

HDFS集中式的缓存管理原理与代码剖析

Hadoop 2.3.0已经发布了,其中最大的亮点就是集中式的缓存管理(HDFS centralized cache management)。这个功能对于提升Hadoop系统和上层应用的执行效率与实时性有很大帮助,本文从原理、架构和代码剖析三个角度来探讨这一功能。 主要解决了哪些问题 1.用户可
Hadoop 2.3.0已经发布了,其中最大的亮点就是集中式的缓存管理(HDFS centralized cache management)。这个功能对于提升Hadoop系统和上层应用的执行效率与实时性有很大帮助,本文从原理、架构和代码剖析三个角度来探讨这一功能。
主要解决了哪些问题
1.用户可以根据自己的逻辑指定一些经常被使用的数据或者高优先级任务对应的数据常驻内存而不被淘汰到磁盘。例如在Hive或Impala构建的数据仓库应用中fact表会频繁地与其他表做JOIN,显然应该让fact常驻内存,这样DataNode在内存使用紧张的时候也不会把这些数据淘汰出去,同时也实现了对于?mixed workloads的SLA。
2.centralized cache是由NameNode统一管理的,那么HDFS client(例如MapReduce、Impala)就可以根据block被cache的分布情况去调度任务,做到memory-locality。
3.HDFS原来单纯靠DataNode的OS buffer cache,这样不但没有把block被cache的分布情况对外暴露给上层应用优化任务调度,也有可能会造成cache浪费。例如一个block的三个replica分别存储在三个DataNote 上,有可能这个block同时被这三台DataNode的OS buffer cache,那么从HDFS的全局看就有同一个block在cache中存了三份,造成了资源浪费。?
4.加快HDFS client读速度。过去NameNode处理读请求时只根据拓扑远近决定去哪个DataNode读,现在还要加入speed的因素。当HDFS client和要读取的block被cache在同一台DataNode的时候,可以通过zero-copy read直接从内存读,略过磁盘I/O、checksum校验等环节。
5.即使数据被cache的DataNode节点宕机,block移动,集群重启,cache都不会受到影响。因为cache被NameNode统一管理并被被持久化到FSImage和EditLog,如果cache的某个block的DataNode宕机,NameNode会调度其他存储了这个replica的DataNode,把它cache到内存。
基本概念
cache directive: 表示要被cache到内存的文件或者目录。
cache pool: 用于管理一系列的cache directive,类似于命名空间。同时使用UNIX风格的文件读、写、执行权限管理机制。命令例子:
hdfs cacheadmin -addDirective -path /user/hive/warehouse/fact.db/city -pool financial -replication 1?
以上代码表示把HDFS上的文件city(其实是hive上的一个fact表)放到HDFS centralized cache的financial这个cache pool下,而且这个文件只需要被缓存一份。
系统架构与原理
 用户可以通过hdfs cacheadmin命令行或者HDFS API显式指定把HDFS上的某个文件或者目录放到HDFS?centralized?cache中。这个centralized?cache由分布在每个DataNode节点的off-heap内存组成,同时被NameNode统一管理。每个DataNode节点使用mmap/mlock把存储在磁盘文件中的HDFS block映射并锁定到off-heap内存中。
用户可以通过hdfs cacheadmin命令行或者HDFS API显式指定把HDFS上的某个文件或者目录放到HDFS?centralized?cache中。这个centralized?cache由分布在每个DataNode节点的off-heap内存组成,同时被NameNode统一管理。每个DataNode节点使用mmap/mlock把存储在磁盘文件中的HDFS block映射并锁定到off-heap内存中。
DFSClient读取文件时向NameNode发送getBlockLocations RPC请求。NameNode会返回一个LocatedBlock列表给DFSClient,这个LocatedBlock对象里有这个block的replica所在的DataNode和cache了这个block的DataNode。可以理解为把被cache到内存中的replica当做三副本外的一个高速的replica。
注:centralized cache和distributed cache的区别:
distributed cache将文件分发到各个DataNode结点本地磁盘保存,并且用完后并不会被立即清理的,而是由专门的一个线程根据文件大小限制和文件数目上限周期性进行清理。本质上distributed cache只做到了disk locality,而centralized cache做到了memory locality。
实现逻辑与代码剖析
HDFS centralized cache涉及到多个操作,其处理逻辑非常类似。为了简化问题,以addDirective这个操作为例说明。
1.NameNode处理逻辑
 NameNode内部主要的组件如图所示。FSNamesystem里有个CacheManager是centralized cache在NameNode端的核心组件。我们都知道BlockManager负责管理分布在各个DataNode上的block replica,而CacheManager则是负责管理分布在各个DataNode上的block cache。
NameNode内部主要的组件如图所示。FSNamesystem里有个CacheManager是centralized cache在NameNode端的核心组件。我们都知道BlockManager负责管理分布在各个DataNode上的block replica,而CacheManager则是负责管理分布在各个DataNode上的block cache。
DFSClient给NameNode发送名为addCacheDirective的RPC, 在ClientNamenodeProtocol.proto这个文件中定义相应的接口。
NameNode接收到这个RPC之后处理,首先把这个需要被缓存的Path包装成CacheDirective加入CacheManager所管理的directivesByPath中。这时对应的File/Directory并没有被cache到内存。
一旦CacheManager那边添加了新的CacheDirective,触发CacheReplicationMonitor.rescan()来扫描并把需要通知DataNode做cache的block加入到CacheReplicationMonitor. cachedBlocks映射中。这个rescan操作在NameNode启动时也会触发,同时在NameNode运行期间以固定的时间间隔触发。
Rescan()函数主要逻辑如下:
rescanCacheDirectives()->rescanFile():依次遍历每个等待被cache的directive(存储在CacheManager. directivesByPath里),把每个等待被cache的directive包含的block都加入到CacheReplicationMonitor.cachedBlocks集合里面。
rescanCachedBlockMap():调用CacheReplicationMonitor.addNewPendingCached()为每个等待被cache的block选择一个合适的DataNode去cache(一般是选择这个block的三个replica所在的DataNode其中的剩余可用内存最多的一个),加入对应的DatanodeDescriptor的pendingCached列表。
2.NameNode与DataNode的RPC逻辑
DataNode定期向NameNode发送heartbeat RPC用于表明它还活着,同时DataNode还会向NameNode定期发送block report(默认6小时)和cache block(默认10秒)用于同步block和cache的状态。
NameNode会在每次处理某一DataNode的heartbeat RPC时顺便检查该DataNode的pendingCached列表是否为空,不为空的话发送DatanodeProtocol.DNA_CACHE命令给具体的DataNode去cache对应的block replica。
3.DataNode处理逻辑
 DataNode内部主要的组件如图所示。DataNode启动的时候只是检查了一下dfs.datanode.max.locked.memory是否超过了OS的限制,并没有把留给Cache使用的内存空间锁定。
DataNode内部主要的组件如图所示。DataNode启动的时候只是检查了一下dfs.datanode.max.locked.memory是否超过了OS的限制,并没有把留给Cache使用的内存空间锁定。
在DataNode节点上每个BlockPool对应有一个BPServiceActor线程向NameNode发送heartbeat、接收response并处理。如果接收到来自NameNode的RPC里面的命令是DatanodeProtocol.DNA_CACHE,那么调用FsDatasetImpl.cacheBlock()把对应的block cache到内存。
这个函数先是通过RPC传过来的blockId找到其对应的FsVolumeImpl (因为执行cache block操作的线程cacheExecutor是绑定在对应的FsVolumeImpl里的);然后调用FsDatasetCache.cacheBlock()把这个block封装成MappableBlock加入到mappableBlockMap里统一管理起来,然后向对应的FsVolumeImpl.cacheExecutor线程池提交一个CachingTask异步任务(cache的过程是异步执行的)。
FsDatasetCache有个成员mappableBlockMap(HashMap)管理着这台DataNode的所有的MappableBlock及其状态(caching/cached/uncaching)。目前DataNode中”哪些block被cache到内存里了”也是只保存了soft state(和NameNode的block map一样),是DataNode向NameNode 发送heartbeat之后从NameNode那问回来的,没有持久化到DataNode本地硬盘。
CachingTask的逻辑: 调用MappableBlock.load()方法把对应的block从DataNode本地磁盘通过mmap映射到内存中,然后通过mlock锁定这块内存空间,并对这个映射到内存的block做checksum检验其完整性。这样对于memory-locality的DFSClient就可以通过zero-copy直接读内存中的block而不需要校验了。
4.DFSClient读逻辑:
HDFS的读主要有三种: 网络I/O读 -> short circuit read -> zero-copy read。网络I/O读就是传统的HDFS读,通过DFSClient和Block所在的DataNode建立网络连接传输数据。?
当DFSClient和它要读取的block在同一台DataNode时,DFSClient可以跨过网络I/O直接从本地磁盘读取数据,这种读取数据的方式叫short circuit read。目前HDFS实现的short circuit read是通过共享内存获取要读的block在DataNode磁盘上文件的file descriptor(因为这样比传递文件目录更安全),然后直接用对应的file descriptor建立起本地磁盘输入流,所以目前的short circuit read也是一种zero-copy read。
增加了Centralized cache的HDFS的读接口并没有改变。DFSClient通过RPC获取LocatedBlock时里面多了个成员表示哪个DataNode把这个block cache到内存里面了。如果DFSClient和该block被cache的DataNode在一起,就可以通过zero-copy read大大提升读效率。而且即使在读取的过程中该block被uncache了,那么这个读就被退化成了本地磁盘读,一样能够获取数据。?
对上层应用的影响
对于HDFS上的某个目录已经被addDirective缓存起来之后,如果这个目录里新加入了文件,那么新加入的文件也会被自动缓存。这一点对于Hive/Impala式的应用非常有用。
HBase in-memory table:可以直接把某个HBase表的HFile放到centralized cache中,这会显著提高HBase的读性能,降低读请求延迟。
和Spark RDD的区别:多个RDD的之间的读写操作可能完全在内存中完成,出错就重算。HDFS centralized cache中被cache的block一定是先写到磁盘上的,然后才能显式被cache到内存。也就是说只能cache读,不能cache写。
目前的centralized cache不是DFSClient读了谁就会把谁cache,而是需要DFSClient显式指定要cache谁,cache多长时间,淘汰谁。目前也没有类似LRU的置换策略,如果内存不够用的时候需要client显式去淘汰对应的directive到磁盘。
现在还没有跟YARN整合,需要用户自己调整好留给DataNode用于cache的内存和NodeManager的内存使用。
参考文献
http://hadoop.apache.org/docs/r2.3.0/hadoop-project-dist/hadoop-hdfs/CentralizedCacheManagement.html
https://issues.apache.org/jira/browse/HDFS-4949
原文地址:HDFS集中式的缓存管理原理与代码剖析, 感谢原作者分享。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7328
7328
 9
1626
14
1350
46
1262
25
1209
29
9
1626
14
1350
46
1262
25
1209
29

 Linux で DNS キャッシュを表示および更新する方法
Mar 07, 2024 am 08:43 AM
Linux で DNS キャッシュを表示および更新する方法
Mar 07, 2024 am 08:43 AM
DNS (DomainNameSystem) は、ドメイン名を対応する IP アドレスに変換するためにインターネットで使用されるシステムです。 Linux システムでは、DNS キャッシュはドメイン名と IP アドレス間のマッピング関係をローカルに保存するメカニズムです。これにより、ドメイン名解決の速度が向上し、DNS サーバーの負担が軽減されます。 DNS キャッシュを使用すると、システムはその後同じドメイン名にアクセスするときに、毎回 DNS サーバーにクエリ要求を発行する必要がなく、IP アドレスを迅速に取得できるため、ネットワークのパフォーマンスと効率が向上します。この記事では、Linux で DNS キャッシュを表示および更新する方法、関連する詳細およびサンプル コードについて説明します。 DNS キャッシュの重要性 Linux システムでは、DNS キャッシュが重要な役割を果たします。その存在
 nohupの機能と原理の解析
Mar 25, 2024 pm 03:24 PM
nohupの機能と原理の解析
Mar 25, 2024 pm 03:24 PM
nohup の役割と原理の分析 Unix および Unix 系オペレーティング システムでは、nohup はバックグラウンドでコマンドを実行するためによく使用されるコマンドです。ユーザーが現在のセッションを終了したり、ターミナル ウィンドウを閉じたりしても、コマンドはまだ実行され続けています。この記事では、nohup コマンドの機能と原理を詳しく分析します。 1. nohup の役割: バックグラウンドでのコマンドの実行: nohup コマンドを使用すると、ターミナル セッションを終了するユーザーの影響を受けることなく、長時間実行されるコマンドをバックグラウンドで実行し続けることができます。これは実行する必要があります
 PHP 開発におけるキャッシュ メカニズムとアプリケーションの実践
May 09, 2024 pm 01:30 PM
PHP 開発におけるキャッシュ メカニズムとアプリケーションの実践
May 09, 2024 pm 01:30 PM
PHP 開発では、キャッシュ メカニズムにより、頻繁にアクセスされるデータがメモリまたはディスクに一時的に保存され、データベース アクセスの数が削減され、パフォーマンスが向上します。キャッシュの種類には主にメモリ、ファイル、データベース キャッシュが含まれます。キャッシュは、組み込み関数またはサードパーティのライブラリ (cache_get() や Memcache など) を使用して PHP に実装できます。一般的な実用的なアプリケーションには、データベース クエリ結果をキャッシュしてクエリ パフォーマンスを最適化したり、ページ出力をキャッシュしてレンダリングを高速化したりすることが含まれます。キャッシュ メカニズムにより、Web サイトの応答速度が効果的に向上し、ユーザー エクスペリエンスが向上し、サーバーの負荷が軽減されます。
 Linux の「.a」ファイルを作成して実行する
Mar 20, 2024 pm 04:46 PM
Linux の「.a」ファイルを作成して実行する
Mar 20, 2024 pm 04:46 PM
Linux オペレーティング システムでファイルを操作するには、開発者がファイル、コード、プログラム、スクリプトなどを効率的に作成および実行できるようにするさまざまなコマンドとテクニックを使用する必要があります。 Linux 環境では、拡張子「.a」を持つファイルは静的ライブラリとして非常に重要です。これらのライブラリはソフトウェア開発において重要な役割を果たし、開発者が複数のプログラム間で共通の機能を効率的に管理および共有できるようにします。 Linux 環境で効果的なソフトウェア開発を行うには、「.a」ファイルの作成方法と実行方法を理解することが重要です。この記事では、Linux の「.a」ファイルのインストールと構成方法を包括的に紹介します。Linux の「.a」ファイルの定義、目的、構造、作成および実行方法について見てみましょう。 Lとは何ですか
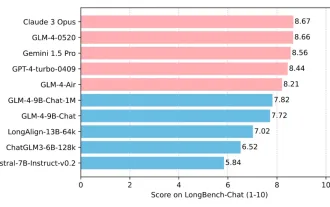 清華大学と Zhipu AI オープンソース GLM-4: 自然言語処理に新たな革命を起こす
Jun 12, 2024 pm 08:38 PM
清華大学と Zhipu AI オープンソース GLM-4: 自然言語処理に新たな革命を起こす
Jun 12, 2024 pm 08:38 PM
2023 年 3 月 14 日に ChatGLM-6B が発売されて以来、GLM シリーズ モデルは幅広い注目と認知を得てきました。特にChatGLM3-6Bがオープンソース化されてからは、Zhipu AIが投入する第4世代モデルに対する開発者の期待が高まっている。 GLM-4-9B のリリースにより、この期待はついに完全に満たされました。 GLM-4-9B の誕生 小型モデル (10B 以下) により強力な機能を提供するために、GLM 技術チームはこの新しい第 4 世代 GLM シリーズ オープン ソース モデル、GLM-4-9B をほぼ半年の期間を経て発売しました。探検。このモデルは、精度を確保しながらモデルサイズを大幅に圧縮し、推論速度の高速化と効率化を実現しています。 GLM 技術チームの調査はまだ終わっていない
 CPU、メモリ、キャッシュの関係を詳しく解説!
Mar 07, 2024 am 08:30 AM
CPU、メモリ、キャッシュの関係を詳しく解説!
Mar 07, 2024 am 08:30 AM
CPU (中央処理装置)、メモリ (ランダム アクセス メモリ)、およびキャッシュの間には密接な相互作用があり、これらは共にコンピュータ システムの重要なコンポーネントを形成します。それらの間の調整により、コンピュータの通常の動作と効率的なパフォーマンスが保証されます。 CPU はコンピュータの頭脳として、さまざまな命令やデータ処理の実行を担当します。メモリはデータやプログラムを一時的に保存するために使用され、高速な読み取りおよび書き込みアクセス速度を提供します。キャッシュはバッファリングの役割を果たし、データ アクセスを高速化します。速度と向上 コンピュータの CPU はコンピュータの中核コンポーネントであり、さまざまな命令、算術演算、論理演算の実行を担当します。コンピューターの「頭脳」と呼ばれ、データの処理やタスクの実行に重要な役割を果たします。メモリはコンピュータの重要な記憶装置です。
 エージェントを一文で作成!ロビン・リー: 誰もが開発者になる時代が来る
Apr 17, 2024 pm 02:28 PM
エージェントを一文で作成!ロビン・リー: 誰もが開発者になる時代が来る
Apr 17, 2024 pm 02:28 PM
すべてを覆す大きなモデルが、ついに編集者の頭にたどり着いた。たった一文でできたエージェントでもあります。このように、彼に記事を与えると、1 秒以内に新鮮なタイトルの候補が出てきます。私と比較すると、この効率は稲妻のように速く、ナマケモノのように遅いとしか言いようがありません... さらに驚くべきことに、このエージェントの作成には実際には数分しかかからないということです。プロンプトは江おばさんのものです。そして、この破壊的な感覚も体験したい場合は、百度が立ち上げた新しいウェンシン インテリジェント エージェント プラットフォームに基づいて、誰でも無料で独自のインテリジェント アシスタントを作成できます。検索エンジン、スマート ハードウェア プラットフォーム、音声認識、地図、自動車、その他の Baidu モバイル エコロジー チャネルを使用して、より多くの人があなたの創造性を活用できるようにすることができます。ロビン・リー自身
 Mistral オープン ソース コード モデルが王位を獲得します。 Codestral は 80 を超える言語でのトレーニングに熱心に取り組んでおり、国内の Tongyi 開発者が参加を求めています。
Jun 08, 2024 pm 09:55 PM
Mistral オープン ソース コード モデルが王位を獲得します。 Codestral は 80 を超える言語でのトレーニングに熱心に取り組んでおり、国内の Tongyi 開発者が参加を求めています。
Jun 08, 2024 pm 09:55 PM
51CTO Technology Stack (WeChat ID: blog51cto) が制作、Mistral は最初のコードモデル Codestral-22B をリリースしました!このモデルのすごいところは、多くのコード モデルが無視する Swift などを含む 80 以上のプログラミング言語でトレーニングされていることだけではありません。それらの速度はまったく同じではありません。 Go言語を使用して「パブリッシュ/サブスクライブ」システムを記述する必要があります。ここでは GPT-4o が出力されており、Codestral は、見るのが難しいほど高速で論文を提出しています。発売されたばかりのモデルのため、まだ公的テストは行われていない。しかし、Mistral の担当者によると、Codestral は現在最もパフォーマンスの高いオープンソース コード モデルであるとのことです。写真に興味のある友達は次の場所に移動できます: - 顔を抱きしめる: https
