

[Leveldb] 实现文档翻译

文件 leveldb是根据单机版BigTable来实现的,但是文件的组织方式却有以下几点不同。 每一个数据库是由存储在文件夹下面的一系列文件集合来实现的,有很多不同类型的文件: Log Files: log文件(*.log) 存储了一系列最近的更新。每一个更新都会追加到当前的lo
文件
leveldb是根据单机版BigTable来实现的,但是文件的组织方式却有以下几点不同。
每一个数据库是由存储在文件夹下面的一系列文件集合来实现的,有很多不同类型的文件:
log文件(*.log) 存储了一系列最近的更新。每一个更新都会追加到当前的log文件中。当一个log文件到达一个预设阈值(默认是4MB),它将会转变成一个有序表,并且为以后的更新操作生成一个新的log文件。
一个 sorted tables (*.sst) 存储一系列有序的key。每一个entry是一个key的value或者一个删除的key。
sorted tables 由多级的方式组成。sorted table 由一个特殊的更新的层级生成(也叫做level-0)。当更新的文件超过某一阈值(通常是4个),所有更新的文件会一起与level-1层的文件进行合并产生一个新的leve-1文件(我们为每2M的数据建立一个level-1层的文件)
更新层的文件可能会包含重复的key,然而在其他层级的文件有着有序不相同的key。加入第L层,L>=1。当在L层文件的大小超过10^L MB 时,一个在L层的文件以及所有在L+1层的文件会形成一个新的文件集合。这些合并操作会逐渐的从level-0到最后一层。
一个MANIFEST文件列出了所有sorted tables的集合,key的序列,一起他重要的元数据。一个新的MANIFEST文件,会在一个数据库重新打开时生成。这个MANIFEST文件以一个log文件的格式,服务的一些更新信息会追加到这个log文件中。
CURRENT是一个简单的文本文件包含最新的一个MANIFEST文件的名字
数据信息会打印在LOG和LOG.old文件中
其他文件用来生成其他的用处,比如LOCK,*.dbtmp等等
Level 0当一个log文件增长到超过阈值时(默认为1MB):
建立一个新的内存表和log文件用于写入以后的更新
在后台:
将之前内存表中的内存写到一个sstable中
丢掉这个内存表
删除旧的log文件和旧的内存表
向level-0层中增加新的sstable
当L层的大小超过它的界限,我们在后台的进程中对它进行压缩。压缩操作从L层和所有L+1层之间选择一个文件。注意如果一个L层的文件只与一个L+1层的文件重叠,,全部的L+1层的文件被用来做压缩的输出文件并且压缩后将会被删除。一方面:因为level-0的特殊性,我们特殊对待从level-0到level-1的压缩:一个level-0的压缩可能会选择超过一个level-0文件因为这些文件会与其他文件有重叠。
一个压缩会合并选择的文件的内存来生成一个L+1文件序列。我们会生成一个新的L+1层的文件在当前输出文件达到文件的大小(2MB)。我们也会生成一个新的输出文件当这些key超过是个L+2文件。最后的规则保证了后续的L+1层文件的压缩不会从L+2层选择过多的数据
老文件会被删除,新文件会被添加到服务的状态中。
一个典型的压缩会通过key空间进行旋转,更多的细节是,对于没一个L层我们记住最后一个key。下一个L层的压缩会从这个key开始选择第一个文件。
合并会丢弃掉重复的值。我们也会丢弃标记删除的key,如果编号更高的层数中包含覆盖当前key的文件。
Level-0 压缩会根据从level0中取的四个1MB的文件,并且最坏情况所有的level-1(10M)。。。我们将会读14MB写14MB。
除了level0的特殊压缩,我们会从L层选择一个2MB的文件。在最坏情况,这个会与其他L+1中的12个文件重叠。压缩过程会读26MB,写26MB。假设一个磁盘的IO速度为100MB最坏情况的压缩会花费0.5秒
如果我们限制后台写的速度,假如100MB的10%,一个压缩过程会花费5秒。如果用户以10MB的速度写,我们可能会建立很多level-0文件。这样在每次合并的过程中花费会上升。
Solution 1: 减少这类问题,当level-0的文件数量足够大时我们可能会增加log文件转换的阈值。阈值下降的趋势越大,内存表需要的内存就越大。
Solution 2: 当level0文件数量上升的时候认为降低写的速率
Solution 3:降低大量合并操作的花费。大部分level-0的文件不进行压缩,而我们只在合并时考虑O(N)复杂度的算法。
不是只生成2MB的文件,而是对于更大的层级我们可以生成更大的文件以减少文件总数,尽管这样会增加合并的花费。我们可以在多个文件夹中共享文件集合。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7681
7681
 15
1639
14
1393
52
1286
25
1229
29
15
1639
14
1393
52
1286
25
1229
29

 Edge ブラウザに付属の翻訳 Web ページが見つからない場合はどうすればよいですか?
Mar 14, 2024 pm 08:50 PM
Edge ブラウザに付属の翻訳 Web ページが見つからない場合はどうすればよいですか?
Mar 14, 2024 pm 08:50 PM
エッジブラウザには翻訳機能が搭載されており、いつでもどこでも翻訳できるため、ユーザーは非常に便利ですが、多くのユーザーは、組み込みの翻訳 Web ページが見つからないという意見を述べています。私が持ってきた翻訳ページがありませんか?このサイトでは、Edge ブラウザーに付属の翻訳された Web ページが見つからない場合に復元する方法を紹介します。 Edge ブラウザーに付属の翻訳 Web ページが表示されない場合の復元方法 1. 翻訳機能が有効になっているかどうかを確認します。Edge ブラウザーで、右上隅にある 3 つの点のアイコンをクリックし、[設定] オプションを選択します。設定ページの左側で、言語オプションを選択します。必ず「翻訳(&R)」してください
 Word文書に朱書きを入れる方法
Mar 01, 2024 am 09:40 AM
Word文書に朱書きを入れる方法
Mar 01, 2024 am 09:40 AM
395ワードなので495 この記事では、Word文書に赤線を追加する方法を紹介します。ドキュメントのレッドラインとは、ユーザーが変更を明確に確認できるようにドキュメントを変更することを指します。この機能は、複数の人が一緒にドキュメントを編集している場合に非常に重要です。レッドラインの意味 ドキュメントのマーク レッドラインとは、ドキュメントの変更、編集、または改訂を示すために赤い線または吹き出しを使用することを意味します。この用語は、印刷された文書に赤ペンを使用してマークを付ける習慣からインスピレーションを受けました。レッドライン コメントは、ドキュメントの編集時に作成者、編集者、レビュー担当者に推奨される変更を明確に示すなど、さまざまなシナリオで広く使用されています。法的合意や契約の変更や修正を提案する。 論文やプレゼンテーションなどに対して建設的な批評や提案を提供する。 Wの与え方
 字幕なしで映画を見ても心配しないでください。 Xiaomi、日本語と韓国語の翻訳のためのリアルタイム字幕Xiaoai Translationの開始を発表
Jul 22, 2024 pm 02:11 PM
字幕なしで映画を見ても心配しないでください。 Xiaomi、日本語と韓国語の翻訳のためのリアルタイム字幕Xiaoai Translationの開始を発表
Jul 22, 2024 pm 02:11 PM
7月22日のニュースによると、今日、Xiaomi ThePaper OSの公式Weiboは、Xiaoai翻訳が日本語と韓国語の翻訳にアップグレードされ、字幕なしのビデオやライブ会議を文字起こしして翻訳できるようになったと発表しました。リアルタイムで。対面同時通訳では、中国語、英語、日本語、韓国語、ロシア語、ポルトガル語、スペイン語、イタリア語、フランス語、ドイツ語、インドネシア語、ヒンディー語を含む 12 言語への翻訳がサポートされています。上記の機能は現在、次の 3 つの新しい携帯電話のみをサポートしています: Xiaomi MIX Fold 4 Xiaomi MIX Flip Redmi K70 Extreme Edition 2021 年には日本語と韓国語の翻訳に Xiao Ai の AI 字幕が追加される予定であると報告されています。 AI 字幕は、Xiaomi が自社開発した同時通訳技術を使用し、より高速で安定した正確な字幕読み取り体験を提供します。 1. 公式声明によると、Xiaoai Translator はオーディオおよびビデオ会場でのみ使用できるわけではありません
 Huawei 携帯電話にデュアル WeChat ログインを実装するにはどうすればよいですか?
Mar 24, 2024 am 11:27 AM
Huawei 携帯電話にデュアル WeChat ログインを実装するにはどうすればよいですか?
Mar 24, 2024 am 11:27 AM
Huawei 携帯電話にデュアル WeChat ログインを実装するにはどうすればよいですか?ソーシャルメディアの台頭により、WeChatは人々の日常生活に欠かせないコミュニケーションツールの1つになりました。ただし、多くの人は、同じ携帯電話で同時に複数の WeChat アカウントにログインするという問題に遭遇する可能性があります。 Huawei 社の携帯電話ユーザーにとって、WeChat の二重ログインを実現することは難しくありませんが、この記事では Huawei 社の携帯電話で WeChat の二重ログインを実現する方法を紹介します。まず第一に、ファーウェイの携帯電話に付属するEMUIシステムは、デュアルアプリケーションを開くという非常に便利な機能を提供します。アプリケーションのデュアルオープン機能により、ユーザーは同時に
 PHP プログラミング ガイド: フィボナッチ数列を実装する方法
Mar 20, 2024 pm 04:54 PM
PHP プログラミング ガイド: フィボナッチ数列を実装する方法
Mar 20, 2024 pm 04:54 PM
プログラミング言語 PHP は、さまざまなプログラミング ロジックやアルゴリズムをサポートできる、Web 開発用の強力なツールです。その中でも、フィボナッチ数列の実装は、一般的で古典的なプログラミングの問題です。この記事では、PHP プログラミング言語を使用してフィボナッチ数列を実装する方法を、具体的なコード例を添付して紹介します。フィボナッチ数列は、次のように定義される数学的数列です。数列の最初と 2 番目の要素は 1 で、3 番目の要素以降、各要素の値は前の 2 つの要素の合計に等しくなります。シーケンスの最初のいくつかの要素
 Windows 11/10 で Word 文書を開くと空白になる
Mar 11, 2024 am 09:34 AM
Windows 11/10 で Word 文書を開くと空白になる
Mar 11, 2024 am 09:34 AM
Windows 11/10 コンピューターで Word 文書を開くときに空白ページの問題が発生した場合、状況を解決するために修復の実行が必要になる場合があります。この問題の原因はさまざまですが、最も一般的なものの 1 つはドキュメント自体の破損です。さらに、Office ファイルの破損によっても同様の状況が発生する可能性があります。したがって、この記事で提供されている修正が役に立つ可能性があります。いくつかのツールを使用して破損した Word 文書を修復したり、文書を別の形式に変換して再度開いたりすることができます。さらに、システム内の Office ソフトウェアを更新する必要があるかどうかを確認することも、この問題を解決する方法です。これらの簡単な手順に従うことで、Win で Word 文書を開くときに Word 文書が空白になる問題を修正できる可能性があります。
 Huawei携帯電話にWeChatクローン機能を実装する方法
Mar 24, 2024 pm 06:03 PM
Huawei携帯電話にWeChatクローン機能を実装する方法
Mar 24, 2024 pm 06:03 PM
Huawei 携帯電話に WeChat クローン機能を実装する方法 ソーシャル ソフトウェアの人気と人々のプライバシーとセキュリティの重視に伴い、WeChat クローン機能は徐々に人々の注目を集めるようになりました。 WeChat クローン機能を使用すると、ユーザーは同じ携帯電話で複数の WeChat アカウントに同時にログインできるため、管理と使用が容易になります。 Huawei携帯電話にWeChatクローン機能を実装するのは難しくなく、次の手順に従うだけです。ステップ 1: 携帯電話システムのバージョンと WeChat のバージョンが要件を満たしていることを確認する まず、Huawei 携帯電話システムのバージョンと WeChat アプリが最新バージョンに更新されていることを確認します。
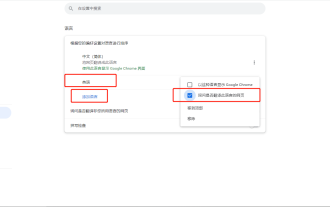 Google Chromeの組み込み翻訳が失敗する問題を解決するにはどうすればよいですか?
Mar 13, 2024 pm 08:46 PM
Google Chromeの組み込み翻訳が失敗する問題を解決するにはどうすればよいですか?
Mar 13, 2024 pm 08:46 PM
ブラウザには翻訳機能が搭載されていることが多いので、外国語のサイトを閲覧しても理解できないという心配はありません! Google Chromeも例外ではありませんが、一部のユーザーは、Google Chromeの翻訳機能を開いたときに、応答がなかったり、失敗したりすることがあります。私が見つけた最新の解決策を試してみてください。操作チュートリアル: 右上隅の 3 つの点をクリックし、[設定] をクリックします。 [言語の追加] をクリックし、英語と中国語を追加し、次の設定を行います。英語の設定では、Web ページをこの言語で翻訳するかどうかを尋ねられます。中国語の設定では、この言語で Web ページが表示されます。中国語はその前に先頭に移動する必要があります。をデフォルトの言語として設定できます。 Web ページを開いて翻訳オプションが表示されない場合は、右クリックして [中国語翻訳] を選択し、[OK] をクリックします。
