

HBase实战系列1—压缩与编码技术

1、hbase压缩与编码的配置 安装LZO 解决方案: 1)apt-get install liblzo2-dev 2)hadoop-gpl-compression-0.2.0-dev.jar 放入classpath 把libgpl下的共享库文件放入/opt/hbase/hbase/lib/native/Linux-amd64-64/ libgplcompression.a libgplcompression.la
1、hbase压缩与编码的配置
安装LZO
解决方案:
1)apt-get install liblzo2-dev
2)hadoop-gpl-compression-0.2.0-dev.jar 放入classpath
把libgpl下的共享库文件放入/opt/hbase/hbase/lib/native/Linux-amd64-64/
libgplcompression.a libgplcompression.la libgplcompression.so libgplcompression.so.0 libgplcompression.so.0.0.0
3)配置:
4)测试:
hbase org.apache.hadoop.hbase.util.CompressionTest hdfs:///user.dat lzo
创建表格时,针对ColumnFamily设置压缩和编码方式。
HColumnDescriptor.setCompressionType(Compression.Algorithm.NONE);
HColumnDescriptor.setDataBlockEncoding(DataBlockEncoding.NONE);
使用FAST_DIFF 与 LZO之后的压缩情况:
hbase@GS-WDE-SEV0151:/opt/hbase/hbase$ hadoop fs -dus /hbase-weibo/weibo_test
hdfs://hbase-hdfs.goso.cn:9000/hbase-weibo/weibo_test???? 1021877013
hbase@GS-WDE-SEV0151:/opt/hbase/hbase$ hadoop fs -dus /hbase-weibo/weibo_lzo
hdfs://hbase-hdfs.goso.cn:9000/hbase-weibo/weibo_lzo???? 1179175365
hbase@GS-WDE-SEV0151:/opt/hbase/ops$ hadoop fs -dus /hbase-weibo/weibo_diff
hdfs://hbase-hdfs.goso.cn:9000/hbase-weibo/weibo_diff???? 2754679243
hbase@GS-WDE-SEV0151:/opt/hbase/hbase$ hadoop fs -dus /hbase-weibo/weibo-new
hdfs://hbase-hdfs.goso.cn:9000/hbase-weibo/weibo-new???? 5270708315
忽略数据中出现的Delete的数据、多个版本、以及超时的数据,压缩比达到1:5。
单独使用LZO的配置的压缩可接近也接近5:1的压缩比。
单独使用FAST_DIFF编码可以接近5:2的压缩比。
HBase操作过程:
Finish DataBlock–>Encoding DataBlock(FAST_DIFF\PREFIX\PREFIX_TRIE\DIFF)—>Compression DataBlock(LZO\GZ) —>Flush到磁盘。
如果Encoding和Compression的方式都设置NONE,中间的过程即可忽略。
2、相关测试
weibo-new使用的NONE、NONE
weibo_test使用的LZO、FAST_DIFF
weibo_diff使用了FAST_DIFF
weibo_lzo使用了LZO压缩
1、测试 扫描的效率:
| 个数 | 耗时 | |
| weibo_test | 2314054 | ??3m49.661s |
| weibo-new | 2314054 | ??1m55.349s |
| weibo_lzo | 2314054 | ? 3m24.378s |
| weibo_diff | 2314054 | ?4m41.792s |
结果分析:
使用LZO压缩或者FAST_DIFF的编码,扫描时造成大概一倍的开销
这个原因在于:在当前存储容量下,网络IO不是瓶颈,使用基本配置weibo-new吞吐量达到了45.68MB/s,而使用LZO压缩,显然经过一次或者两次解码之后,消耗了一些CPU时间片,从而耗时较长。
2、随机读的效率,采用单条随机的办法
首先scan出所有的Row,然后,使用shuf -n1000000 /tmp/row 随机取出1000000个row,然后按照单线程随机读的方式获取。
ps:每个Record有3个ColumnFamily,共有31个Column。
| 个数 | 耗时 | |
| weibo_test | 100,0000 | 122min12s, 平均7.3ms/Record |
| weibo-new | 100,0000 | 68min40s, 平均3.99ms/Record |
| weibo_lzo | 100,0000 | 83m26.539s, 平均5.00ms/Record |
| weibo_diff | 100,0000 | 58m5.915s, ?平均3.48ms/Record |

结果分析:
1)LZO解压缩的效率低于反解码的效率,在不以存储代价为第一考虑的情况下,优先选择FAST_DIFF编码方式。
2)LZO随机读会引起 hbase内部更多的读开销。下图在读取同样数据过程中,通过对于RegionServer上scanner采集到的读取个数,lzo明显代价较大。
3)在数据量不超过1T,并且HBase集群内存可以完全cover住整个Cache的情况下,可以不做压缩或者编码的设置,一般带有ROWCOL的bloomfilter基本就可以达到系统最佳的状态。如果数据远远大于Cache总量的10倍以上,优先使用编码方案(FAST_DIFF或者0.96引入的PREFIX_TRIE)
3、随机写的效率,采用批量写。批量个数为100
| 个数 | 耗时 | |
| weibo_test | 8640447 | 571670ms, 66μs/Put, 6.61ms/batch |
| weibo-new | 8640447 | 329694ms,38.12μs/Put,? 3.81ms/batch |
| weibo_lzo | 8640447 | 295770ms, 34.23μs/Put, 3.42ms/batch |
| weibo_diff | 8640447 | 250399ms, 28.97μs/Put,2.90ms/batch |
lz vs diff 写操作的集群吞吐图(两者开始执行的时间起点不同, 绿线代表weibo_diff、红线是weibo_lzo)
?

结论分析:
1)批量写操作,使用FAST_DIFF编码的开销最小,性能比不做任何配置(weibo-new)有24%提升。
2)使用diff,lzo双重配置,批量写操作有较大开销,并且压缩没有比单独使用LZO压缩有明显提升,所以不建议同时使用。
3、总体结论分析
1)在column较多、并且value较短的情况下,使用FAST_DIFF可以获得较好的压缩空间以及较优的读写延迟。推荐使用。
2)在对于存储空间比较紧缺的应用,单独使用LZO压缩,可以在牺牲一些随机读的前提下获得较高的空间压缩率(5:1)。
备注:本系列文章属于Binos_ICT在Binospace个人技术博客原创,原文链接为http://www.binospace.com/index.php/hbase-combat-series-1-compression-and-coding-techniques/?,未经允许,不得在网上转载。
From Binospace, post HBase实战系列1—压缩与编码技术
文章的脚注信息由WordPress的wp-posturl插件自动生成
Copyright © 2008
This feed is for personal, non-commercial use only.
The use of this feed on other websites breaches copyright. If this content is not in your news reader, it makes the page you are viewing an infringement of the copyright. (Digital Fingerprint:
)

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7346
7346
 15
1627
14
1352
52
1265
25
1214
29
15
1627
14
1352
52
1265
25
1214
29

 自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転では軌道予測が重要な役割を果たしており、自動運転軌道予測とは、車両の走行過程におけるさまざまなデータを分析し、将来の車両の走行軌跡を予測することを指します。自動運転のコアモジュールとして、軌道予測の品質は下流の計画制御にとって非常に重要です。軌道予測タスクには豊富な技術スタックがあり、自動運転の動的/静的知覚、高精度地図、車線境界線、ニューラル ネットワーク アーキテクチャ (CNN&GNN&Transformer) スキルなどに精通している必要があります。始めるのは非常に困難です。多くのファンは、できるだけ早く軌道予測を始めて、落とし穴を避けたいと考えています。今日は、軌道予測に関するよくある問題と入門的な学習方法を取り上げます。関連知識の紹介 1. プレビュー用紙は整っていますか? A: まずアンケートを見てください。
 Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3 の論文がついに登場しました!このモデルは2週間前にリリースされ、Soraと同じDiT(DiffusionTransformer)アーキテクチャを採用しており、リリースされると大きな話題を呼びました。前バージョンと比較して、StableDiffusion3で生成される画像の品質が大幅に向上し、マルチテーマプロンプトに対応したほか、テキスト書き込み効果も向上し、文字化けが発生しなくなりました。 StabilityAI は、StableDiffusion3 はパラメータ サイズが 800M から 8B までの一連のモデルであると指摘しました。このパラメーター範囲は、モデルを多くのポータブル デバイス上で直接実行できることを意味し、AI の使用を大幅に削減します。
 7-zipの最大圧縮率設定、7zipを最小まで圧縮する方法
Jun 18, 2024 pm 06:12 PM
7-zipの最大圧縮率設定、7zipを最小まで圧縮する方法
Jun 18, 2024 pm 06:12 PM
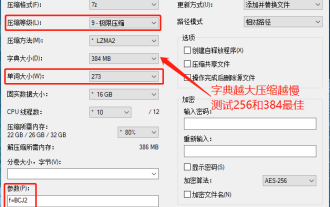
ダウンロード Web サイトからダウンロードした圧縮パッケージは、解凍後に元の圧縮パッケージよりも大きくなり、クラウド ディスクにアップロードすると、小さいものでは数十 MB の差が生じることがわかりました。有料のスペースは、ファイルが小さい場合は問題ありませんが、ファイルが多数ある場合、ストレージのコストが大幅に増加します。私はそれを具体的に勉強したので、必要に応じてそこから学ぶことができます。圧縮レベル: 9-極度の圧縮 辞書サイズ: 256 または 384、辞書が圧縮されるほど遅くなります。256MB より前では圧縮率に大きな違いがあり、384MB 以降では圧縮率に違いはありません。最大 273 パラメータ: f=BCJ2、テストおよび追加パラメータの圧縮率が高くなります
 DualBEV: BEVFormer および BEVDet4D を大幅に上回る、本を開いてください!
Mar 21, 2024 pm 05:21 PM
DualBEV: BEVFormer および BEVDet4D を大幅に上回る、本を開いてください!
Mar 21, 2024 pm 05:21 PM
この論文では、自動運転においてさまざまな視野角 (遠近法や鳥瞰図など) から物体を正確に検出するという問題、特に、特徴を遠近法 (PV) 空間から鳥瞰図 (BEV) 空間に効果的に変換する方法について検討します。 Visual Transformation (VT) モジュールを介して実装されます。既存の手法は、2D から 3D への変換と 3D から 2D への変換という 2 つの戦略に大別されます。 2D から 3D への手法は、深さの確率を予測することで高密度の 2D フィーチャを改善しますが、特に遠方の領域では、深さ予測に固有の不確実性により不正確さが生じる可能性があります。 3D から 2D への方法では通常、3D クエリを使用して 2D フィーチャをサンプリングし、Transformer を通じて 3D と 2D フィーチャ間の対応のアテンション ウェイトを学習します。これにより、計算時間と展開時間が増加します。
 PHP 実践: フィボナッチ数列をすばやく実装するコード例
Mar 20, 2024 pm 02:24 PM
PHP 実践: フィボナッチ数列をすばやく実装するコード例
Mar 20, 2024 pm 02:24 PM
PHP の実践: フィボナッチ数列をすばやく実装するためのコード例 フィボナッチ数列は、数学では非常に興味深い一般的な数列です。次のように定義されています: 最初と 2 番目の数値は 0 と 1、3 番目からは数値で始まり、それぞれの数値前の 2 つの数値の合計です。フィボナッチ数列の最初のいくつかの数値は、0、1、1.2、3、5、8、13、21 などです。 PHP では、再帰と反復を通じてフィボナッチ数列を生成できます。以下ではこの2つを紹介していきます
 Xiaomi 15シリーズの完全なコードネームが明らかに:Dada、Haotian、Xuanyuan
Aug 22, 2024 pm 06:47 PM
Xiaomi 15シリーズの完全なコードネームが明らかに:Dada、Haotian、Xuanyuan
Aug 22, 2024 pm 06:47 PM
Xiaomi Mi 15シリーズは10月に正式リリースされる予定で、その全シリーズのコードネームが海外メディアのMiCodeコードベースで公開されている。その中でもフラッグシップモデルであるXiaomi Mi 15 Ultraのコードネームは「Xuanyuan」(「玄源」の意味)です。この名前は中国神話に登場する高貴さを象徴する黄帝に由来しています。 Xiaomi 15のコードネームは「Dada」、Xiaomi 15Proのコード名は「Haotian」(「好天」の意味)です。 Xiaomi Mi 15S Proの内部コード名は「dijun」で、「山と海の古典」の創造神である淳皇帝を暗示しています。 Xiaomi 15Ultra シリーズのカバー
 Huawei Mate 60シリーズ、新しいAI排除+イメージアップグレード、秋のプロモーションを楽しむのに最適な時期
Aug 29, 2024 pm 03:33 PM
Huawei Mate 60シリーズ、新しいAI排除+イメージアップグレード、秋のプロモーションを楽しむのに最適な時期
Aug 29, 2024 pm 03:33 PM
昨年Huawei Mate60シリーズが発売されて以来、個人的にはMate60Proをメインで使っています。ほぼ1年の間に、Huawei Mate60Proは複数のOTAアップグレードを受け、全体的なエクスペリエンスが大幅に向上し、人々に常に新しい感覚を与えました。たとえば、最近、Huawei Mate60 シリーズは再びイメージング機能の大幅なアップグレードを受けました。 1 つ目は、新しい AI 除去機能で、通行人やゴミをインテリジェントに除去し、空白領域を自動的に埋めることができます。2 つ目は、メインカメラの色の精度と望遠の鮮明さが大幅に向上しました。新学期シーズンであることを考慮して、Huawei Mate60シリーズは秋のプロモーションも開始しました。携帯電話の購入時に最大800元の割引が受けられ、開始価格は4,999元という低価格です。よく使われる、価値の高い新製品が多い
 単なる 3D ガウス以上のもの!最先端の 3D 再構成技術の最新概要
Jun 02, 2024 pm 06:57 PM
単なる 3D ガウス以上のもの!最先端の 3D 再構成技術の最新概要
Jun 02, 2024 pm 06:57 PM
上記と著者の個人的な理解は、画像ベースの 3D 再構成は、一連の入力画像からオブジェクトまたはシーンの 3D 形状を推測することを含む困難なタスクであるということです。学習ベースの手法は、3D形状を直接推定できることから注目を集めています。このレビュー ペーパーは、これまでにない新しいビューの生成など、最先端の 3D 再構成技術に焦点を当てています。入力タイプ、モデル構造、出力表現、トレーニング戦略など、ガウス スプラッシュ メソッドの最近の開発の概要が提供されます。未解決の課題と今後の方向性についても議論します。この分野の急速な進歩と 3D 再構成手法を強化する数多くの機会を考慮すると、アルゴリズムを徹底的に調査することが重要であると思われます。したがって、この研究は、ガウス散乱の最近の進歩の包括的な概要を提供します。 (親指を上にスワイプしてください
