

HBase入门篇4–存储

前几篇文章讲述了 HBase的安装、Hbase命令和API的使用、HBase简单的优化技巧,《HBase入门篇4》这篇文章是讲述把HBase的数据放在HDFS上的点滴过程。目前对与HBase我是一个绝对的新手,如果在文章中有任何我理解有错误的地方请各位指正,谢谢。 Ok,进行正题
前几篇文章讲述了 HBase的安装、Hbase命令和API的使用、HBase简单的优化技巧,《HBase入门篇4》这篇文章是讲述把HBase的数据放在HDFS上的点滴过程。目前对与HBase我是一个绝对的新手,如果在文章中有任何我理解有错误的地方请各位指正,谢谢。
Ok,进行正题 ………
在HBase中创建的一张表可以分布在多个Hregion,也就说一张表可以被拆分成多块,每一块称我们呼为一个Hregion。每个Hregion会保 存一个表里面某段连续的数据,用户创建的那个大表中的每个Hregion块是由Hregion服务器提供维护,访问Hregion块是要通过 Hregion服务器,而一个Hregion块对应一个Hregion服务器,一张完整的表可以保存在多个Hregion 上。HRegion Server 与Region的对应关系是一对多的关系。每一个HRegion在物理上会被分为三个部分:Hmemcache(缓存)、Hlog(日志)、HStore(持久层)。
上述这些关系在我脑海中的样子,如图所示:
1.HRegionServer、HRegion、Hmemcache、Hlog、HStore之间的关系,如图所示:

2.HBase表中的数据与HRegionServer的分布关系,如图所示:

HBase读数据
HBase读取数据优先读取HMemcache中的内容,如果未取到再去读取Hstore中的数据,提高数据读取的性能。
HBase写数据
HBase写入数据会写到HMemcache和Hlog中,HMemcache建立缓存,Hlog同步Hmemcache和Hstore的事务日志,发起Flush Cache时,数据持久化到Hstore中,并清空HMemecache。
客户端访问这些数据的时候通过Hmaster ,每个 Hregion 服务器都会和Hmaster 服务器保持一个长连接,Hmaster 是HBase分布式系统中的管理者,他的主要任务就是要告诉每个Hregion 服务器它要维护哪些Hregion。用户的这些都数据可以保存在Hadoop 分布式文件系统上。 如果主服务器Hmaster死机,那么整个系统都会无效。下面我会考虑如何解决Hmaster的SPFO的问题,这个问题有点类似Hadoop的SPFO 问题一样只有一个NameNode维护全局的DataNode,HDFS一旦死机全部挂了,也有人说采用Heartbeat来解决这个问题,但我总想找出 其他的解决方案,多点时间,总有办法的。
昨天在hadoop-0.21.0、hbase-0.20.6的环境中折腾了很久,一直报错,错误信息如下:
Exception in thread "main" java.io.IOException: Call to localhost/serv6:9000 failed on local exception: java.io.EOFException
10/11/10 15:34:34 ERROR master.HMaster: Can not start master
java.lang.reflect.InvocationTargetException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:39)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:27)
at java.lang.reflect.Constructor.newInstance(Constructor.java:513)
at org.apache.hadoop.hbase.master.HMaster.doMain(HMaster.java:1233)
at org.apache.hadoop.hbase.master.HMaster.main(HMaster.java:1274)
死活连接不上HDFS,也无法连接HMaster,郁闷啊。
我想想啊,慢慢想,我眼前一亮 java.io.EOFException 这个异常,是不是有可能是RPC 协定格式不一致导致的?也就是说服务器端和客户端的版本不一致的问题?换了一个HDFS的服务器端以后,一切都好了,果然是版本的问题,最后采用 hadoop-0.20.2 搭配hbase-0.20.6 比较稳当。
最后的效果如图所示:
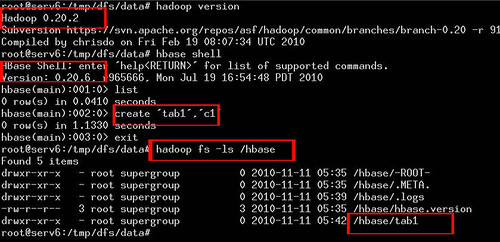
查看大图请点击这里, 上图的一些文字说明:
1.hadoop版本是0.20.2 ,
2.hbase版本是0.20.6,
3.在hbase中创建了一张表 tab1,退出hbase shell环境,
4.用hadoop命令查看,文件系统中的文件果然多了一个刚刚创建的tab1目录,
以上这张图片说明HBase在分布式文件系统Apache HDFS中运行了。
相关文章:
Hbase入门6 -白话MySQL(RDBMS)与HBase之间
Lily-建立在HBase上的分布式搜索
MySQL向Hive/HBase的迁移工具
HBase入门5(集群) -压力分载与失效转发
Hive入门3–Hive与HBase的整合
HBase入门篇4
HBase入门篇3
HBase入门篇2-Java操作HBase例子
HBase入门篇
基于Hbase存储的分布式消息(IM)系统-JABase
–end–

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7322
7322
 9
1625
14
1350
46
1262
25
1209
29
9
1625
14
1350
46
1262
25
1209
29

 パデュー大学による、時間をかける価値のある拡散モデルのチュートリアル
Apr 07, 2024 am 09:01 AM
パデュー大学による、時間をかける価値のある拡散モデルのチュートリアル
Apr 07, 2024 am 09:01 AM
拡散はより良いものを模倣するだけでなく、「創造」することもできます。拡散モデル(DiffusionModel)は、画像生成モデルである。 AI 分野でよく知られている GAN や VAE などのアルゴリズムと比較すると、拡散モデルは異なるアプローチを採用しており、その主な考え方は、最初に画像にノイズを追加し、その後徐々にノイズを除去するプロセスです。ノイズを除去して元の画像を復元する方法は、アルゴリズムの中核部分です。最後のアルゴリズムは、ランダムなノイズを含む画像から画像を生成できます。近年、生成 AI の驚異的な成長により、テキストから画像への生成、ビデオ生成など、多くのエキサイティングなアプリケーションが可能になりました。これらの生成ツールの背後にある基本原理は、以前の方法の制限を克服する特別なサンプリング メカニズムである拡散の概念です。
 ワンクリックでPPTを生成!キミ: まずは「PPT出稼ぎ労働者」を普及させましょう
Aug 01, 2024 pm 03:28 PM
ワンクリックでPPTを生成!キミ: まずは「PPT出稼ぎ労働者」を普及させましょう
Aug 01, 2024 pm 03:28 PM
キミ: たった 1 文の PPT がわずか 10 秒で完成します。 PPTはとても面倒です!会議を開催するには PPT が必要であり、週次報告書を作成するには PPT が必要であり、投資を勧誘するには PPT を提示する必要があり、不正行為を告発するには PPT を送信する必要があります。大学は、PPT 専攻を勉強するようなものです。授業中に PPT を見て、授業後に PPT を行います。おそらく、デニス オースティンが 37 年前に PPT を発明したとき、PPT がこれほど普及する日が来るとは予想していなかったでしょう。 PPT 作成の大変な経験を話すと涙が出ます。 「20 ページを超える PPT を作成するのに 3 か月かかり、何十回も修正しました。PPT を見ると吐きそうになりました。」 「ピーク時には 1 日に 5 枚の PPT を作成し、息をすることさえありました。」 PPTでした。」 即席の会議をするなら、そうすべきです
 Android アプリを Linux にインストールするにはどうすればよいですか?
Mar 19, 2024 am 11:15 AM
Android アプリを Linux にインストールするにはどうすればよいですか?
Mar 19, 2024 am 11:15 AM
Linux への Android アプリケーションのインストールは、多くのユーザーにとって常に懸念事項であり、特に Android アプリケーションを使用したい Linux ユーザーにとって、Android アプリケーションを Linux システムにインストールする方法をマスターすることは非常に重要です。 Linux 上で Android アプリケーションを直接実行するのは Android プラットフォームほど簡単ではありませんが、エミュレータやサードパーティのツールを使用すれば、Linux 上で Android アプリケーションを快適に楽しむことができます。ここでは、Linux システムに Android アプリケーションをインストールする方法を紹介します。
 CVPR 2024 のすべての賞が発表されました!オフラインでのカンファレンスには1万人近くが参加し、Googleの中国人研究者が最優秀論文賞を受賞した
Jun 20, 2024 pm 05:43 PM
CVPR 2024 のすべての賞が発表されました!オフラインでのカンファレンスには1万人近くが参加し、Googleの中国人研究者が最優秀論文賞を受賞した
Jun 20, 2024 pm 05:43 PM
北京時間6月20日早朝、シアトルで開催されている最高の国際コンピュータビジョンカンファレンス「CVPR2024」が、最優秀論文やその他の賞を正式に発表した。今年は、最優秀論文 2 件と学生優秀論文 2 件を含む合計 10 件の論文が賞を受賞しました。また、最優秀論文ノミネートも 2 件、学生優秀論文ノミネートも 4 件ありました。コンピュータービジョン (CV) 分野のトップカンファレンスは CVPR で、毎年多数の研究機関や大学が集まります。統計によると、今年は合計 11,532 件の論文が投稿され、2,719 件が採択され、採択率は 23.6% でした。ジョージア工科大学による CVPR2024 データの統計分析によると、研究テーマの観点から最も論文数が多いのは画像とビデオの合成と生成です (Imageandvideosyn
 技術初心者必読:C言語とPythonの難易度分析
Mar 22, 2024 am 10:21 AM
技術初心者必読:C言語とPythonの難易度分析
Mar 22, 2024 am 10:21 AM
タイトル: 技術初心者必読: 具体的なコード例を必要とする C 言語と Python の難易度分析 今日のデジタル時代において、プログラミング技術はますます重要な能力となっています。ソフトウェア開発、データ分析、人工知能などの分野で働きたい場合でも、単に興味があってプログラミングを学びたい場合でも、適切なプログラミング言語を選択することが最初のステップです。数あるプログラミング言語の中でも、C言語とPythonは広く使われているプログラミング言語であり、それぞれに独自の特徴があります。この記事ではC言語とPythonの難易度を分析します。
 Ubuntu 24.04 に Ubuntu Notes アプリをインストールして実行する方法
Mar 22, 2024 pm 04:40 PM
Ubuntu 24.04 に Ubuntu Notes アプリをインストールして実行する方法
Mar 22, 2024 pm 04:40 PM
高校で勉強しているときに、同じクラスの他の生徒よりも多くのメモを取る、非常に明確で正確なメモを取る生徒もいます。メモをとることが趣味である人もいますが、重要なことについての小さな情報をすぐに忘れてしまうため、メモをとることが必需品である人もいます。 Microsoft の NTFS アプリケーションは、通常の講義以外にも重要なメモを保存したい学生にとって特に役立ちます。この記事では、Ubuntu24へのUbuntuアプリケーションのインストールについて説明します。 Ubuntu システムの更新 Ubuntu インストーラーをインストールする前に、Ubuntu24 では、新しく構成されたシステムが更新されていることを確認する必要があります。 Ubuntu システムでは最も有名な「a」を使用できます
 ベアメタルから 700 億のパラメータを備えた大規模モデルまで、チュートリアルとすぐに使えるスクリプトがここにあります
Jul 24, 2024 pm 08:13 PM
ベアメタルから 700 億のパラメータを備えた大規模モデルまで、チュートリアルとすぐに使えるスクリプトがここにあります
Jul 24, 2024 pm 08:13 PM
LLM が大量のデータを使用して大規模なコンピューター クラスターでトレーニングされていることはわかっています。このサイトでは、LLM トレーニング プロセスを支援および改善するために使用される多くの方法とテクノロジが紹介されています。今日、私たちが共有したいのは、基礎となるテクノロジーを深く掘り下げ、オペレーティング システムさえ持たない大量の「ベア メタル」を LLM のトレーニング用のコンピューター クラスターに変える方法を紹介する記事です。この記事は、機械がどのように考えるかを理解することで一般的な知能の実現に努めている AI スタートアップ企業 Imbue によるものです。もちろん、オペレーティング システムを持たない大量の「ベア メタル」を LLM をトレーニングするためのコンピューター クラスターに変換することは、探索と試行錯誤に満ちた簡単なプロセスではありませんが、Imbue は最終的に 700 億のパラメータを備えた LLM のトレーニングに成功しました。プロセスが蓄積する
 Ubuntu 24.04 に Podman をインストールする方法
Mar 22, 2024 am 11:26 AM
Ubuntu 24.04 に Podman をインストールする方法
Mar 22, 2024 am 11:26 AM
Docker を使用したことがある場合は、デーモン、コンテナー、およびそれらの機能を理解する必要があります。デーモンは、コンテナがシステムですでに使用されているときにバックグラウンドで実行されるサービスです。 Podman は、Docker などのデーモンに依存せずにコンテナーを管理および作成するための無料の管理ツールです。したがって、長期的なバックエンド サービスを必要とせずにコンテナーを管理できるという利点があります。さらに、Podman を使用するにはルートレベルの権限は必要ありません。このガイドでは、Ubuntu24 に Podman をインストールする方法について詳しく説明します。システムを更新するには、まずシステムを更新し、Ubuntu24 のターミナル シェルを開く必要があります。インストールプロセスとアップグレードプロセスの両方で、コマンドラインを使用する必要があります。シンプルな
