

Kafka原理和集群测试

Kafka是一个消息系统,由LinkedIn贡献给Apache基金会,称为Apache的一个顶级项目。Kafka最初用作LinkedIn的活动流(activity stream)和运营数据处理管道(pipeline)的基
Kafka是一个消息系统,由LinkedIn贡献给Apache基金会,称为Apache的一个顶级项目。Kafka最初用作LinkedIn的活动流(activity stream)和运营数据处理管道(pipeline)的基础。它具有可扩展、吞吐量大和可持久化等特征,以及非常好的分区、复制和容错特征。
Kafka的关键设计决策
1). Kafka在设计之时为就将持久化消息作为通常的使用情况进行了考虑。
2). Kafka主要的设计约束是吞吐量,而不是功能。
3). Kafka有关哪些数据已经被使用了的状态信息保存为数据使用者(consumer)的一部分,而不是保存在服务器之上。
4). Kafka是一种显式的分布式系统。它假设,数据生产者(producer)、代理(brokers)和数据使用者(consumer)分散于多台机器之上。
而相比而言,传统的消息队列不能很好的支持(如超长的未处理数据、不能有效持久化)。对于数据的可用性,Kafka提供了两个保证:
(1). 生产者发送到Topic的分区上消息将会按照它们发送的顺序,而消费者收到的消息也是此顺序
(2). 如果一个Topic配置了复制因子( replication facto)为N, 那么可以允许N-1服务器当掉而不丢失任何已经增加的消息
Kafka中几个关键术语
Topic:Kafka将消息种子(Feed)分门别类, 每一类的消息称之为话题(Topic).
Producer:发布消息的对象称之为话题生产者(Kafka topic producer)
Consumer:订阅消息并处理发布的消息的种子的对象称之为话题消费者(consumers)
Broker:已发布的消息保存在一组服务器中,称之为Kafka集群。集群中的每一个服务器都是一个代理(Broker). 消费者可以订阅一个或多个话题,并从Broker拉数据,从而消费这些已发布的消息。
Kafka中的Topic

Topic是发布的消息的类别或者种子Feed名。对于每一个Topic, Kafka集群维护这一个分区的log,就像下图中的示例:Kafka集群
每一个分区都是一个顺序的、不可变的消息队列, 并且可以持续的添加。分区中的消息都被分配了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的。
Kafka集群保持所有的消息,直到它们过期,无论消息是否被消费了。
实际上消费者所持有的仅有的元数据就是这个偏移量,也就是消费者在这个log中的位置。 这个偏移量由消费者控制:正常情况当消费者消费消息的时候,偏移量也线性的的增加。但是实际偏移量由消费者控制,消费者可以将偏移量重置为更老的一个偏移量,重新读取消息。
可以看到这种设计对消费者来说操作自如, 一个消费者的操作不会影响其它消费者对此log的处理。
再说说分区。Kafka中采用分区的设计有几个目的。
一、可以处理更多的消息,不受单台服务器的限制。Topic拥有多个分区意味着它可以进行扩展,并处理更多的数据。
二、分区可以作为并行处理的单元。
Topic的分区Log被分布到集群中的多个服务器上。每个服务器处理它持有的分区。 根据配置每个分区还可以复制到其它服务器作为备份容错。
每个分区有一个leader,零或多个replica。Leader处理此分区的所有的读写请求而replica被动的复制数据。如果leader当机,其它的一个replica会被推举为新的leader。
一台服务器可能同时是一个分区的leader,另一个分区的replica。 这样可以平衡负载,避免所有的请求都只让一台或者某几台服务器处理。
关于复制原理,参考下面官档翻译:
Kafka 的集群复制设计
Kafka的集群部署
Kafka中主要有三种模式,
单机broker模式
单机多broker模式(伪分布式)
多机多broker模式(集群)
和hadoop一样,前两种多用于开发测试。第三种才是实际生产中可用的部署模式,下面介绍一下三节点kafka集群的部署流程
软件的安装直接解压缩即可:
tar xzvf kafka_2.10-0.8.1.1.tgz mkdir /var/kafka && mkdir /var/zookeeper
关键参数的解释,可以参考http://debugo.com/kafka-params/
vim kafka_2.10-0.8.1.1/config/server.properties
#在默认的配置上,我只修改了3个地方。三个主机debugo01,debugo02,debugo03分别对应id为1,2,3 broker.id=3 log.dirs=/var/kafka zookeeper.connect=debugo01:2181,debugo02:2181,debugo03:2181 配置zookeeper,修改DataDir并加入集群参数 vim kafka_2.10-0.8.1.1/config/zookeeper.properties initLimit=5 syncLimit=2 server.1=debugo01:2888:3888 server.2=debugo02:2888:3888 server.3=debugo03:2888:3888 dataDir=/var/zookeeper #分别将1,2,3写入三个主机的myid文件 echo "1" >> /var/zookeeper/myid
在debugo01,debugo02,debugo03上分别启动zookeeper和kafka Server
bin/zookeeper-server-start.sh config/zookeeper.properties # 启动kafka Server bin/kafka-server-start.sh config/server.properties
这时可以在log中找到,新的broker已经将数据注册到znode中。
#####debugo01#####
[2014-12-07 20:54:20,506] INFO Awaiting socket connections on debugo01:9092. (kafka.network.Acceptor)
[2014-12-07 20:54:20,521] INFO [Socket Server on Broker 1], Started (kafka.network.SocketServer)
[2014-12-07 20:54:20,649] INFO Will not load MX4J, mx4j-tools.jar is not in the classpath (kafka.utils.Mx4jLoader$)
[2014-12-07 20:54:20,725] INFO 1 successfully elected as leader (kafka.server.ZookeeperLeaderElector)
[2014-12-07 20:54:20,876] INFO Registered broker 1 at path /brokers/ids/1 with address debugo01:9092. (kafka.utils.ZkUtils$)
[2014-12-07 20:54:20,907] INFO [Kafka Server 1], started (kafka.server.KafkaServer)
[2014-12-07 20:54:20,993] INFO New leader is 1 (kafka.server.ZookeeperLeaderElector$LeaderChangeListener)
#####debugo02#####
[2014-12-07 20:54:35,896] INFO Awaiting socket connections on 0.0.0.0:9092. (kafka.network.Acceptor)
[2014-12-07 20:54:35,913] INFO [Socket Server on Broker 2], Started (kafka.network.SocketServer)
[2014-12-07 20:54:36,073] INFO Will not load MX4J, mx4j-tools.jar is not in the classpath (kafka.utils.Mx4jLoader$)
[2014-12-07 20:54:36,179] INFO conflict in /controller data: {"version":1,"brokerid":2,"timestamp":"1417956876081"} stored data: {"version":1,"brokerid":1,"timestamp":"1417956860689"} (kafka.utils.ZkUtils$)
[2014-12-07 20:54:36,398] INFO Registered broker 2 at path /brokers/ids/2 with address debugo02:9092. (kafka.utils.ZkUtils$)
[2014-12-07 20:54:36,420] INFO [Kafka Server 2], started (kafka.server.KafkaServer)
#####debugo03#####
[2014-12-07 20:54:43,535] INFO Awaiting socket connections on 0.0.0.0:9092. (kafka.network.Acceptor)
[2014-12-07 20:54:43,549] INFO [Socket Server on Broker 3], Started (kafka.network.SocketServer)
[2014-12-07 20:54:43,728] INFO Will not load MX4J, mx4j-tools.jar is not in the classpath (kafka.utils.Mx4jLoader$)
[2014-12-07 20:54:43,783] INFO conflict in /controller data: {"version":1,"brokerid":3,"timestamp":"1417956883737"} stored data: {"version":1,"brokerid":1,"timestamp":"1417956860689"} (kafka.utils.ZkUtils$)
[2014-12-07 20:54:43,999] INFO Registered broker 3 at path /brokers/ids/3 with address debugo03:9092. (kafka.utils.ZkUtils$)
[2014-12-07 20:54:44,018] INFO [Kafka Server 3], started (kafka.server.KafkaServer)Topic的分区和复制
1. 创建debugo01,这个topic分区数为3,复制为1(不复制)。该topic跨越全部broker。下面管理命令在任意kafka节点上执行即可
bin/kafka-topics.sh --create --zookeeper debugo01,debugo02,debugo03 --replication-factor 1 --partitions 3 --topic debugo01 Created topic "debugo01".
2. 创建debugo02,这个topic分区数为1,复制为3(每个主机都有一份)。该topic跨越全部broker。下面管理命令在任意kafka节点上执行即可
bin/kafka-topics.sh --create --zookeeper debugo01,debugo02,debugo03 --replication-factor 3 --partitions 1 --topic debugo02
3. 列出topic信息
[root@debugo01 kafka_2.10-0.8.1.1]# bin/kafka-topics.sh --list --zookeeper localhost:2181 debugo01 debugo02
4. 列出topic描述信息
[root@debugo01 kafka_2.10-0.8.1.1]# bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic debugo01 Topic:debugo01 PartitionCount:3 ReplicationFactor:1 Configs: Topic: debugo01 Partition: 0 Leader: 1 Replicas: 1 Isr: 1 Topic: debugo01 Partition: 1 Leader: 2 Replicas: 2 Isr: 2 Topic: debugo01 Partition: 2 Leader: 3 Replicas: 3 Isr: 3
5. 检查log目录,对于topic debugo01,debugo01为0号分区,debugo02为1号分区。而topic debugo02则复制了3份,都为0号分区
[root@debugo01 kafka]# ll total 24 drwxr-xr-x 2 root root 4096 Dec 7 21:15 debugo01-0 drwxr-xr-x 2 root root 4096 Dec 7 21:16 debugo02-0 [root@debugo02 kafka]# ll total 24 drwxr-xr-x 2 root root 4096 Dec 7 21:15 debugo01-1 drwxr-xr-x 2 root root 4096 Dec 7 21:16 debugo02-0 #而每个分区下面都生成了index和log文件 [root@debugo01 debugo01-0]# ls 00000000000000000000.index 00000000000000000000.log
6. 下面topic debugo03,replication-factor为2,partition为3.那么broker id为1的debugo01会如下面describe所示,保存0号分区和1号分区。
而0号分区的repica leader为broker id = 3,包含3和1两个replicas。
bin/kafka-topics.sh --create --zookeeper debugo01,debugo02,debugo03 --replication-factor 2 --partitions 3 --topic debugo03 Created topic "debugo03". bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic debugo03 [root@debugo01 kafka_2.10-0.8.1.1]# bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic debugo03 Topic:debugo03 PartitionCount:3 ReplicationFactor:2 Configs: Topic: debugo03 Partition: 0 Leader: 3 Replicas: 3,1 Isr: 3,1 Topic: debugo03 Partition: 1 Leader: 1 Replicas: 1,2 Isr: 1,2 Topic: debugo03 Partition: 2 Leader: 2 Replicas: 2,3 Isr: 2,3 [root@debugo01 kafka_2.10-0.8.1.1]# ll /var/kafka/debugo03* /var/kafka/debugo03-0: total 0 -rw-r--r-- 1 root root 10485760 Dec 7 21:34 00000000000000000000.index -rw-r--r-- 1 root root 0 Dec 7 21:34 00000000000000000000.log /var/kafka/debugo03-1: total 0 -rw-r--r-- 1 root root 10485760 Dec 7 21:34 00000000000000000000.index -rw-r--r-- 1 root root 0 Dec 7 21:34 00000000000000000000.log
消息的产生和消费
两个终端分别打开producer和consumer进行测试
<terminal> bin/kafka-console-producer.sh --broker-list debugo01:9092 --topic debugo03 hello kafka hello debugo <terminal> bin/kafka-console-consumer.sh --zookeeper debugo01:2181 --from-beginning --topic debugo03 hello kafka hello debugo</terminal></terminal>
下面使用perf命令来测试几个topic的性能,需要先下载kafka-perf_2.10-0.8.1.1.jar,并拷贝到kafka/libs下面。
50W条消息,每条1000字节,batch大小1000,topic为debugo01,4个线程(message size设置太大需要调整相关参数,否则容易OOM)。只用了13秒完成,kafka在多分区支持下吞吐量是非常给力的。
bin/kafka-producer-perf-test.sh --messages 500000 --message-size 1000 --batch-size 1000 --topics debugo01 --threads 4 --broker-list debugo01:9092,debugo02:9092,debugo03:9092 start.time, end.time, compression, message.size, batch.size, total.data.sent.in.MB, MB.sec, total.data.sent.in.nMsg, nMsg.sec 2014-12-07 22:07:56:038, 2014-12-07 22:08:09:413, 0, 1000, 1000, 476.84, 35.6514, 500000, 37383.1776
同样的参数测试debugo02, 由于但分区加复制(replicas-factor=3),用时39秒。所以,适当加大partition数量和broker相关线程数量会极大的提高性能。
bin/kafka-producer-perf-test.sh --messages 500000 --message-size 1000 --batch-size 1000 --topics debugo02 --threads 4 --broker-list debugo01:9092,debugo02:9092,debugo03:9092 start.time, end.time, compression, message.size, batch.size, total.data.sent.in.MB, MB.sec, total.data.sent.in.nMsg, nMsg.sec 2014-12-07 22:13:28:840, 2014-12-07 22:14:07:819, 0, 1000, 1000, 476.84, 12.2332, 500000, 12827.4199
同样的参数测试debugo03,用时30秒。
bin/kafka-producer-perf-test.sh --messages 500000 --message-size 1000 --batch-size 1000 --topics debugo03 --threads 4 --broker-list debugo01:9092,debugo02:9092,debugo03:9092 start.time, end.time, compression, message.size, batch.size, total.data.sent.in.MB, MB.sec, total.data.sent.in.nMsg, nMsg.sec 2014-12-07 22:16:04:895, 2014-12-07 22:16:34:715, 0, 1000, 1000, 476.84, 15.9905, 500000, 16767.2703
同理,测试comsumer的性能。
bin/kafka-consumer-perf-test.sh --zookeeper debugo01,debugo02,debugo03 --messages 500000 --topic debugo01 --threads 3 start.time, end.time, fetch.size, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec 2014-12-07 22:19:04:527, 2014-12-07 22:19:17:184, 1048576, 476.8372, 62.2747, 500000, 65299.7257 bin/kafka-consumer-perf-test.sh --zookeeper debugo01,debugo02,debugo03 --messages 500000 --topic debugo02 --threads 3 start.time, end.time, fetch.size, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec [2014-12-07 22:19:59,938] WARN [perf-consumer-78853_debugo01-1417961999315-4a5941ef], No broker partitions consumed by consumer thread perf-consumer-78853_debugo01-1417961999315-4a5941ef-1 for topic debugo02 (kafka.consumer.ZookeeperConsumerConnector) [2014-12-07 22:19:59,938] WARN [perf-consumer-78853_debugo01-1417961999315-4a5941ef], No broker partitions consumed by consumer thread perf-consumer-78853_debugo01-1417961999315-4a5941ef-2 for topic debugo02 (kafka.consumer.ZookeeperConsumerConnector) 2014-12-07 22:20:01:008, 2014-12-07 22:20:08:971, 1048576, 476.8372, 160.9305, 500000, 168747.8907 bin/kafka-consumer-perf-test.sh --zookeeper debugo01,debugo02,debugo03 --messages 500000 --topic debugo03 --threads 3 start.time, end.time, fetch.size, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec ?2014-12-07 22:21:27:421, 2014-12-07 22:21:39:918, 1048576, 476.8372, 63.6037, 500002, 66693.6108
^^
参考
http://blog.csdn.net/smallnest/article/details/38491483
http://www.350351.com/jiagoucunchu/xiaoxixitong/46720.html
http://kafka.apache.org/documentation.html
http://backend.blog.163.com/blog/static/202294126201431723734212/
http://www.inter12.org/archives/842
原文地址:Kafka原理和集群测试, 感谢原作者分享。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1664
1664
 14
1423
52
1317
25
1268
29
1246
24
14
1423
52
1317
25
1268
29
1246
24

 CUDA の汎用行列乗算: 入門から習熟まで!
Mar 25, 2024 pm 12:30 PM
CUDA の汎用行列乗算: 入門から習熟まで!
Mar 25, 2024 pm 12:30 PM
General Matrix Multiplication (GEMM) は、多くのアプリケーションやアルゴリズムの重要な部分であり、コンピューター ハードウェアのパフォーマンスを評価するための重要な指標の 1 つでもあります。 GEMM の実装に関する徹底的な調査と最適化は、ハイ パフォーマンス コンピューティングとソフトウェア システムとハードウェア システムの関係をより深く理解するのに役立ちます。コンピューター サイエンスでは、GEMM を効果的に最適化すると、計算速度が向上し、リソースが節約されます。これは、コンピューター システムの全体的なパフォーマンスを向上させるために非常に重要です。 GEMM の動作原理と最適化方法を深く理解することは、最新のコンピューティング ハードウェアの可能性をより有効に活用し、さまざまな複雑なコンピューティング タスクに対してより効率的なソリューションを提供するのに役立ちます。 GEMMのパフォーマンスを最適化することで
 メッセージを送信したが相手に拒否された場合は何を意味するのでしょうか?
Mar 07, 2024 pm 03:59 PM
メッセージを送信したが相手に拒否された場合は何を意味するのでしょうか?
Mar 07, 2024 pm 03:59 PM
メッセージを送信しましたが、相手に拒否されました これは、送信した情報はデバイスから正常に送信されましたが、何らかの理由で相手がメッセージを受信できなかったことを意味します。具体的には、通常、相手が特定の権限を設定しているか、特定のアクションを行っているため、あなたの情報が正常に受信されないことが原因です。
 ファーウェイのQiankun ADS3.0インテリジェント運転システムは8月に発売され、初めてXiangjie S9に搭載される
Jul 30, 2024 pm 02:17 PM
ファーウェイのQiankun ADS3.0インテリジェント運転システムは8月に発売され、初めてXiangjie S9に搭載される
Jul 30, 2024 pm 02:17 PM
7月29日、AITO Wenjieの40万台目の新車のロールオフ式典に、ファーウェイの常務取締役、ターミナルBG会長、スマートカーソリューションBU会長のYu Chengdong氏が出席し、スピーチを行い、Wenjieシリーズモデルの発売を発表した。 8月にHuawei Qiankun ADS 3.0バージョンが発売され、8月から9月にかけて順次アップグレードが行われる予定です。 8月6日に発売されるXiangjie S9には、ファーウェイのADS3.0インテリジェント運転システムが初搭載される。 LiDARの支援により、Huawei Qiankun ADS3.0バージョンはインテリジェント運転機能を大幅に向上させ、エンドツーエンドの統合機能を備え、GOD(一般障害物識別)/PDP(予測)の新しいエンドツーエンドアーキテクチャを採用します。意思決定と制御)、駐車スペースから駐車スペースまでのスマート運転のNCA機能の提供、CAS3.0のアップグレード
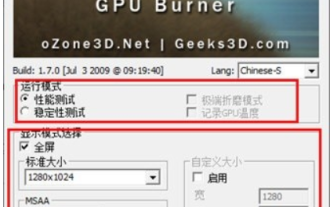 furmark についてどう思いますか? - furmark はどのように資格があるとみなされますか?
Mar 19, 2024 am 09:25 AM
furmark についてどう思いますか? - furmark はどのように資格があるとみなされますか?
Mar 19, 2024 am 09:25 AM
furmark についてどう思いますか? 1. メインインターフェイスで「実行モード」と「表示モード」を設定し、「テストモード」も調整して「開始」ボタンをクリックします。 2. しばらく待つと、グラフィックス カードのさまざまなパラメータを含むテスト結果が表示されます。ファーマークはどのように資格を取得しますか? 1. ファーマークベーキングマシンを使用し、約 30 分間結果を確認します。室温 19 度、ピーク値は 87 度で、基本的に 85 度前後で推移します。大型シャーシ、シャーシ ファン ポートが 5 つあり、前面に 2 つ、上部に 2 つ、背面に 1 つありますが、ファンは 1 つだけ取り付けられています。すべてのアクセサリはオーバークロックされていません。 2. 通常の状況では、グラフィックス カードの通常の温度は「30 ~ 85℃」である必要があります。 3. 周囲温度が高すぎる夏でも、通常の温度は「50〜85℃」です
 nohupの機能と原理の解析
Mar 25, 2024 pm 03:24 PM
nohupの機能と原理の解析
Mar 25, 2024 pm 03:24 PM
nohup の役割と原理の分析 Unix および Unix 系オペレーティング システムでは、nohup はバックグラウンドでコマンドを実行するためによく使用されるコマンドです。ユーザーが現在のセッションを終了したり、ターミナル ウィンドウを閉じたりしても、コマンドはまだ実行され続けています。この記事では、nohup コマンドの機能と原理を詳しく分析します。 1. nohup の役割: バックグラウンドでのコマンドの実行: nohup コマンドを使用すると、ターミナル セッションを終了するユーザーの影響を受けることなく、長時間実行されるコマンドをバックグラウンドで実行し続けることができます。これは実行する必要があります
 常に新しい! Huawei Mate60シリーズがHarmonyOS 4.2にアップグレード:AIクラウドの強化、Xiaoyi方言はとても使いやすい
Jun 02, 2024 pm 02:58 PM
常に新しい! Huawei Mate60シリーズがHarmonyOS 4.2にアップグレード:AIクラウドの強化、Xiaoyi方言はとても使いやすい
Jun 02, 2024 pm 02:58 PM
4月11日、ファーウェイはHarmonyOS 4.2 100台のアップグレード計画を初めて正式に発表し、今回は携帯電話、タブレット、時計、ヘッドフォン、スマートスクリーンなどのデバイスを含む180台以上のデバイスがアップグレードに参加する予定だ。先月、HarmonyOS4.2 100台アップグレード計画の着実な進捗に伴い、Huawei Pocket2、Huawei MateX5シリーズ、nova12シリーズ、Huawei Puraシリーズなどの多くの人気モデルもアップグレードと適応を開始しました。 HarmonyOS によってもたらされる共通の、そして多くの場合新しい体験を楽しむことができる Huawei モデルのユーザーが増えることになります。ユーザーのフィードバックから判断すると、HarmonyOS4.2にアップグレードした後、Huawei Mate60シリーズモデルのエクスペリエンスがあらゆる面で向上しました。特にファーウェイM
 Apple 16 システムのどのバージョンが最適ですか?
Mar 08, 2024 pm 05:16 PM
Apple 16 システムのどのバージョンが最適ですか?
Mar 08, 2024 pm 05:16 PM
Apple 16 システムの最適なバージョンは iOS16.1.4 です。iOS16 システムの最適なバージョンは人によって異なります。日常の使用体験における追加と改善も多くのユーザーから賞賛されています。 Apple 16 システムの最適なバージョンはどれですか? 回答: iOS16.1.4 iOS 16 システムの最適なバージョンは人によって異なる場合があります。公開情報によると、2022 年にリリースされた iOS16 は非常に安定していてパフォーマンスの高いバージョンであると考えられており、ユーザーはその全体的なエクスペリエンスに非常に満足しています。また、iOS16では新機能の追加や日常の使用感の向上も多くのユーザーからご好評をいただいております。特に最新のバッテリー寿命、信号性能、加熱制御に関して、ユーザーからのフィードバックは比較的好評です。ただし、iPhone14を考慮すると、
 新しい仙霞の冒険に参加しましょう! 「朱仙2」「武威検定」の事前ダウンロードが開始されました
Apr 22, 2024 pm 12:50 PM
新しい仙霞の冒険に参加しましょう! 「朱仙2」「武威検定」の事前ダウンロードが開始されました
Apr 22, 2024 pm 12:50 PM
新作ファンタジー妖精MMORPG『朱仙2』の「武威試験」が4月23日より開始されます。原作から数千年後の朱仙大陸で、どのような新たな妖精冒険物語が繰り広げられるのでしょうか?六界の不滅の世界、フルタイムの不滅のアカデミー、自由な不滅の生活、そして不滅の世界のあらゆる種類の楽しみが、不滅の友人たちが直接探索するのを待っています! 「Wuwei Test」の事前ダウンロードが開始されました。Fairy friends は公式 Web サイトにアクセスしてダウンロードできます。サーバーが起動する前に、アクティベーション コードは事前ダウンロードとインストール後に使用できます。完成されました。 『朱仙2』「不作為試験」開催時間:4月23日10:00~5月6日23:59 小説『朱仙』を原作とした朱仙正統続編『朱仙2』の新たな童話冒険篇原作の世界観をベースにゲーム背景を設定。
