうすればよいでしょうか?通常、MSI グラフィック カード ドライバーは公式 Web サイトからダウンロードしてインストールできます。グラフィックカードドライバーの更新方法: 1. まず、「MSI公式Webサイト」に入ります。 2. 入力後、右上隅の「検索」ボタンをクリックし、グラフィックス カードのモデルを入力します。 3. 次に、対応するグラフィックス カードを見つけて、詳細ページをクリックします。 4. 次に、上の「テクニカル サポート」オプションを入力します。 5.最後に「ドライバーとダウンロード」に進みます。
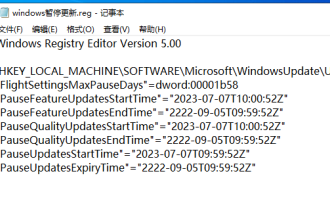 Windows が更新を永久に一時停止し、Windows が自動更新をオフにする
Jun 18, 2024 pm 07:04 PM
Windows が更新を永久に一時停止し、Windows が自動更新をオフにする
Jun 18, 2024 pm 07:04 PM
Windows アップデートにより、次の問題が発生する可能性があります。 1. 互換性の問題: 一部のアプリケーション、ドライバー、またはハードウェア デバイスは、新しい Windows アップデートと互換性がなく、適切に動作しなかったり、クラッシュしたりする可能性があります。 2. パフォーマンスの問題: Windows アップデートにより、システムが遅くなったり、パフォーマンスが低下したりする場合があります。これは、新機能または改善により、実行するためにより多くのリソースが必要になることが原因である可能性があります。 3. システムの安定性の問題: 一部のユーザーは、Windows 更新プログラムをインストールした後、システムで予期しないクラッシュやブルー スクリーン エラーが発生する可能性があると報告しました。 4. データ損失: まれに、Windows アップデートによりデータ損失やファイル破損が発生する場合があります。このため、重要な更新を行う前に、バックアップを作成してください。
 Outlook が受信トレイの更新で停止します。
Mar 25, 2024 am 09:46 AM
Outlook が受信トレイの更新で停止します。
Mar 25, 2024 am 09:46 AM
Outlook で受信トレイの更新に問題が発生すると、生産性に影響が出る可能性があります。この記事では、問題を解決して Outlook を通常の状態に戻すための簡単なトラブルシューティング手順をいくつか紹介します。 Outlook が常に受信トレイの更新で停止するのはなぜですか? Outlook で受信トレイの更新が停止する可能性があります。一般的な理由には、ネットワークの問題、メールボックスの過剰な容量、ウイルス対策ソフトウェアやファイアウォールの影響などが含まれます。破損した外部プラグインまたはデータ ファイルもこの問題を引き起こす可能性があります。次に、これらの考えられる原因を詳細に調査し、解決策を提供します。 Outlook が受信トレイの更新で停止する問題を修正する Outlook が受信トレイを更新できない場合は、以下にリストされている解決策を参照してください。 Outlook を再起動する 無効
 TikTokを最新バージョンにアップデートする方法
Mar 27, 2024 am 11:06 AM
TikTokを最新バージョンにアップデートする方法
Mar 27, 2024 am 11:06 AM
1. Douyin アプリを開き、右下の [Me] をクリックし、右上の [Three Stripes] アイコンをクリックします。 2. [設定]を選択し、クリックして設定インターフェイスに入り、[一般設定]を見つけてクリックします。 3. 一般設定インターフェイスをプルダウンし、[アップデートの確認] を見つけてクリックします。 4. ユーザーが現在使用しているバージョンが最新バージョンでない場合は、新しいバージョンへのアップデートを促すメッセージが表示されますので、[アップグレード]をクリックします。 5. インストールパッケージがダウンロードされるまで待ちます(自動的にインストールされます) [インストールを続行] をクリックします。 6. 現在のバージョンがすでに最新バージョンである場合は、「利用可能な更新バージョンがありません」というプロンプトが表示されます。
 Wordでルート番号を入力する方法を一緒に学びましょう
Mar 19, 2024 pm 08:52 PM
Wordでルート番号を入力する方法を一緒に学びましょう
Mar 19, 2024 pm 08:52 PM
Word でテキスト コンテンツを編集するときに、数式記号の入力が必要になる場合があります。 Word でルート番号を入力する方法を知らない人もいるので、Xiaomian は私に、Word でルート番号を入力する方法のチュートリアルを友達と共有するように頼みました。それが私の友達に役立つことを願っています。まず、コンピュータで Word ソフトウェアを開き、編集するファイルを開き、ルート記号を挿入する必要がある場所にカーソルを移動します。下の図の例を参照してください。 2. [挿入]を選択し、記号内の[数式]を選択します。下の図の赤丸で示すように: 3. 次に、下の[新しい数式を挿入]を選択します。以下の図の赤丸で示すように: 4. [根号式]を選択し、適切な根号を選択します。下の図の赤丸で示したように、
