

《Redis设计与实现》读书笔记

《Redis设计与实现》读书笔记 很喜欢这本书的创作过程,以开源的方式,托管到Git上进行创作; 作者通读了Redis源码,并分享了详细的带注释的源码,让学习Redis的朋友轻松不少; 阅读优秀的源码作品能快速的提升编码内功,而像Redis这样代码量不大(2万多行)
《Redis设计与实现》读书笔记
很喜欢这本书的创作过程,以开源的方式,托管到Git上进行创作;
作者通读了Redis源码,并分享了详细的带注释的源码,让学习Redis的朋友轻松不少;
阅读优秀的源码作品能快速的提升编码内功,而像Redis这样代码量不大(2万多行)却句句精致的作品,当然不能错过;
有兴趣的朋友当好好享用;
源码:https://github.com/huangz1990/annotated_redis_source
以下是这本书重点环节的读书笔记;
Redis的内部字符串实现
Redis 使用自行实现的sds 类型来表示字符串:
原因:可以高效地实现追加和长度计算,并且它还是二进制安全的。
在 Redis 内部,字符串的追加和长度计算并不少见,而 APPEND 和 STRLEN 更是这两种操作在 Redis 命令中的直接映射,这两个简单的操作不应该成为性能的瓶颈。另外,Redis 除了处理 C 字符串之外,还需要处理单纯的字节数组,以及服务器协议等内容,所以为了方便起见,Redis 的字符串表示还应该是二进制安全的:
程序不应对字符串里面保存的数据做任何假设,数据可以是以 \0 结尾的 C 字符串,也可以是单纯的字节数组,或者其他格式的数据。
关于sds的详情介绍,参见:
http://origin.redisbook.com/en/latest/internal-datastruct/sds.html#sds
内部映射数据结构和内存数据结构的区别
内存映射数据结构:整数集合、压缩链表
内部数据结构:简单字符串(sds)、双端链表、字典、跳跃表
内部数据结构非常强大,但是创建一系列完整的数据结构本身也是一件相当耗费内存的工作,当一个对象包含的元素数量并不多,或者元素本身的体积并不大时,使用代价高昂的内部数据结构并不是最好的办法。为了解决这一问题,Redis 在条件允许的情况下,会使用内存映射数据结构来代替内部数据结构。内存映射数据结构是一系列经过特殊编码的字节序列,创建它们所消耗的内存通常比作用类似的内部数据结构要少得多,如果使用得当,内存映射数据结构可以为用户节省大量的内存。不过,因为内存映射数据结构的编码和操作方式要比内部数据结构要复杂得多,所以内存映射数据结构所占用的 CPU 时间会比作用类似的内部数据结构要多。
集合求并与求交集
集合好用,redis集合支持求交集,求并集操作,让集合的应用范围大幅提升;
但是,需要注意到,求并集的算法复杂度是O(N),而求交集的算法复杂度为O(N的平方),在设计集合存储策略的时候还是尽量少用交集运算;
事务的 ACID 性质
在传统的关系式数据库中,常常用 ACID 性质来检验事务功能的安全性。Redis 事务保证了其中的一致性(C)和隔离性(I),但并不保证原子性(A)和持久性(D)。
单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以Redis 事务的执行并不是原子性的。如果一个事务队列中的所有命令都被成功地执行,那么称这个事务执行成功。另一方面,如果 Redis 服务器进程在执行事务的过程中被停止——比如接到 KILL 信号、宿主机器停机,等等,那么事务执行失败。当事务失败时,Redis 也不会进行任何的重试或者回滚动作。
因为事务不过是用队列包裹起了一组 Redis 命令,并没有提供任何额外的持久性功能,所以事务的持久性由 Redis 所使用的持久化模式决定。
详见:http://origin.redisbook.com/en/latest/feature/transaction.html#acid
支持Lua脚本
Lua 脚本功能是 Reids 2.6 版本的最大亮点,通过内嵌对 Lua 环境的支持,Redis 解决了长久以来不能高效地处理 CAS(check-and-set)命令的缺点,并且可以通过组合使用多个命令,轻松实现以前很难实现或者不能高效实现的模式。
Lua脚本与Redis间通过伪终端交互
因为 Redis 命令必须通过客户端来执行,所以需要在服务器状态中创建一个无网络连接的伪客户端(fake client),专门用于执行 Lua 脚本中包含的 Redis 命令:当 Lua 脚本需要执行 Redis 命令时,它通过伪客户端来向服务器发送命令请求,服务器在执行完命令之后,将结果返回给伪客户端,而伪客户端又转而将命令结果返回给 Lua 脚本。
注 这个伪客户端是无网络连接的,那是如何和redis通信的么?是在一个进程中?
消除脚本的执行的随机性
和随机性质类似,如果一个脚本的执行对任何副作用产生了依赖,那么这个脚本每次执行所产生的结果都可能会不一样。为了解决这个问题,Redis 对 Lua 环境所能执行的脚本做了一个严格的限制——所有脚本都必须是无副作用的纯函数(pure function)。为此,Redis 对 Lua 环境做了一些列相应的措施:
? 不提供访问系统状态状态的库(比如系统时间库)。
? 禁止使用 load?le 函数。
? 如果脚本在执行带有随机性质的命令(比如 RANDOMKEY ),或者带有副作用的命令(比如 TIME )之后,试图执行一个写入命令(比如 SET ),那么 Redis 将阻止这个脚本继续运行,并返回一个错误。
? 如果脚本执行了带有随机性质的读命令(比如 SMEMBERS ),那么在脚本的输出返回给Redis 之前,会先被执行一个自动的字典序排序,从而确保输出结果是有序的。
? 用 Redis 自己定义的随机生成函数,替换 Lua 环境中 math 表原有的 math.random 函数和 math.randomseed 函数,新的函数具有这样的性质:每次执行 Lua 脚本时,除非显式地调用 math.randomseed ,否则 math.random 生成的伪随机数序列总是相同的。
键的过期时间
通过 EXPIRE 、PEXPIRE 、EXPIREAT 和 PEXPIREAT 四个命令,客户端可以给某个存在的键设置过期时间,当键的过期时间到达时,键就不再可用;
当存储的键用于缓存时,通常我们需要设置一个过期时间,到期后由redis删除;
一般为两步:
SET key value
EXPIRE key seconds
有了SETEX,只需要一步就可实现设置值和过期时间:
SETEX key seconds value
进一步想,如果所有的往数据库中增加值的命令都有相应的设置过期时间的函数,岂不是很美好?当然,想归想,实际并非如此,除了SET有SETEX,其它的如集合操作SADD,都没有这样的一步操作命令;
过期键的清除
如果一个键是过期的,那它什么时候会被删除?
这个问题有三种可能的答案:
- 定时删除:在设置键的过期时间时,创建一个定时事件,当过期时间到达时,由事件处理器自动执行键的删除操作。
- 惰性删除:放任键过期不管,但是在每次从 dict 字典中取出键值时,要检查键是否过期,如果过期的话,就删除它,并返回空;如果没过期,就返回键值。
- 定期删除:每隔一段时间,对 expires 字典进行检查,删除里面的过期键;定期删除是这两种策略的一种折中:
? 它每隔一段时间执行一次删除操作,并通过限制删除操作执行的时长和频率,籍此来减少删除操作对 CPU 时间的影响。
? 另一方面,通过定期删除过期键,它有效地减少了因惰性删除而带来的内存浪费。
定时删除和惰性删除这两种删除方式在单一使用时都有明显的缺陷:定时删除占用太多 CPU 时间,惰性删除浪费太多内存;
Redis 使用的过期键删除策略是惰性删除加上定期删除, 这两个策略相互配合,可以很好地在合理利用 CPU 时间和节约内存空间之间取得平衡。
参考:http://origin.redisbook.com/en/latest/internal/db.html#id20
RDB持久化
rdbSave 函数负责将内存中的数据库数据以 RDB 格式保存到磁盘中,如果 RDB 文件已存在,那么新的 RDB 文件将替换已有的 RDB 文件。在保存 RDB 文件期间,主进程会被阻塞,直到保存完成为止。SAVE 和 BGSAVE 两个命令都会调用 rdbSave 函数,但它们调用的方式各有不同:? SAVE 直接调用 rdbSave ,阻塞 Redis 主进程,直到保存完成为止。在主进程阻塞期间,服务器不能处理客户端的任何请求。? BGSAVE 则 fork 出一个子进程,子进程负责调用 rdbSave ,并在保存完成之后向主进程发送信号,通知保存已完成。因为 rdbSave 在子进程被调用,所以 Redis 服务器在BGSAVE 执行期间仍然可以继续处理客户端的请求。
SAVE 、 BGSAVE 、 AOF 写入和 BGREWRITEAOF
当 SAVE 执行时,Redis 服务器是阻塞的,所以当 SAVE 正在执行时,新的SAVE 、BGSAVE 或 BGREWRITEAOF 调用都不会产生任何作用。只有在上一个 SAVE 执行完毕、Redis 重新开始接受请求之后,新的 SAVE 、BGSAVE 或BGREWRITEAOF 命令才会被处理。另外,因为AOF写入由后台线程完成,而BGREWRITEAOF 则由子进程完成,所以在SAVE执行的过程中,AOF 写入和 BGREWRITEAOF 可以同时进行。
执行 SAVE 命令之前,服务器会检查 BGSAVE 是否正在执行当中,如果是的话,服务器就不调用 rdbSave ,而是向客户端返回一个出错信息,告知在 BGSAVE 执行期间,不能执行SAVE 。这样做可以避免 SAVE 和 BGSAVE 调用的两个 rdbSave 交叉执行,造成竞争条件。另一方面,当 BGSAVE 正在执行时,调用新 BGSAVE 命令的客户端会收到一个出错信息,告知 BGSAVE 已经在执行当中。
BGREWRITEAOF 和 BGSAVE 不能同时执行:
? 如果 BGSAVE 正在执行,那么 BGREWRITEAOF 的重写请求会被延迟到 BGSAVE 执行完毕之后进行,执行 BGREWRITEAOF 命令的客户端会收到请求被延迟的回复。
? 如果 BGREWRITEAOF 正在执行,那么调用 BGSAVE 的客户端将收到出错信息,表示这两个命令不能同时执行。BGREWRITEAOF 和 BGSAVE 两个命令在操作方面并没有什么冲突的地方,不能同时执行它们只是一个性能方面的考虑:并发出两个子进程,并且两个子进程都同时进行大量的磁盘写入操作,这怎么想都不会是一个好主意。
总的来说:
rdbSave 会将数据库数据保存到 RDB 文件,并在保存完成之前阻塞调用者。
? SAVE 命令直接调用 rdbSave ,阻塞 Redis 主进程;BGSAVE 用子进程调用 rdbSave ,主进程仍可继续处理命令请求。
? SAVE 执行期间,AOF 写入可以在后台线程进行,BGREWRITEAOF 可以在子进程进行,所以这三种操作可以同时进行。
? 为了避免产生竞争条件,BGSAVE 执行时,SAVE 命令不能执行。
? 为了避免性能问题,BGSAVE 和 BGREWRITEAOF 不能同时执行
处理加载数据期间到达的请求
载入期间,服务器每载入 1000 个键就处理一次所有已到达的请求,不过只有 PUBLISH 、SUBSCRIBE 、PSUBSCRIBE 、UNSUBSCRIBE 、PUNSUBSCRIBE 五个命令的请求会被正确地处理,其他命令一律返回错误。等到载入完成之后,服务器才会开始正常处理所有命令。
AOF优于RDB
因为 AOF 文件的保存频率通常要高于 RDB 文件保存的频率,所以一般来说,AOF 文件中的数据会比 RDB 文件中的数据要新。因此,如果服务器在启动时,打开了 AOF 功能,那么程序优先使用 AOF 文件来还原数据。只有在 AOF 功能未打开的情况下,Redis 才会使用 RDB 文件来还原数据。
AOF写文件的三阶段
命令到 AOF 文件的整个过程可以分为三个阶段:
- 命令传播:Redis 将执行完的命令、命令的参数、命令的参数个数等信息发送到 AOF 程序中。2. 缓存追加:AOF 程序根据接收到的命令数据,将命令转换为网络通讯协议的格式,然后将协议内容追加到服务器的 AOF 缓存中。
- 文件写入和保存:AOF 缓存中的内容被写入到 AOF 文件末尾,如果设定的 AOF 保存条件被满足的话,fsync 函数或者 fdatasync 函数会被调用,将写入的内容真正地保存到磁盘中。
AOF 保存模式对性能和安全性的影响
redis 目前支持三种 AOF 保存模式,它们分别是:
- AOF_FSYNC_NO :不保存。
- AOF_FSYNC_EVERYSEC :每一秒钟保存一次。
- AOF_FSYNC_ALWAYS :每执行一个命令保存一次。
三种 AOF 保存模式,它们对服务器主进程的阻塞情况如下:
- 不保存(AOF_FSYNC_NO):写入和保存都由主进程执行,两个操作都会阻塞主进程。
- 每一秒钟保存一次(AOF_FSYNC_EVERYSEC):写入操作由主进程执行,阻塞主进程。保存操作由子线程执行,不直接阻塞主进程,但保存操作完成的快慢会影响写入操作的阻塞时长。
- 每执行一个命令保存一次(AOF_FSYNC_ALWAYS):和模式 1 一样。因为阻塞操作会让 Redis 主进程无法持续处理请求,所以一般说来,阻塞操作执行得越少、完成得越快,Redis 的性能就越好。
AOF 文件的读取和数据还原
模式 1 的保存操作只会在 AOF 关闭或 Redis 关闭时执行,或者由操作系统触发,在一般情况下,这种模式只需要为写入阻塞,因此它的写入性能要比后面两种模式要高,当然,这种性能的提高是以降低安全性为代价的:在这种模式下,如果运行的中途发生停机,那么丢失数据的数量由操作系统的缓存冲洗策略决定。
模式 2 在性能方面要优于模式 3 ,并且在通常情况下,这种模式最多丢失不多于 2 秒的数据,所以它的安全性要高于模式 1 ,这是一种兼顾性能和安全性的保存方案。
模式 3 的安全性是最高的,但性能也是最差的,因为服务器必须阻塞直到命令信息被写入并保存到磁盘之后,才能继续处理请求。
AOF 后台重写
AOF 重写程序可以很好地完成创建一个新 AOF 文件的任务,但是,在执行这个程序的时候,调用者线程会被阻塞。很明显,作为一种辅佐性的维护手段,Redis 不希望 AOF 重写造成服务器无法处理请求,所以Redis 决定将 AOF 重写程序放到(后台)子进程里执行,这样处理的最大好处是:
- 子进程进行 AOF 重写期间,主进程可以继续处理命令请求。
- 子进程带有主进程的数据副本,使用子进程而不是线程,可以在避免锁的情况下,保证数据的安全性。不过,使用子进程也有一个问题需要解决:因为子进程在进行 AOF 重写期间,主进程还需要继续处理命令,而新的命令可能对现有的数据进行修改,这会让当前数据库的数据和重写后的AOF 文件中的数据不一致。为了解决这个问题,Redis 增加了一个 AOF 重写缓存,这个缓存在 fork 出子进程之后开始启用,Redis 主进程在接到新的写命令之后,除了会将这个写命令的协议内容追加到现有的 AOF文件之外,还会追加到这个缓存中
注 子进程与线程在访问数据上的区别,难道不是都需加锁么
ref:http://blog.csdn.net/wangkehuai/article/details/7089323
AOF 后台重写的触发条件
子进程完成 AOF 重写之后,它会向父进程发送一个完成信号,父进程在接到完成信号之后,会调用一个信号处理函数,并完成以下工作:
- 将 AOF 重写缓存中的内容全部写入到新 AOF 文件中。
- 对新的 AOF 文件进行改名,覆盖原有的 AOF 文件。当步骤 1 执行完毕之后,现有 AOF 文件、新 AOF 文件和数据库三者的状态就完全一致了。当步骤 2 执行完毕之后,程序就完成了新旧两个 AOF 文件的交替。
在整个 AOF后台重写过程中,只有最后的写入缓存和改名操作会造成主进程阻塞,在其他时候,AOF 后台重写都不会对主进程造成阻塞,这将 AOF 重写对性能造成的影响降到了最低。
当 serverCron 函数执行时,它都会检查以下条件是否全部满足,如果是的话,就会触发自动的 AOF 重写:
- 没有 BGSAVE 命令在进行。
- 没有 BGREWRITEAOF 在进行。
- 当前 AOF 文件大小大于 server.aof_rewrite_min_size (默认值为 1 MB)。
- 当前 AOF 文件大小和最后一次 AOF 重写后的大小之间的比率大于等于指定的增长百分比。默认情况下,增长百分比为 100% ,也即是说,如果前面三个条件都已经满足,并且当前 AOF文件大小比最后一次 AOF 重写时的大小要大一倍的话,那么触发自动 AOF 重写。
事件
事件是 Redis 服务器的核心,它处理两项重要的任务:
- 处理文件事件:在多个客户端中实现多路复用,接受它们发来的命令请求,并将命令的执行结果返回给客户端。
- 时间事件:实现服务器常规操作(server cron job)
文件事件
Redis 服务器通过在多个客户端之间进行多路复用,从而实现高效的命令请求处理:多个客户端通过套接字连接到 Redis 服务器中,但只有在套接字可以无阻塞地进行读或者写时,服务器才会和这些客户端进行交互。
当服务器有命令结果要返回客户端,而客户端又有新命令请求进入时,服务器先处理新命令请求。
事件的执行与调度
Redis 里面既有文件事件,又有时间事件,那么如何调度这两种事件就成了一个关键问题。简单地说,Redis 里面的两种事件呈合作关系,它们之间包含以下三种属性:
- 一种事件会等待另一种事件执行完毕之后,才开始执行,事件之间不会出现抢占。
- 事件处理器先处理文件事件(处理命令请求),再执行时间事件(调用 serverCron)
- 文件事件的等待时间(类 poll 函数的最大阻塞时间),由距离到达时间最短的时间事件决定。
说明:
? 时间事件分为单次执行事件和循环执行事件,服务器常规操作 serverCron 就是循环事件。
? 文件事件和时间事件之间是合作关系:一种事件会等待另一种事件完成之后再执行,不会出现抢占情况。
命令的请求、处理和结果返回
Redis 以多路复用的方式来处理多个客户端,为了让多个客户端之间独立分开、不互相干扰,服务器为每个已连接客户端维持一个 redisClient 结构,从而单独保存该客户端的状态信息。
当客户端连上服务器之后,客户端就可以向服务器发送命令请求了。从客户端发送命令请求,到命令被服务器处理、并将结果返回客户端,整个过程有以下步骤:
- 客户端通过套接字向服务器传送命令协议数据。
- 服务器通过读事件来处理传入数据,并将数据保存在客户端对应 redisClient 结构的查询缓存中。
- 根据客户端查询缓存中的内容,程序从命令表中查找相应命令的实现函数。
- 程序执行命令的实现函数,修改服务器的全局状态 server 变量,并将命令的执行结果保存到客户端 redisClient 结构的回复缓存中,然后为该客户端的 fd 关联写事件。
- 当客户端 fd 的写事件就绪时,将回复缓存中的命令结果传回给客户端。至此,命令执行完毕。
Posted by: 大CC | 11JUL,2014
博客:blog.me115.com [订阅]
微博:新浪微博
原文地址:《Redis设计与实现》读书笔记, 感谢原作者分享。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1659
1659
 14
1416
52
1310
25
1258
29
1232
24
14
1416
52
1310
25
1258
29
1232
24

 小紅書メモを削除する方法
Mar 21, 2024 pm 08:12 PM
小紅書メモを削除する方法
Mar 21, 2024 pm 08:12 PM
小紅書メモを削除するにはどうすればよいですか? メモは小紅書アプリで編集できます。ほとんどのユーザーは小紅書メモの削除方法を知りません。次に、エディターがユーザーに小紅書メモの削除方法に関する写真とテキストを提供します。チュートリアル、興味のあるユーザーが来て、それを受講してください見てください!小紅書使い方チュートリアル 小紅書メモの削除方法 1. まず小紅書アプリを開いてメインページに入り、右下隅の[自分]を選択して特別エリアに入ります; 2. 次に、マイエリアで、表示されているメモページをクリックします下の図で、削除したいメモを選択します; 3. メモページに入り、右上隅の [3 つの点] をクリックします; 4. 最後に、下部に機能バーが展開され、[削除] をクリックして完了します。
 小紅書に関する削除されたメモは復元できますか?
Oct 31, 2023 pm 05:36 PM
小紅書に関する削除されたメモは復元できますか?
Oct 31, 2023 pm 05:36 PM
小紅書から削除されたメモは復元できません。小紅書は知識共有とショッピングのプラットフォームとして、ユーザーにメモを記録し、役立つ情報を収集する機能を提供します。小紅書氏の公式声明によると、削除されたメモは復元できないとのこと。小紅書プラットフォームには、専用のノート回復機能はありません。これは、Xiaohongshu でメモが削除されると、誤って削除されたか、その他の理由であったとしても、プラットフォームから削除されたコンテンツを取得することは通常不可能であることを意味します。特別な状況が発生した場合は、Xiaohongshu のカスタマー サービス チームに連絡して、問題の解決に協力できるかどうかを確認してください。
 小紅書に投稿したメモが見つからない場合はどうすればよいですか?送信したばかりのメモが見つからない理由は何ですか?
Mar 21, 2024 pm 09:30 PM
小紅書に投稿したメモが見つからない場合はどうすればよいですか?送信したばかりのメモが見つからない理由は何ですか?
Mar 21, 2024 pm 09:30 PM
小紅書のユーザーとして、私たちは皆、公開されたノートが突然消えてしまう状況に遭遇したことがありますが、間違いなく混乱し、心配しています。この場合、どうすればよいでしょうか?この記事では、「小紅書が公開したメモが見つからない場合の対処方法」というテーマに焦点を当て、詳細な回答を提供します。 1. 小紅書が発行したメモが紛失した場合はどうすればよいですか?まず、パニックにならないでください。メモがなくなっていることに気づいた場合は、パニックに陥らず、落ち着いて行動することが重要です。これは、プラットフォームのシステム障害または操作エラーが原因である可能性があります。リリース記録の確認も簡単です。小紅書アプリを開き、「自分」→「公開」→「すべての出版物」をクリックするだけで、自分の出版記録を表示できます。ここでは、以前に公開されたノートを簡単に見つけることができます。 3.再投稿。見つかったら
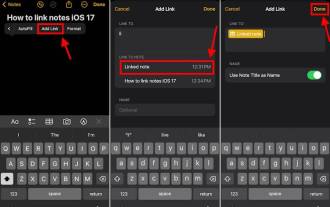 最新のiOS 17システムでiPhoneにApple Notesを接続する方法
Sep 22, 2023 pm 05:01 PM
最新のiOS 17システムでiPhoneにApple Notesを接続する方法
Sep 22, 2023 pm 05:01 PM
リンクの追加機能を使用して iPhone で AppleNotes をリンクします。注: iOS17 がインストールされている場合、iPhone 上で Apple Notes 間のリンクを作成することができます。 iPhone でメモ アプリを開きます。次に、リンクを追加するメモを開きます。新しいメモを作成することもできます。画面上の任意の場所をクリックします。メニューが表示されます。右側の矢印をクリックして、「リンクの追加」オプションを表示します。クリックして。ここで、メモの名前または Web ページの URL を入力できます。次に、右上隅の「完了」をクリックすると、追加されたリンクがメモに表示されます。単語にリンクを追加したい場合は、単語をダブルクリックして選択し、「リンクを追加」を選択して、 を押します。
 小紅書でノートに商品リンクを追加する方法 小紅書でノートに商品リンクを追加するチュートリアル
Mar 12, 2024 am 10:40 AM
小紅書でノートに商品リンクを追加する方法 小紅書でノートに商品リンクを追加するチュートリアル
Mar 12, 2024 am 10:40 AM
小紅書でメモに商品リンクを追加するにはどうすればよいですか?小紅書アプリでは、ユーザーはさまざまなコンテンツを閲覧できるだけでなく、ショッピングもできるため、このアプリにはショッピングのおすすめや良い商品の共有に関するコンテンツがたくさんあります。このアプリでは、ショッピング体験を共有したり、協力してくれる販売者を見つけたり、メモにリンクを追加したりすることもできます。便利なだけでなく、専門家がいくつかの機能を備えているため、多くの人がこのアプリをショッピングに使用したいと考えています。興味深いコンテンツを閲覧して、自分に合った衣料品があるかどうかを確認できます。ノートに商品リンクを追加する方法を見てみましょう! 小紅書ノートに商品リンクを追加する方法 携帯電話のデスクトップでアプリを開きます。アプリのホームページをクリックします
 Microsoft、読書進捗状況のアップデートを展開、読書コーチは 2022 年夏に登場
Apr 27, 2023 pm 08:19 PM
Microsoft、読書進捗状況のアップデートを展開、読書コーチは 2022 年夏に登場
Apr 27, 2023 pm 08:19 PM
パンデミックが始まって以来、教育の状況は劇的に変化しました。これは教師と生徒の両方に影響を与え、さらには彼らの教育ニーズにも影響を与えます。その結果、私たちは読書の進歩を含むさまざまな革新的な教育ツールの誕生を目の当たりにしてきました。 Microsoft は現在、読書コーチを導入することで学習を次のレベルに引き上げることを計画しています。 Microsoft 教育担当副社長のペイジ ジョンソン氏は Microsoft Education のブログ投稿で、「公平な教育をサポートする当社の無料読書ツールであるイマーシブ リーダーに読書コーチングが組み込まれることをお知らせできることを嬉しく思います」と述べています。 「現在、あらゆるレベルの生徒が、Microsoft 365 アプリを通じて、高品質でパーソナライズされた読解力の指導を受けることができます。イマーシブ リーダーに読解コーチを組み込むことで、生徒には Microsoft 翻訳も提供されます。
 小紅書でメモのチュートリアルを公開するにはどうすればよいですか?メモを投稿することでユーザーをブロックできますか?
Mar 25, 2024 pm 03:20 PM
小紅書でメモのチュートリアルを公開するにはどうすればよいですか?メモを投稿することでユーザーをブロックできますか?
Mar 25, 2024 pm 03:20 PM
小紅書はライフスタイル共有プラットフォームとして、食、旅行、美容などさまざまな分野のメモをカバーしています。多くのユーザーは小紅書でメモを共有したいと思っていますが、その方法がわかりません。この記事では、Xiaohongshu にメモを投稿するプロセスを詳しく説明し、プラットフォーム上で特定のユーザーをブロックする方法を検討します。 1.小紅書でメモのチュートリアルを公開するにはどうすればよいですか? 1. 登録とログイン: まず、携帯電話に小紅書アプリをダウンロードし、登録とログインを完了する必要があります。パーソナルセンターに個人情報を記入することは非常に重要です。アバターをアップロードし、ニックネームや自己紹介を記入することで、他のユーザーがあなたの情報を理解しやすくなり、メモに注意を向けやすくなります。 3. 公開チャネルを選択します。ホームページの下部にある [メモを送信] ボタンをクリックし、公開するチャネルを選択します。
 iPhone のメモ アプリで印刷したメモや手書きのメモをスキャンします
Nov 29, 2023 pm 11:19 PM
iPhone のメモ アプリで印刷したメモや手書きのメモをスキャンします
Nov 29, 2023 pm 11:19 PM
2022 年、Apple は iPhone および iPad のメモ アプリに、印刷または手書きのテキストをすばやくスキャンしてデジタル テキスト形式で保存できる新機能を追加しました。それがどのように機能するかを学び続けてください。 iOS および iPadOS の以前のバージョンでは、Apple のメモ アプリにテキストをスキャンするには、メモのテキスト フィールドをタップしてから、ポップアップ メニューの [ライブ テキスト] オプションをタップする必要がありました。ただし、Apple は 2022 年に現実世界のメモのデジタル化を容易にします。次の手順では、iOS 15.4 または iPadOS 15.4 以降を実行しているデバイスでこれを行う方法を示します。 iPhone または iPad で、「」を開きます。
