

A proposal for more reliable locks using Redis

----------------- UPDATE: The algorithm is now described in the Redis documentation here => http://redis.io/topics/distlock. The article is left here in its older version, the updates will go into the Redis documentation instead. ---------
-----------------UPDATE: The algorithm is now described in the Redis documentation here => http://redis.io/topics/distlock. The article is left here in its older version, the updates will go into the Redis documentation instead.
-----------------
Many people use Redis to implement distributed locks. Many believe that this is a great use case, and that Redis worked great to solve an otherwise hard to solve problem. Others believe that this is totally broken, unsafe, and wrong use case for Redis.
Both are right, basically. Distributed locks are not trivial if we want them to be safe, and at the same time we demand high availability, so that Redis nodes can go down and still clients are able to acquire and release locks. At the same time a fast lock manager can solve tons of problems which are otherwise hard to solve in practice, and sometimes even a far from perfect solution is better than a very slow solution.
Can we have a fast and reliable system at the same time based on Redis? This blog post is an exploration in this area. I’ll try to describe a proposal for a simple algorithm to use N Redis instances for distributed and reliable locks, in the hope that the community may help me analyze and comment the algorithm to see if this is a valid candidate.
# What we really want?
Talking about a distributed system without stating the safety and liveness properties we want is mostly useless, because only when those two requirements are specified it is possible to check if a design is correct, and for people to analyze and find bugs in the design. We are going to model our design with just three properties, that are what I believe the minimum guarantees you need to use distributed locks in an effective way.
1) Safety property: Mutual exclusion. At any given moment, only one client can hold a lock.
2) Liveness property A: Deadlocks free. Eventually it is always possible to acquire a lock, even if the client that locked a resource crashed or gets partitioned.
3) Liveness property B: Fault tolerance. As long as the majority of Redis nodes are up, clients are able to acquire and release locks.
# Distributed locks, the naive way.
To understand what we want to improve, let’s analyze the current state of affairs.
The simple way to use Redis to lock a resource is to create a key into an instance. The key is usually created with a limited time to live, using Redis expires feature, so that eventually it gets released one way or the other (property 2 in our list). When the client needs to release the resource, it deletes the key.
Superficially this works well, but there is a problem: this is a single point of failure in our architecture. What happens if the Redis master goes down?
Well, let’s add a slave! And use it if the master is unavailable. This is unfortunately not viable. By doing so we can’t implement our safety property of the mutual exclusion, because Redis replication is asynchronous.
This is an obvious race condition with this model:
1) Client A acquires the lock into the master.
2) The master crashes before the write to the key is transmitted to the slave.
3) The slave gets promoted to master.
4) Client B acquires the lock to the same resource A already holds a lock for.
Sometimes it is perfectly fine that under special circumstances, like during a failure, multiple clients can hold the lock at the same time.
If this is the case, stop reading and enjoy your replication based solution. Otherwise keep reading for a hopefully safer way to implement it.
# First, let’s do it correctly with one instance.
Before to try to overcome the limitation of the single instance setup described above, let’s check how to do it correctly in this simple case, since this is actually a viable solution in applications where a race condition from time to time is acceptable, and because locking into a single instance is the foundation we’ll use for the distributed algorithm described here.
To acquire the lock, the way to go is the following:
SET resource_name my_random_value NX PX 30000
The command will set the key only if it does not already exist (NX option), with an expire of 30000 milliseconds (PX option).
The key is set to a value “my_random_value”. This value requires to be unique across all the clients and all the locks requests.
Basically the random value is used in order to release the lock in a safe way, with a script that tells Redis: remove the key only if exists and the value stored at the key is exactly the one I expect to be. This is accomplished by the following Lua script:
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
This is important in order to avoid removing a lock that was created by another client. For example a client may acquire the lock, get blocked into some operation for longer than the lock validity time (the time at which the key will expire), and later remove the lock, that was already acquired by some other client.
Using just DEL is not safe as a client may remove the lock of another client. With the above script instead every lock is “signed” with a random string, so the lock will be removed only if it is still the one that was set by the client trying to remove it.
What this random string should be? I assume it’s 20 bytes from /dev/urandom, but you can find cheaper ways to make it unique enough for your tasks.
For example a safe pick is to seed RC4 with /dev/urandom, and generate a pseudo random stream from that.
A simpler solution is to use a combination of unix time with microseconds resolution, concatenating it with a client ID, it is not as safe, but probably up to the task in most environments.
The time we use as the key time to live, is called the “lock validity time”. It is both the auto release time, and the time the client has in order to perform the operation required before another client may be able to acquire the lock again, without technically violating the mutual exclusion guarantee, which is only limited to a given window of time from the moment the lock is acquired.
So now we have a good way to acquire and release the lock. The system, reasoning about a non-distrubited system which is composed of a single instance, always available, is safe. Let’s extend the concept to a distributed system where we don’t have such guarantees.
# Distributed version
In the distributed version of the algorithm we assume to have N Redis masters. Those nodes are totally independent, so we don’t use replication or any other implicit coordination system. We already described how to acquire and release the lock safely in a single instance. We give for granted that the algorithm will use this method to acquire and release the lock in a single instance. In our examples we set N=5, which is a reasonable value, so we need to run 5 Redis masters in different computers or virtual machines in order to ensure that they’ll fail in a mostly independent way.
In order to acquire the lock, the client performs the following operations:
Step 1) It gets the current time in milliseconds.
Step 2) It tries to acquire the lock in all the N instances sequentially, using the same key name and random value in all the instances.
During the step 2, when setting the lock in each instance, the client uses a timeout which is small compared to the total lock auto-release time in order to acquire it.
For example if the auto-release time is 10 seconds, the timeout could be in the ~ 5-50 milliseconds range.
This prevents the client to remain blocked for a long time trying to talk with a Redis node which is down: if an instance is not available, we should try to talk with the next instance ASAP.
Step 3) The client computes how much time elapsed in order to acquire the lock, by subtracting to the current time the timestamp obtained in step 1.
If and only if the client was able to acquire the lock in the majority of the instances (at least 3), and the total time elapsed to acquire the lock is less than lock validity time, the lock is considered to be acquired.
Step 4) If the lock was acquired, its validity time is considered to be the initial validity time minus the time elapsed, as computed in step 3.
Step 5) If the client failed to acquire the lock for some reason (either it was not able to lock N/2+1 instances or the validity time is negative), it will try to unlock all the instances (even the instances it believe it was not able to lock).
# Synchronous or not?
Basically the algorithm is partially synchronous: it relies on the assumption that while there is no synchronized clock across the processes, still the local time in every process flows approximately at the same rate, with an error which is small compared to the auto-release time of the lock. This assumption closely resembles a real-world computer: every computer has a local clock and we can usually rely on different computers to have a clock drift which is small.
Moreover we need to refine our mutual exclusion rule: it is guaranteed only as long as the client holding the lock will terminate its work within the lock validity time (as obtained in step 3), minus some time (just a few milliseconds in order to compensate for clock drift between processes).
# Retry
When a client is not able to acquire the lock, it should try again after a random delay in order to try to desynchronize multiple clients trying to acquire the lock, for the same resource, at the same time (this may result in a split brain condition where nobody wins). Also the faster a client will try to acquire the lock in the majority of Redis instances, the less window for a split brain condition (and the need for a retry), so ideally the client should try to send the SET commands to the N instances at the same time using multiplexing.
It is worth to stress how important is for the clients that failed to acquire the majority of locks, to release the (partially) acquired locks ASAP, so that there is no need to wait for keys expiry in order for the lock to be acquired again (however if a network partition happens and the client is no longer able to communicate with the Redis instances, there is to pay an availability penalty and wait for the expires).
# Releasing the lock
Releasing the lock is simple and involves just to release the lock in all the instances, regardless of the fact the client believe it was able to successfully lock a given instance.
# Safety arguments
Is this system safe? We can try to understand what happens in different scenarios.
To start let’s assume that a client is able to acquire the lock in the majority of instances. All the instances will contain a key with the same time to live. However the key was set at different times, so the keys will also expire at different times. However if the first key was set at worst at time T1 (the time we sample before contacting the first server) and the last key was set at worst at time T2 (the time we obtained the reply from the last server), we are sure that the first key to expire in the set will exist for at least MIN_VALIDITY=TTL-(T2-T1)-CLOCK_DRIFT. All the other keys will expire later, so we are sure that the keys will be simultaneously set for at least this time.
During the time the majority of keys are set, another client will not be able to acquire the lock, since N/2+1 SET NX operations can’t succeed if N/2+1 keys already exist. So if a lock was acquired, it is not possible to re-acquire it at the same time (violating the mutual exclusion property).
However we want to also make sure that multiple clients trying to acquire the lock at the same time can’t simultaneously succeed.
If a client locked the majority of instances using a time near, or greater, than the lock maximum validity time (the TTL we use for SET basically), it will consider the lock invalid and will unlock the instances, so we only need to consider the case where a client was able to lock the majority of instances in a time which is less than the validity time. In this case for the argument already expressed above, for MIN_VALIDITY no client should be able to re-acquire the lock. So multiple clients will be albe to lock N/2+1 instances at the same time (with “time" being the end of Step 2) only when the time to lock the majority was greater than the TTL time, making the lock invalid.
Are you able to provide a formal proof of safety, or to find a bug? That would be very appreciated.
# Liveness arguments
The system liveness is based on three main features:
1) The auto release of the lock (since keys expire): eventually keys are available again to be locked.
2) The fact that clients, usually, will cooperate removing the locks when the lock was not acquired, or when the lock was acquired and the work terminated, making it likely that we don’t have to wait for keys to expire to re-acquire the lock.
3) The fact that when a client needs to retry a lock, it waits a time which is comparable greater to the time needed to acquire the majority of locks, in order to probabilistically make split brain conditions during resource contention unlikely.
However there is at least a scenario where a very special network partition/rejoin pattern, repeated indefinitely, may violate the system availability.
For example with N=5, two clients A and B may try to lock the same resource at the same time, nobody will be able to acquire the majority of locks, but they may be able to lock the majority of nodes if we sum the locks of A and B (for example client A locked 2 instances, client B just one instance).
Then the clients are partitioned away before they can unlock the locked instances. This will leave the resource not lockable for a time roughly equal to the auto release time. Then when the keys expire, the two clients A and B join again the partition repeating the same pattern, and so forth indefinitely.
Another point of view to see the problem above, is that we pay an availability penalty equal to “TTL” time on network partitions, so if there are continuous partitions, we can pay this penalty indefinitely.
I can’t find a simple way to have guaranteed liveness (but did not tried very hard honestly), but the worst case appears to be hard to trigger.
Basically it means that we can only provide, using this algorithm, an approximation of Property number 2.
# Performance, crash-recovery and fsync
Many users using Redis as a lock server need high performance in terms of both latency to acquire and release a lock, and number of acquire / release operations that it is possible to perform per second. In order to meet this requirement, the strategy to talk with the N Redis servers to reduce latency is definitely multiplexing (or poor’s man multiplexing, which is, putting the socket in non-blocking mode, send all the commands, and read all the commands later, assuming that the RTT between the client and each instance is similar).
However there is another consideration to do about persistence if we want to target a crash-recovery system model.
Basically to see the problem here, let’s assume we configure Redis without persistence at all. A client acquires the lock in 3 of 5 instances. One of the instances where the client was able to acquire the lock is restarted, at this point there are again 3 instances that we can lock for the same resource, and another client can lock it again, violating the safety property of exclusivity of lock.
If we enable AOF persistence, things will improve quite a bit. For example we can upgrade a server by sending SHUTDOWN and restarting it. Because Redis expires are semantically implemented so that virtually the time still elapses when the server is off, all our requirements are fine.
However everything is fine as long as it is a clean shutdown. What about a power outage? If Redis is configured, as by default, to fsync on disk every second, it is possible that after a restart our key is missing. Long story short if we want to guarantee the lock safety in the face of any kind of instance restart, we need to enable fsync=always in the persistence setting. This in turn will totally ruin performances to the same level of CP systems that are traditionally used to implement distributed locks in a safe way.
The good news is that because in our algorithm we don’t stop to acquire locks as soon as we reach the majority of the servers, the actual probability of safety violation is small, because most of the times the lock will be hold in all the 5 servers, so even if one restarts without a key, it is practically unlikely (but not impossible) that an actual safety violation happens. Long story short, this is an user pick, and a big trade off. Given the small probability for a race condition, if it is acceptable that with an extremely small probability, after a crash-recovery event, the lock may be acquired at the same time by multiple clients, the fsync at every operation can (and should) be avoided.
# Reference implementation
I wrote a simple reference implementation in Ruby, backed by redis-rb, here: http://github.com/antirez/redlock-rb
# Want to help?
If you are into distributed systems, it would be great to have your opinion / analysis.
Also reference implementations in other languages could be great.
Thanks in advance!
EDIT: I received feedbacks in this blog post comment and via Hacker News that's worth to incorporate in this blog post.
1) As Steven Benjamin notes in the comments below, if after restarting an instance we can make it unavailable for enough time for all the locks that used this instance to expire, we don't need fsync. Actually we don't need any persistence at all, so our safety guarantee can be provided with a pure in-memory configuration.
An example: previously we described the example race condition where a lock is obtained in 3 servers out of 5, and one of the servers where the lock was obtained restarts empty: another client may acquire the same lock by locking this server and the other two that were not locked by the previous client. However if the restarted server is not available for queries enough time for all the locks that were obtained with it to expire, we are guaranteed this race is no longer possible.
2) The Hacker News user eurleif noticed how it is possible to reacquire the lock as a strategy if the client notices it is taking too much time in order to complete the operation. This can be done by just extending an existing lock, sending a script that extends the expire of the value stored at the key is the expected one. If there are no new partitions, and we try to extend the lock enough in advance so that the keys will not expire, there is the guarantee that the lock will be extended.
3) The Hacker News user mjb noted how the term "skew" is not correct to describe the difference of the rate at which different clocks increment their local time, and I'm actually talking about "Drift". I'm replacing the word "skew" with "drift" to use the correct term.
Thanks for the very useful feedbacks. Comments

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7706
7706
 15
1640
14
1394
52
1288
25
1231
29
15
1640
14
1394
52
1288
25
1231
29

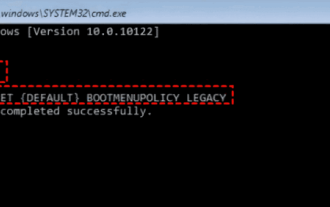 kernel_security_check_failure ブルー スクリーンを解決する 17 の方法
Feb 12, 2024 pm 08:51 PM
kernel_security_check_failure ブルー スクリーンを解決する 17 の方法
Feb 12, 2024 pm 08:51 PM
Kernelsecuritycheckfailure (カーネルチェック失敗) は比較的一般的な停止コードですが、理由が何であれ、ブルースクリーンエラーは多くのユーザーを悩ませます、当サイトでは 17 種類のエラーをユーザーに丁寧に紹介します。 kernel_security_check_failure ブルー スクリーンに対する 17 の解決策 方法 1: すべての外部デバイスを削除する 使用している外部デバイスが Windows のバージョンと互換性がない場合、Kernelsecuritycheckfailure ブルー スクリーン エラーが発生することがあります。これを行うには、コンピュータを再起動する前に、すべての外部デバイスを取り外しておく必要があります。
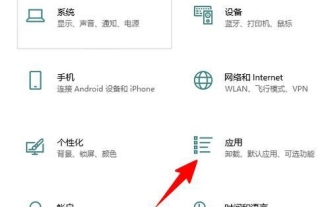 Win10 で Skype for Business をアンインストールするにはどうすればよいですか?コンピューターから Skype を完全にアンインストールする方法
Feb 13, 2024 pm 12:30 PM
Win10 で Skype for Business をアンインストールするにはどうすればよいですか?コンピューターから Skype を完全にアンインストールする方法
Feb 13, 2024 pm 12:30 PM
Win10 Skype はアンインストールできますか? 多くのユーザーは、このアプリケーションがコンピューターの既定のプログラムに含まれており、削除するとシステムの動作に影響するのではないかと心配しているため、これは多くのユーザーが知りたい質問です。この Web サイトはユーザーを支援します。Win10 で Skype for Business をアンインストールする方法を詳しく見てみましょう。 Win10 で Skype for Business をアンインストールする方法 1. コンピューターのデスクトップで Windows アイコンをクリックし、設定アイコンをクリックしてに入ります。 2. 「適用」をクリックします。 3. 検索ボックスに「Skype」と入力し、見つかった結果をクリックして選択します。 4. 「アンインストール」をクリックします。 5
 JavaScript で for を使用して n の階乗を求める方法
Dec 08, 2021 pm 06:04 PM
JavaScript で for を使用して n の階乗を求める方法
Dec 08, 2021 pm 06:04 PM
for を使用して n 階乗を求める方法: 1. 「for (var i=1;i<=n;i++){}」ステートメントを使用して、ループの走査範囲を「1~n」に制御します; 2. ループ内body, use "cj *=i" 1からnまでの数値を掛けて変数cjに代入; 3. ループ終了後、変数cjの値をnの階乗にして出力します。
 foreach と for ループの違いは何ですか
Jan 05, 2023 pm 04:26 PM
foreach と for ループの違いは何ですか
Jan 05, 2023 pm 04:26 PM
違い: 1. for はインデックスを介して各データ要素をループしますが、forEach は JS の基礎となるプログラムを介して配列のデータ要素をループします; 2. for はbreak キーワードを使用してループの実行を終了できますが、forEach はそれができません; 3 . forはループ変数の値を制御することでループの実行を制御できるが、forEachはできない; 4. forはループ外でループ変数を呼び出すことができるが、forEachはループ外でループ変数を呼び出すことができない; 5. forの実行効率forEach よりも高いです。
 JAVAの単純なforループで例外を回避するにはどうすればよいですか?
Apr 26, 2023 pm 12:58 PM
JAVAの単純なforループで例外を回避するにはどうすればよいですか?
Apr 26, 2023 pm 12:58 PM
はじめに 実際のビジネスプロジェクト開発において、与えられたリストから条件を満たさない要素を削除するという操作は誰でも経験があるのではないでしょうか?多くの学生はそれを達成するためのさまざまな方法をすぐに思いつくことができますが、あなたが考えるすべての方法は人体や動物に無害ですか?一見普通に見える操作の多くは実は罠であり、多くの初心者は注意しないと罠に陥る可能性があります。残念ながら、コードの実行中に例外がスローされ、エラーが報告された場合は幸いですが、少なくともエラーは報告されずにコードが発見され、時間内に解決されますが、ビジネス ロジックでは不可解なさまざまな奇妙な問題が発生します。この問題に注意を払わないと、その後のビジネスに隠れた危険が生じる可能性があるため、これはさらに悲劇的です。では、実装方法にはどのようなものがあるのでしょうか?どのような実装が考えられるか
 Python の一般的なフロー制御構造は何ですか?
Jan 20, 2024 am 08:17 AM
Python の一般的なフロー制御構造は何ですか?
Jan 20, 2024 am 08:17 AM
Python の一般的なフロー制御構造は何ですか? Python では、フロー制御構造はプログラムの実行順序を決定するために使用される重要なツールです。これらを使用すると、さまざまな条件に基づいてさまざまなコード ブロックを実行したり、コード ブロックを繰り返し実行したりできます。以下では、Python の一般的なプロセス制御構造を紹介し、対応するコード例を示します。条件ステートメント (if-else): 条件ステートメントを使用すると、さまざまな条件に基づいてさまざまなコード ブロックを実行できます。基本的な構文は次のとおりです: if 条件 1: #when 条件
 6 つの例、8 つのコード スニペット、Python の For ループの詳細な説明
Apr 11, 2023 pm 07:43 PM
6 つの例、8 つのコード スニペット、Python の For ループの詳細な説明
Apr 11, 2023 pm 07:43 PM
Python は for ループをサポートしており、その構文は他の言語 (JavaScript や Java など) とは若干異なります。次のコード ブロックは、Python で for ループを使用してリスト内の要素を反復処理する方法を示しています。 上記のコード スニペットは、3 つの文字を別々の行に出力します。 print文の後にカンマ「,」を追加することで出力を同じ行に制限することができます(印刷する文字数を多く指定すると「折り返されます」)。コードは次のとおりです。複数行ではなく 1 行でテキスト コンテンツの場合は、上記の形式のコードを使用できます。 Python には組み込み機能も用意されています
 Go 言語の for ループを使用して、flip 関数をすばやく実装します。
Mar 25, 2024 am 10:45 AM
Go 言語の for ループを使用して、flip 関数をすばやく実装します。
Mar 25, 2024 am 10:45 AM
Go 言語を使用した反転関数の実装は、for ループを通じて非常に迅速に実装できます。フリップ関数は、文字列または配列内の要素の順序を反転するもので、文字列の反転、配列要素の反転など、多くのシナリオに適用できます。 Go言語のforループを使って文字列や配列の反転機能を実現する方法を、具体的なコード例を添えて見てみましょう。文字列の反転: packagemainimport("fmt")fun
