

Libbson

Libbson is a new shared library written in C for developers wanting to work with the BSON serialization format. Its API will feel natural to C programmers but can also be used as the base of a C extension in higher-level MongoDB drivers. T
Libbson is a new shared library written in C for developers wanting to work with the BSON serialization format.
Its API will feel natural to C programmers but can also be used as the base of a C extension in higher-level MongoDB drivers.
The library contains everything you would expect from a BSON implementation. It has the ability to work with documents in their serialized form, iterating elements within a document, overwriting fields in place, Object Id generation, JSON conversion, data validation, and more. Some lessons were learned along the way that are beneficial for those choosing to implement BSON themselves.
Improving small document performance
A common use case of BSON is for relatively small documents. This has a profound impact on the memory allocator in userspace, causing what is commonly known as “memory fragmentation”. Memory fragmentation can make it more difficult for your allocator to locate a contiguous region of memory.
In addition to increasing allocation latency, it increases the memory requirements of your application to overcome that fragmentation.
To help with this issue, the bson_t structure contains 120 bytes of inline space that allows BSON documents to be built directly on the stack as opposed to the heap.
When the document size grows past 120 bytes it will automatically migrate to a heap allocation.
Additionally, bson_t will grow it’s buffers in powers of two. This is standard when working with buffers and arrays as it amortizes the overhead of growing the buffer versus calling realloc() every time data is appended. 120 bytes was chosen to align bson_t to the size of two sequential cachelines on x86_64 (each 64 bytes).
This may change based on future research, but not before a stable ABI has been reached.
Single allocation for nested documents
One strength of BSON is it’s ability to nest objects and arrays. Often times when serializing these nested documents, each sub-document is serialized independently and then appended to the parents buffer.
As you might imagine, this takes quite the toll on the allocator. It can generate many small allocations which were only created to have been immediately discarded after appending to the parents buffer. Libbson allows for building sub-documents directly into the parent documents buffer.
Doing so helps avoid this costly fragmentation. The topmost document will grow its underlying buffers in powers of two each time the allocation would overflow.
Parsing BSON documents from network buffers
Another common area for allocator fragmentation is during BSON document parsing. Libbson allows parsing and iteration of BSON documents directly from your incoming network buffer.
This means the only allocations created are those needed for your higher level language such as a PyDict if writing a Python extension.
Developers writing C extensions for their driver may choose to implement a “generator” style parsing of documents to help keep memory fragmentation low.
A technique we’re yet to explore is implementing a hashtable-esque structure backed by BSON, only deserializing the entire buffer after a threshold of keys have been accessed.
Generating BSON documents into network buffers
Much like parsing BSON documents, generating documents and placing them into your network buffers can be hard on your memory allocator. To help keep this fragmentation down, Libbson provides support for serializing your document to BSON directly within a buffer of your choosing.
This is ideal for situations such as writing a sequence of BSON documents into a MongoDB message.
Generating Object Ids without Synchronization
Applications are often doing ObjectId generation, especially in high insert environments. The uniqueness of generated ObjectIds is critical to avoiding duplicate key errors across multiple nodes.
Highly threaded environments create a local contention point slowing the rate of generation. This is because the threads must synchronize on the increment counter of each sequential ObjectId. Failure to do so could cause collisions that would not be detected until after a network round-trip. Most drivers implement the synchronization with an atomic increment or a mutex if atomics are not available.
Libbson will use atomic increments and in some cases avoid synchronization altogether if possible. One such case is a non-threaded environment.
Another is when running on Linux as both threads and processes are in the same namespace.
This allows the use of the thread identifier as the pid within the ObjectId.
You can find Libbson at https://github.com/mongodb/libbson and discuss design choices with its author, Christian Hergert, who can be found on twitter as @hergertme.
原文地址:Libbson, 感谢原作者分享。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1676
1676
 14
1429
52
1333
25
1278
29
1257
24
14
1429
52
1333
25
1278
29
1257
24

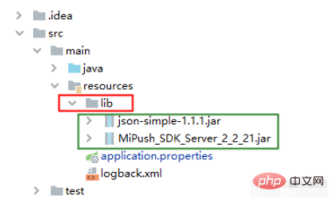 ローカルの依存関係jarパッケージをspringbootプロジェクトに導入し、libフォルダーにパッケージ化する方法
May 11, 2023 am 11:37 AM
ローカルの依存関係jarパッケージをspringbootプロジェクトに導入し、libフォルダーにパッケージ化する方法
May 11, 2023 am 11:37 AM
まえがき: 仕事中に、サードパーティのプッシュ機能を統合する必要がある SpringBoot フレームワークで構築された Javaweb プロジェクトに遭遇したため、Xiaomi プッシュ サービスを使用して、関連する jar パッケージをダウンロードしました。ローカル jar をプロジェクトに導入することは大きな問題ではなく、コードを記述した後、テスト クラスのテストに合格することは問題ありません。次に、パッケージ化して開発サーバーにデプロイする準備をします。プロジェクトは Tomcat を通じてデプロイされるため、パッケージ化方法は war パッケージになります。パッケージ化後、開発サーバーにアップロードし、起動に成功した後、書き込まれたプッシュ インターフェイスをテストしてみると、失敗していることがわかりました。分析の結果、プロジェクトの依存 jar が保存されているパッケージ化された war の lib ディレクトリには、ローカルに導入されたプッシュ関連の jar パッケージが含まれていないことが判明しました。 30分ほど格闘した結果、問題は解決した。解決する
 Linux で lib とは何を指しますか?
May 23, 2023 pm 07:20 PM
Linux で lib とは何を指しますか?
May 23, 2023 pm 07:20 PM
Linux では、lib はライブラリ ファイル ディレクトリであり、システムに役立つすべてのライブラリ ファイルが含まれています。ライブラリ ファイルは、アプリケーション、コマンド、またはプロセスを正しく実行するために必要なファイルです。 lib の役割は Windows の DLL ファイルに似ており、ほとんどすべてのアプリケーションは lib ディレクトリ内の共有ライブラリ ファイルを使用する必要があります。 libとはLibrary(ライブラリ)の略で、このディレクトリにはシステムの最も基本的なダイナミックリンク共有ライブラリが格納されており、その機能はWindowsのDLLファイルに似ています。ほとんどすべてのアプリケーションにはこれらの共有ライブラリが必要です。 /lib フォルダーはライブラリ ファイル ディレクトリであり、システムに役立つすべてのライブラリ ファイルが含まれています。簡単に言うと、アプリケーション、コマンド、またはプロセスを正しく実行するために必要なファイルです。イン/バイ
 Go言語のmakeとnewの違いは何ですか
Jan 09, 2023 am 11:44 AM
Go言語のmakeとnewの違いは何ですか
Jan 09, 2023 am 11:44 AM
相違点: 1. Make は、slice、map、および chan タイプのデータの割り当てと初期化にのみ使用できますが、new は任意のタイプのデータを割り当てることができます。 2. 新しい割り当ては型「*Type」であるポインタを返しますが、make は参照である Type を返します。 3. new によって割り当てられたスペースはクリアされ、make によってスペースが割り当てられた後、初期化されます。
 Javaで新しいキーワードを使用する方法
May 03, 2023 pm 10:16 PM
Javaで新しいキーワードを使用する方法
May 03, 2023 pm 10:16 PM
1. 概念 Java 言語では、「new」式はインスタンスを作成する役割を果たし、その中でコンストラクターが呼び出されてインスタンスを初期化します。コンストラクター自体の戻り値の型は void であり、「コンストラクターは新しく作成された値を返す」ではありません。オブジェクト参照」ですが、新しい式の値は新しく作成されたオブジェクトへの参照です。 2. 目的: 新しいクラスのオブジェクトを作成する 3. 動作メカニズム: オブジェクトのメンバーにメモリ領域を割り当て、デフォルト値を指定する メンバー変数を明示的に初期化し、構築メソッドの計算を実行し、参照値を返す 4. 新しい操作を頻繁にインスタンス化するメモリ内に新しいメモリを開くことを意味し、メモリ内のヒープ領域にメモリ空間が確保され、jvmによって制御され、メモリが自動的に管理されます。ここでは例として String クラスを使用します。プ

 新しい演算子は js でどのように機能しますか?
Feb 19, 2024 am 11:17 AM
新しい演算子は js でどのように機能しますか?
Feb 19, 2024 am 11:17 AM
js の new 演算子はどのように機能しますか? 特定のコード例が必要です。js の new 演算子は、オブジェクトの作成に使用されるキーワードです。その機能は、指定されたコンストラクターに基づいて新しいインスタンス オブジェクトを作成し、そのオブジェクトへの参照を返すことです。 new 演算子を使用する場合、実際には次の手順が実行されます: 新しい空のオブジェクトを作成する; 空のオブジェクトのプロトタイプをコンストラクターのプロトタイプ オブジェクトにポイントする; コンストラクターのスコープを新しいオブジェクトに割り当てる (したがって、これは new をポイントします) object); コンストラクターでコードを実行し、新しいオブジェクトを与えます
 新しい富士フイルムの固定レンズGFXカメラが新しい中判センサーをデビューさせ、全く新しいシリーズを開始する可能性がある
Sep 27, 2024 am 06:03 AM
新しい富士フイルムの固定レンズGFXカメラが新しい中判センサーをデビューさせ、全く新しいシリーズを開始する可能性がある
Sep 27, 2024 am 06:03 AM
富士フイルムは近年、フィルムシミュレーションとソーシャルメディアでのコンパクトレンジフィンガースタイルカメラの人気のおかげで多くの成功を収めている。しかし、Fujirumors によると、その栄誉に満足しているわけではないようだ。あなたは
 Linux がライブラリを見つけられない場合の対処方法
Feb 28, 2023 am 09:59 AM
Linux がライブラリを見つけられない場合の対処方法
Feb 28, 2023 am 09:59 AM
Linux で lib が見つからない場合の解決策: 1. プログラム内の lib ライブラリを「/lib」または「/usr/local/lib」ディレクトリにコピーし、「ldconfig」を実行します; 2. 「ld.so.conf」でライブラリファイルが配置されているディレクトリを追加し、「ld.so.cache」ファイルを更新します。
