

伪分布式安装部署CDH4.2.1与Impala[原创实践]

参考资料: http://www.cloudera.com/content/cloudera-content/cloudera-docs/CDH4/latest/CDH4-Quick-Start/cdh4qs_topic_3_3.html http://www.cloudera.com/content/cloudera-content/cloudera-docs/Impala/latest/Installing-and-Using-Impala/Installing
参考资料:
http://www.cloudera.com/content/cloudera-content/cloudera-docs/CDH4/latest/CDH4-Quick-Start/cdh4qs_topic_3_3.html
http://www.cloudera.com/content/cloudera-content/cloudera-docs/Impala/latest/Installing-and-Using-Impala/Installing-and-Using-Impala.html
http://blog.cloudera.com/blog/2013/02/from-zero-to-impala-in-minutes/
什么是Impala?
Cloudera发布了实时查询开源项目Impala,根据多款产品实测表明,它比原来基于MapReduce的Hive SQL查询速度提升3~90倍。Impala是Google Dremel的模仿,但在SQL功能上青出于蓝胜于蓝。
1. 安装JDK
$ sudo yum install jdk-6u41-linux-amd64.rpm
2. 伪分布式模式安装CDH4
$ cd /etc/yum.repos.d/
$ sudo wget http://archive.cloudera.com/cdh4/redhat/6/x86_64/cdh/cloudera-cdh4.repo
$ sudo yum install hadoop-conf-pseudo
格式化NameNode.
$ sudo -u hdfs hdfs namenode -format
启动HDFS
$ for x in `cd /etc/init.d ; ls hadoop-hdfs-*` ; do sudo service $x start ; done
创建/tmp目录
$ sudo -u hdfs hadoop fs -rm -r /tmp
$ sudo -u hdfs hadoop fs -mkdir /tmp
$ sudo -u hdfs hadoop fs -chmod -R 1777 /tmp
创建YARN与日志目录
$ sudo -u hdfs hadoop fs -mkdir /tmp/hadoop-yarn/staging
$ sudo -u hdfs hadoop fs -chmod -R 1777 /tmp/hadoop-yarn/staging
$ sudo -u hdfs hadoop fs -mkdir /tmp/hadoop-yarn/staging/history/done_intermediate
$ sudo -u hdfs hadoop fs -chmod -R 1777 /tmp/hadoop-yarn/staging/history/done_intermediate
$ sudo -u hdfs hadoop fs -chown -R mapred:mapred /tmp/hadoop-yarn/staging
$ sudo -u hdfs hadoop fs -mkdir /var/log/hadoop-yarn
$ sudo -u hdfs hadoop fs -chown yarn:mapred /var/log/hadoop-yarn
检查HDFS文件树
$ sudo -u hdfs hadoop fs -ls -R /
drwxrwxrwt - hdfs supergroup 0 2012-05-31 15:31 /tmp drwxr-xr-x - hdfs supergroup 0 2012-05-31 15:31 /tmp/hadoop-yarn drwxrwxrwt - mapred mapred 0 2012-05-31 15:31 /tmp/hadoop-yarn/staging drwxr-xr-x - mapred mapred 0 2012-05-31 15:31 /tmp/hadoop-yarn/staging/history drwxrwxrwt - mapred mapred 0 2012-05-31 15:31 /tmp/hadoop-yarn/staging/history/done_intermediate drwxr-xr-x - hdfs supergroup 0 2012-05-31 15:31 /var drwxr-xr-x - hdfs supergroup 0 2012-05-31 15:31 /var/log drwxr-xr-x - yarn mapred 0 2012-05-31 15:31 /var/log/hadoop-yarn
启动YARN
$ sudo service hadoop-yarn-resourcemanager start
$ sudo service hadoop-yarn-nodemanager start
$ sudo service hadoop-mapreduce-historyserver start
创建用户目录(以用户dong.guo为例):
$ sudo -u hdfs hadoop fs -mkdir /user/dong.guo
$ sudo -u hdfs hadoop fs -chown dong.guo /user/dong.guo
测试上传文件
$ hadoop fs -mkdir input
$ hadoop fs -put /etc/hadoop/conf/*.xml input
$ hadoop fs -ls input
Found 4 items -rw-r--r-- 1 dong.guo supergroup 1461 2013-05-14 03:30 input/core-site.xml -rw-r--r-- 1 dong.guo supergroup 1854 2013-05-14 03:30 input/hdfs-site.xml -rw-r--r-- 1 dong.guo supergroup 1325 2013-05-14 03:30 input/mapred-site.xml -rw-r--r-- 1 dong.guo supergroup 2262 2013-05-14 03:30 input/yarn-site.xml
配置HADOOP_MAPRED_HOME环境变量
$ export HADOOP_MAPRED_HOME=/usr/lib/hadoop-mapreduce
运行一个测试Job
$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar grep input output23 'dfs[a-z.]+'
Job完成后,可以看到以下目录
$ hadoop fs -ls
Found 2 items drwxr-xr-x - dong.guo supergroup 0 2013-05-14 03:30 input drwxr-xr-x - dong.guo supergroup 0 2013-05-14 03:32 output23
$ hadoop fs -ls output23
Found 2 items -rw-r--r-- 1 dong.guo supergroup 0 2013-05-14 03:32 output23/_SUCCESS -rw-r--r-- 1 dong.guo supergroup 150 2013-05-14 03:32 output23/part-r-00000
$ hadoop fs -cat output23/part-r-00000 | head
1 dfs.safemode.min.datanodes 1 dfs.safemode.extension 1 dfs.replication 1 dfs.namenode.name.dir 1 dfs.namenode.checkpoint.dir 1 dfs.datanode.data.dir
3. 安装 Hive
$ sudo yum install hive hive-metastore hive-server
$ sudo yum install mysql-server
$ sudo service mysqld start
$ cd ~
$ wget 'http://cdn.mysql.com/Downloads/Connector-J/mysql-connector-java-5.1.25.tar.gz'
$ tar xzf mysql-connector-java-5.1.25.tar.gz
$ sudo cp mysql-connector-java-5.1.25/mysql-connector-java-5.1.25-bin.jar /usr/lib/hive/lib/
$ sudo /usr/bin/mysql_secure_installation
[...] Enter current password for root (enter for none): OK, successfully used password, moving on... [...] Set root password? [Y/n] y New password:hadoophive Re-enter new password:hadoophive Remove anonymous users? [Y/n] Y [...] Disallow root login remotely? [Y/n] N [...] Remove test database and access to it [Y/n] Y [...] Reload privilege tables now? [Y/n] Y All done!
$ mysql -u root -phadoophive
mysql> CREATE DATABASE metastore; mysql> USE metastore; mysql> SOURCE /usr/lib/hive/scripts/metastore/upgrade/mysql/hive-schema-0.10.0.mysql.sql; mysql> CREATE USER 'hive'@'%' IDENTIFIED BY 'hadoophive'; mysql> CREATE USER 'hive'@'localhost' IDENTIFIED BY 'hadoophive'; mysql> REVOKE ALL PRIVILEGES, GRANT OPTION FROM 'hive'@'%'; mysql> REVOKE ALL PRIVILEGES, GRANT OPTION FROM 'hive'@'localhost'; mysql> GRANT SELECT,INSERT,UPDATE,DELETE,LOCK TABLES,EXECUTE ON metastore.* TO 'hive'@'%'; mysql> GRANT SELECT,INSERT,UPDATE,DELETE,LOCK TABLES,EXECUTE ON metastore.* TO 'hive'@'localhost'; mysql> FLUSH PRIVILEGES; mysql> quit;
$ sudo mv /etc/hive/conf/hive-site.xml /etc/hive/conf/hive-site.xml.bak
$ sudo vim /etc/hive/conf/hive-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="http://heylinux.com/archives/configuration.xsl"?> javax.jdo.option.ConnectionURL jdbc:mysql://localhost/metastore the URL of the MySQL database javax.jdo.option.ConnectionDriverName com.mysql.jdbc.Driver javax.jdo.option.ConnectionUserName hive javax.jdo.option.ConnectionPassword hadoophive datanucleus.autoCreateSchema false datanucleus.fixedDatastore true hive.metastore.uris thrift://127.0.0.1:9083 IP address (or fully-qualified domain name) and port of the metastore host hive.aux.jars.path file:///usr/lib/hive/lib/zookeeper.jar,file:///usr/lib/hive/lib/hbase.jar,file:///usr/lib/hive/lib/hive-hbase-handler-0.10.0-cdh4.2.0.jar,file:///usr/lib/hive/lib/guava-11.0.2.jar
$ sudo service hive-metastore start
Starting (hive-metastore): [ OK ]
$ sudo service hive-server start
Starting (hive-server): [ OK ]
$ sudo -u hdfs hadoop fs -mkdir /user/hive
$ sudo -u hdfs hadoop fs -chown hive /user/hive
$ sudo -u hdfs hadoop fs -mkdir /tmp
$ sudo -u hdfs hadoop fs -chmod 777 /tmp
$ sudo -u hdfs hadoop fs -chmod o+t /tmp
$ sudo -u hdfs hadoop fs -mkdir /data
$ sudo -u hdfs hadoop fs -chown hdfs /data
$ sudo -u hdfs hadoop fs -chmod 777 /data
$ sudo -u hdfs hadoop fs -chmod o+t /data
$ sudo chown -R hive:hive /var/lib/hive
$ sudo vim /tmp/kv1.txt
1 www.baidu.com 2 www.google.com 3 www.sina.com.cn 4 www.163.com 5 heylinx.com
$ sudo -u hive hive
Logging initialized using configuration in file:/etc/hive/conf.dist/hive-log4j.properties Hive history file=/tmp/root/hive_job_log_root_201305140801_825709760.txt hive> CREATE TABLE IF NOT EXISTS pokes ( foo INT,bar STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t" LINES TERMINATED BY "\n"; hive> show tables; OK pokes Time taken: 0.415 seconds hive> LOAD DATA LOCAL INPATH '/tmp/kv1.txt' OVERWRITE INTO TABLE pokes; Copying data from file:/tmp/kv1.txt Copying file: file:/tmp/kv1.txt Loading data to table default.pokes rmr: DEPRECATED: Please use 'rm -r' instead. Deleted /user/hive/warehouse/pokes Table default.pokes stats: [num_partitions: 0, num_files: 1, num_rows: 0, total_size: 79, raw_data_size: 0] OK Time taken: 1.681 seconds
$ export HADOOP_MAPRED_HOME=/usr/lib/hadoop-mapreduce
4. 安装 Impala
$ cd /etc/yum.repos.d/
$ sudo wget http://archive.cloudera.com/impala/redhat/6/x86_64/impala/cloudera-impala.repo
$ sudo yum install impala impala-shell
$ sudo yum install impala-server impala-state-store
$ sudo vim /etc/hadoop/conf/hdfs-site.xml
... dfs.client.read.shortcircuit true dfs.domain.socket.path /var/run/hadoop-hdfs/dn._PORT dfs.client.file-block-storage-locations.timeout 3000 dfs.datanode.hdfs-blocks-metadata.enabled true
$ sudo cp -rpa /etc/hadoop/conf/core-site.xml /etc/impala/conf/
$ sudo cp -rpa /etc/hadoop/conf/hdfs-site.xml /etc/impala/conf/
$ sudo service hadoop-hdfs-datanode restart
$ sudo service impala-state-store restart
$ sudo service impala-server restart
$ sudo /usr/java/default/bin/jps
5. 安装 Hbase
$ sudo yum install hbase
$ sudo vim /etc/security/limits.conf
hdfs - nofile 32768 hbase - nofile 32768
$ sudo vim /etc/pam.d/common-session
session required pam_limits.so
$ sudo vim /etc/hadoop/conf/hdfs-site.xml
dfs.datanode.max.xcievers 4096
$ sudo cp /usr/lib/impala/lib/hive-hbase-handler-0.10.0-cdh4.2.0.jar /usr/lib/hive/lib/hive-hbase-handler-0.10.0-cdh4.2.0.jar
$ sudo /etc/init.d/hadoop-hdfs-namenode restart
$ sudo /etc/init.d/hadoop-hdfs-datanode restart
$ sudo yum install hbase-master
$ sudo service hbase-master start
$ sudo -u hive hive
Logging initialized using configuration in file:/etc/hive/conf.dist/hive-log4j.properties
Hive history file=/tmp/hive/hive_job_log_hive_201305140905_2005531704.txt
hive> CREATE TABLE hbase_table_1(key int, value string) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:val") TBLPROPERTIES ("hbase.table.name" = "xyz");
OK
Time taken: 3.587 seconds
hive> INSERT OVERWRITE TABLE hbase_table_1 SELECT * FROM pokes WHERE foo=5;
Total MapReduce jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1368502088579_0004, Tracking URL = http://ip-10-197-10-4:8088/proxy/application_1368502088579_0004/
Kill Command = /usr/lib/hadoop/bin/hadoop job -kill job_1368502088579_0004
Hadoop job information for Stage-0: number of mappers: 1; number of reducers: 0
2013-05-14 09:12:45,340 Stage-0 map = 0%, reduce = 0%
2013-05-14 09:12:53,165 Stage-0 map = 100%, reduce = 0%, Cumulative CPU 2.63 sec
MapReduce Total cumulative CPU time: 2 seconds 630 msec
Ended Job = job_1368502088579_0004
1 Rows loaded to hbase_table_1
MapReduce Jobs Launched:
Job 0: Map: 1 Cumulative CPU: 2.63 sec HDFS Read: 288 HDFS Write: 0 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 630 msec
OK
Time taken: 21.063 seconds
hive> select * from hbase_table_1;
OK
5 heylinx.com
Time taken: 0.685 seconds
hive> SELECT COUNT (*) FROM pokes;
Total MapReduce jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapred.reduce.tasks=<number>
Starting Job = job_1368502088579_0005, Tracking URL = http://ip-10-197-10-4:8088/proxy/application_1368502088579_0005/
Kill Command = /usr/lib/hadoop/bin/hadoop job -kill job_1368502088579_0005
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2013-05-14 10:32:04,711 Stage-1 map = 0%, reduce = 0%
2013-05-14 10:32:11,461 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:12,554 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:13,642 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:14,760 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:15,918 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:16,991 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:18,111 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:19,188 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.04 sec
MapReduce Total cumulative CPU time: 4 seconds 40 msec
Ended Job = job_1368502088579_0005
MapReduce Jobs Launched:
Job 0: Map: 1 Reduce: 1 Cumulative CPU: 4.04 sec HDFS Read: 288 HDFS Write: 2 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 40 msec
OK
5
Time taken: 28.195 seconds
</number></number></number>6. 测试Impala性能
View parameters on http://ec2-204-236-182-78.us-west-1.compute.amazonaws.com:25000
$ impala-shell
[ip-10-197-10-4.us-west-1.compute.internal:21000] > CREATE TABLE IF NOT EXISTS pokes ( foo INT,bar STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t" LINES TERMINATED BY "\n"; Query: create TABLE IF NOT EXISTS pokes ( foo INT,bar STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t" LINES TERMINATED BY "\n" [ip-10-197-10-4.us-west-1.compute.internal:21000] > show tables; Query: show tables Query finished, fetching results ... +-------+ | name | +-------+ | pokes | +-------+ Returned 1 row(s) in 0.00s [ip-10-197-10-4.us-west-1.compute.internal:21000] > SELECT * from pokes; Query: select * from pokes Query finished, fetching results ... +-----+-----------------+ | foo | bar | +-----+-----------------+ | 1 | www.baidu.com | | 2 | www.google.com | | 3 | www.sina.com.cn | | 4 | www.163.com | | 5 | heylinx.com | +-----+-----------------+ Returned 5 row(s) in 0.28s [ip-10-197-10-4.us-west-1.compute.internal:21000] > SELECT COUNT (*) from pokes; Query: select COUNT (*) from pokes Query finished, fetching results ... +----------+ | count(*) | +----------+ | 5 | +----------+ Returned 1 row(s) in 0.34s
通过两个COUNT的结果来看,Hive使用了 28.195 seconds 而 Impala仅使用了0.34s,由此可以看出Impala的性能确实要优于Hive。
原文地址:伪分布式安装部署CDH4.2.1与Impala[原创实践], 感谢原作者分享。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1659
1659
 14
1416
52
1310
25
1258
29
1232
24
14
1416
52
1310
25
1258
29
1232
24

 Win11システムに中国語言語パックをインストールできない問題の解決策
Mar 09, 2024 am 09:48 AM
Win11システムに中国語言語パックをインストールできない問題の解決策
Mar 09, 2024 am 09:48 AM
Win11 システムに中国語言語パックをインストールできない問題の解決策 Windows 11 システムの発売に伴い、多くのユーザーは新しい機能やインターフェイスを体験するためにオペレーティング システムをアップグレードし始めました。ただし、一部のユーザーは、アップグレード後に中国語の言語パックをインストールできず、エクスペリエンスに問題が発生したことに気づきました。この記事では、Win11 システムに中国語言語パックをインストールできない理由について説明し、ユーザーがこの問題を解決するのに役立ついくつかの解決策を提供します。原因分析 まず、Win11 システムの機能不全を分析しましょう。
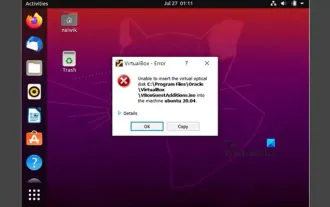 VirtualBox にゲスト追加機能をインストールできない
Mar 10, 2024 am 09:34 AM
VirtualBox にゲスト追加機能をインストールできない
Mar 10, 2024 am 09:34 AM
OracleVirtualBox の仮想マシンにゲスト追加をインストールできない場合があります。 [デバイス] > [InstallGuestAdditionsCDImage] をクリックすると、以下に示すようなエラーがスローされます。 VirtualBox - エラー: 仮想ディスク C: プログラミング ファイルOracleVirtualBoxVBoxGuestAdditions.iso を ubuntu マシンに挿入できません この投稿では、次の場合に何が起こるかを理解します。 VirtualBox にゲスト追加機能をインストールできません。 VirtualBox にゲスト追加機能をインストールできない Virtua にインストールできない場合
 Baidu Netdisk は正常にダウンロードされたものの、インストールできない場合はどうすればよいですか?
Mar 13, 2024 pm 10:22 PM
Baidu Netdisk は正常にダウンロードされたものの、インストールできない場合はどうすればよいですか?
Mar 13, 2024 pm 10:22 PM
Baidu Netdisk のインストール ファイルを正常にダウンロードしたにもかかわらず、正常にインストールできない場合は、ソフトウェア ファイルの整合性にエラーがあるか、残っているファイルとレジストリ エントリに問題がある可能性があります。 Baidu Netdisk はダウンロードできましたが、インストールできない問題の分析を紹介します。 Baidu Netdisk は正常にダウンロードされたがインストールできない問題の分析 1. インストール ファイルの整合性を確認します。ダウンロードしたインストール ファイルが完全で、破損していないことを確認します。再度ダウンロードするか、別の信頼できるソースからインストール ファイルをダウンロードしてみてください。 2. ウイルス対策ソフトウェアとファイアウォールをオフにする: ウイルス対策ソフトウェアやファイアウォール プログラムによっては、インストール プログラムが正常に実行されない場合があります。ウイルス対策ソフトウェアとファイアウォールを無効にするか終了してから、インストールを再実行してください。
 Android アプリを Linux にインストールするにはどうすればよいですか?
Mar 19, 2024 am 11:15 AM
Android アプリを Linux にインストールするにはどうすればよいですか?
Mar 19, 2024 am 11:15 AM
Linux への Android アプリケーションのインストールは、多くのユーザーにとって常に懸念事項であり、特に Android アプリケーションを使用したい Linux ユーザーにとって、Android アプリケーションを Linux システムにインストールする方法をマスターすることは非常に重要です。 Linux 上で Android アプリケーションを直接実行するのは Android プラットフォームほど簡単ではありませんが、エミュレータやサードパーティのツールを使用すれば、Linux 上で Android アプリケーションを快適に楽しむことができます。ここでは、Linux システムに Android アプリケーションをインストールする方法を紹介します。
 Ubuntu 24.04 に Podman をインストールする方法
Mar 22, 2024 am 11:26 AM
Ubuntu 24.04 に Podman をインストールする方法
Mar 22, 2024 am 11:26 AM
Docker を使用したことがある場合は、デーモン、コンテナー、およびそれらの機能を理解する必要があります。デーモンは、コンテナがシステムですでに使用されているときにバックグラウンドで実行されるサービスです。 Podman は、Docker などのデーモンに依存せずにコンテナーを管理および作成するための無料の管理ツールです。したがって、長期的なバックエンド サービスを必要とせずにコンテナーを管理できるという利点があります。さらに、Podman を使用するにはルートレベルの権限は必要ありません。このガイドでは、Ubuntu24 に Podman をインストールする方法について詳しく説明します。システムを更新するには、まずシステムを更新し、Ubuntu24 のターミナル シェルを開く必要があります。インストールプロセスとアップグレードプロセスの両方で、コマンドラインを使用する必要があります。シンプルな
 Win7 コンピューターに Go 言語をインストールする詳細な手順
Mar 27, 2024 pm 02:00 PM
Win7 コンピューターに Go 言語をインストールする詳細な手順
Mar 27, 2024 pm 02:00 PM
Win7 コンピュータに Go 言語をインストールする詳細な手順 Go (Golang とも呼ばれます) は、Google によって開発されたオープン ソース プログラミング言語です。シンプルで効率的で、優れた同時実行パフォーマンスを備えています。クラウド サービス、ネットワーク アプリケーション、およびアプリケーションの開発に適しています。バックエンド システムです。 Win7 コンピューターに Go 言語をインストールすると、その言語をすぐに使い始めて、Go プログラムの作成を開始できるようになります。以下では、Win7 コンピューターに Go 言語をインストールする手順を詳しく紹介し、具体的なコード例を添付します。ステップ 1: Go 言語インストール パッケージをダウンロードし、Go 公式 Web サイトにアクセスします。
 Ubuntu 24.04 に Ubuntu Notes アプリをインストールして実行する方法
Mar 22, 2024 pm 04:40 PM
Ubuntu 24.04 に Ubuntu Notes アプリをインストールして実行する方法
Mar 22, 2024 pm 04:40 PM
高校で勉強しているときに、同じクラスの他の生徒よりも多くのメモを取る、非常に明確で正確なメモを取る生徒もいます。メモをとることが趣味である人もいますが、重要なことについての小さな情報をすぐに忘れてしまうため、メモをとることが必需品である人もいます。 Microsoft の NTFS アプリケーションは、通常の講義以外にも重要なメモを保存したい学生にとって特に役立ちます。この記事では、Ubuntu24へのUbuntuアプリケーションのインストールについて説明します。 Ubuntu システムの更新 Ubuntu インストーラーをインストールする前に、Ubuntu24 では、新しく構成されたシステムが更新されていることを確認する必要があります。 Ubuntu システムでは最も有名な「a」を使用できます
 Win7システムにGo言語をインストールするにはどうすればよいですか?
Mar 27, 2024 pm 01:42 PM
Win7システムにGo言語をインストールするにはどうすればよいですか?
Mar 27, 2024 pm 01:42 PM
Win7 システムに Go 言語をインストールするのは比較的簡単な操作で、次の手順に従ってください。以下では、Win7 システムに Go 言語をインストールする方法を詳しく紹介します。ステップ 1: Go 言語のインストール パッケージをダウンロードする. まず、Go 言語の公式 Web サイト (https://golang.org/) を開いて、ダウンロード ページに入ります。ダウンロード ページで、Win7 システムと互換性のあるインストール パッケージのバージョンを選択してダウンロードします。 [ダウンロード] ボタンをクリックし、インストール パッケージがダウンロードされるまで待ちます。ステップ 2: Go 言語をインストールする
