

DB2一个基于Cache Table的数据复制方案

IBM 数据库复制产品 Infosphere Replication Server 中的多向 SQL 复制既能捕获源表也能捕获目标表的数据变化,因此能很好地保持数据在各方的一致。
但数据冲突的现象仍是无法完全杜绝。因此我们需要尽可能地改进方案,以期接近完美效果。本文在这样的背景下,介绍了 IBM 相关产品 Infosphere Replication Server 和 Infosphere Federation Server 通过合作提出的一个基于 Cache Table 的数据复制方案。
计算机、网络、传感技术等各项信息技术的发展,使得我们生活的环境变成了今天这个由数据统治的世界,每天都有大量纷繁复杂的数据、信息充斥耳边。据称现在只需两天就能创造出自文明诞生以来到 2003 年所产生的数据总量。而企业数据也以 55% 的速率逐年增长。这些大量的交易数据、交互数据中并不是 100% 都是有意义的,但我们又不得不去接收它们。这是因为数据当中隐含着有价值的信息,并且这些信息都是有时效的,需要及时进行整合、分析、再创造,然后才能更好地与用户交互,实现在合适的时间、通过合适的途径、销售合适的产品,最终实现企业利润增长。数据复制产品正是这一数据处理过程中最关键的一环,它能够将接收到的数据分发到各个场所,用于及时整合数据,产生实时报表,或者为实时统计提供输入。
数据集中 / 分发经典场景
对于集团型企业,例如银行、电信、保险等,通常包含多个子系统,每个系统对应一项或多项业务,而业务终端也往往部署在各个省市地区。某个地区的某个子系统里数据在一定时间内只能代表该地区的业务特征。因此,业务的广泛性和区域性使得企业不能对内部的数据进行全盘规划和统一,这大大影响了企业对业务的分析决策。具体影响有:
- 关键数据不唯一,集团无法判断数据的准确性,需要花费更多的人工和资源验证并纠正数据,因此不能对分公司或子公司的数据进行及时分析,从而进行全盘分析和规划;
- 分公司或子公司间数据无交互或交互较少,各自为政,数据无共享,造成各分公司或子公司间不能有效借鉴或沿用有价值或有代表性的决策和方案,集团范围内数据管理困难,数据丢失的风险性较高。
没有统一的关键数据管理会造成集团范围内不能实时监控并及时分配关键资源,不能及时获取各地数据掌握全局趋势,也往往会造成决策失误。这些问题严重的话会造成企业无法弥补的损失。因此企业通常会建立数据中心、部署一套数据集中 / 分发方案以保证各地各项业务数据的统一。典型场景如图 1 所示,在集团所在地或附近建立中心,在各分公司或子公司部署分级。中心服务器与分级服务器间通过网络实时通信,分发或集中数据。各分级服务期间根据需要也可进行通信。
图 1. 数据集中 / 分发场景

数据集中 / 分发对数据冲突和负载均衡的要求
数据的集中和分发根据实际情况要求和设计考虑的角度的不同,具体实现起来方案有很多。有些由中心服务器承担主要业务输入,有些反之,有些根据具体情况不同,对不同的业务指定不同的主承受服务器。但究其本质是如何保证事务的原子性和数据在各个副本中的一致性。这方面从技术发展历程来看,早期主要通过两阶段提交协议实现原子性,通过两阶段锁或时间戳模型实现副本的一致性。这种模式即为通常所说的同步复制过程,涉及到各副本与提交事务的节点间的互相确认过程,因此具有一定的性能影响。后来为提高吞吐率,缩短响应时间,对一致性级别进行了放松,出现了异步复制,面对不同的目的,出现了不同的异步复制协议。目前企业中使用的复制产品大多为异步复制。这种方案不能像同步复制那样实现完全实时复制,必然会出现一定的延时,虽然这种延时通过各种技术手段可以控制在秒级,甚至更小,但对于在每个副本都能操作数据的系统中,还是有可能出现数据冲突。
数据冲突简单地说,是因为某一行数据在不同地点被不同的应用同时进行了修改。这种修改具体表现有插入、更新、删除。举例来说,有表(列 1,列 2,列 3),其中列 1 是表的主键,该表同时部署在两地的 Server A 和 Server B 中。最普遍的冲突情况是,A 和 B 同时有应用对该表插入了具有相关关键字的数据,该事务在本地服务器上能执行成功,但当数据变化传递到对方时,会发现以这个关键字值标记的行已存在,冲突发生;另一种普遍的冲突是,A 和 B 同时修改了相同关键字行的非关键字列,这样当变化传递到对方时,冲突发生。无论具体冲突是什么情况,在异步复制中都无法完全避免,因此在设计方案时必须要有在发生数据冲突时,一些有效的冲突解决方案,这样才能最终保证数据的一致。
由于业务的多样性,由单个服务器承受所有的业务具有很高的风险性,当出现断电等意外,或者更大的自然灾害时,损失是无法挽回的。因此设计数据集中 / 分发方案时需要考虑如何实现负载均衡。从全局来看,需要合理分配各项业务的连接;从具体业务来看,需要合理均衡读连接和写连接,特别对于具有大用户量的业务,用户对系统响应一般都具有较高的期望,用户量也往往跟系统响应时间负相关,而受限于服务器以及数据库系统的处理能力,单个表是很难满足大量同时的读写连接的。
多向 SQL 复制实现数据集中 / 分发
IBM InfoSphere Replication Server 产品中的 SQL 复制框架最早可以追溯到 1994 年 IBM DB2 发布的 DataPropagator Relational(DPropR)的第一个版本。因此,相较于 2004 年推出的 Q 复制框架,SQL 复制功能的客户基础较深厚,事实证明它在实现数据集中 / 分发方面具有较好的优势和稳定性。本节将带领读者简单回顾一下多向 SQL 复制的实现。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7456
7456
 15
1376
52
77
11
14
10
15
1376
52
77
11
14
10

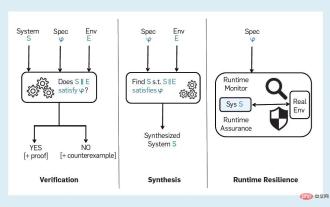 検証可能な AI に向けて: 形式手法の 5 つの課題
Apr 09, 2023 pm 02:01 PM
検証可能な AI に向けて: 形式手法の 5 つの課題
Apr 09, 2023 pm 02:01 PM
人工知能は、人間の知能を模倣しようとするコンピューティング システムであり、学習、問題解決、合理的な思考と行動など、知能に直観的に関連する人間の機能が含まれます。広義に解釈すると、AI という用語は、機械学習などの密接に関連する多くの分野をカバーします。 AI を多用するシステムは、医療、交通、金融、ソーシャル ネットワーク、電子商取引、教育などの分野で社会に大きな影響を与えています。この社会的影響の増大は、人工知能ソフトウェアのエラー、サイバー攻撃、人工知能システムのセキュリティなど、一連のリスクと懸念ももたらしています。したがって、AI システムの検証の問題、および信頼できる AI というより広範なテーマが研究コミュニティの注目を集め始めています。 「検証可能なAI」を確認
 db2 と oracle の構文の違いは何ですか
Jul 05, 2023 am 10:39 AM
db2 と oracle の構文の違いは何ですか
Jul 05, 2023 am 10:39 AM
db2 と oracle の構文の違い: 1. SQL 構文の違い: db2 と oracle は両方とも構造化照会言語を使用しますが、構文にいくつかの違いがあります; 2. db2 と oracle のデータ型は異なります; 3. 外部キー制約の定義、db2 は次のことができます。テーブルの作成時に定義するか、「ALTER TABLE」ステートメントを使用して追加する必要があります。Oracle はテーブルの作成時に一緒に定義する必要があります。4. db2 と oracle のストアド プロシージャおよび関数の構文にもいくつかの違いがあります。
 Java で分散システムにデータ レプリケーションとデータ同期を実装する方法
Oct 09, 2023 pm 06:37 PM
Java で分散システムにデータ レプリケーションとデータ同期を実装する方法
Oct 09, 2023 pm 06:37 PM
Java で分散システムにデータ レプリケーションとデータ同期を実装する方法 分散システムの台頭により、データ レプリケーションとデータ同期はデータの一貫性と信頼性を確保する重要な手段になりました。 Java では、いくつかの一般的なフレームワークとテクノロジを使用して、分散システムでのデータ レプリケーションとデータ同期を実装できます。この記事では、Java を使用して分散システムでデータ レプリケーションとデータ同期を実装する方法を詳しく紹介し、具体的なコード例を示します。 1. データ レプリケーション データ レプリケーションは、あるノードから別のノードにデータをコピーするプロセスです。
 PHP の高同時処理におけるスレッド プール最適化ソリューション
Aug 11, 2023 am 10:45 AM
PHP の高同時処理におけるスレッド プール最適化ソリューション
Aug 11, 2023 am 10:45 AM
PHP のスレッド プール最適化ソリューション 高同時実行処理 インターネットの急速な発展とユーザー ニーズの継続的な増大に伴い、最新の Web アプリケーション開発では高同時実行性が重要な問題となっています。 PHP では、シングルスレッドの性質のため、大量の同時リクエストを処理するのは困難です。この問題を解決するには、スレッド プールの概念を導入することが効果的な最適化ソリューションです。スレッド プールは、多数の同時タスクを実行するために使用される再利用可能なスレッドのコレクションです。その基本的な考え方は、スレッドの作成、破棄、管理を分離し、スレッドを再利用することでスレッドの数を減らすことです。
 MySQL でデータの非同期レプリケーションと遅延レプリケーションを実装するにはどうすればよいですか?
Jul 31, 2023 pm 12:58 PM
MySQL でデータの非同期レプリケーションと遅延レプリケーションを実装するにはどうすればよいですか?
Jul 31, 2023 pm 12:58 PM
MySQL は一般的に使用されるリレーショナル データベース管理システムであり、実際のアプリケーションでは、データ レプリケーションが必要なシナリオによく遭遇します。データ レプリケーションは、同期レプリケーションと非同期レプリケーションの 2 つの形式に分類できます。同期レプリケーションは、マスター データベースがデータを書き込んだ直後にデータをスレーブ データベースにコピーする必要があることを意味しますが、非同期レプリケーションは、マスター データベースがデータを書き込んだ後、コピー前にデータを一定期間遅らせることができることを意味します。この記事では、MySQL でデータの非同期レプリケーションと遅延レプリケーションを実装する方法に焦点を当てます。まず、非同期レプリケーションと遅延レプリケーションを実装するために、
 PHP データベース接続を使用してデータの同期とレプリケーションを実現する方法
Sep 08, 2023 pm 02:54 PM
PHP データベース接続を使用してデータの同期とレプリケーションを実現する方法
Sep 08, 2023 pm 02:54 PM
PHP データベース接続を使用してデータの同期とレプリケーションを実現する方法 多くの Web アプリケーションでは、データの同期とレプリケーションが非常に重要です。たとえば、複数のデータベース サーバーがある場合、ユーザーがアプリケーションにアクセスするときに常に最新のデータを取得できるように、これらのサーバー上のデータが確実に同期されるようにすることができます。幸いなことに、PHP データベース接続を使用すると、データを簡単に同期および複製できます。この記事では、PHP データベース接続を使用してデータの同期とレプリケーションを実現する手順を紹介し、対応するコード例を示します。
 MongoDB のデータ レプリケーションと障害回復メカニズムの詳細な分析
Nov 04, 2023 pm 04:07 PM
MongoDB のデータ レプリケーションと障害回復メカニズムの詳細な分析
Nov 04, 2023 pm 04:07 PM
MongoDB のデータ レプリケーションと障害回復メカニズムの詳細な分析 はじめに: ビッグ データ時代の到来により、データのストレージと管理がますます重要になっています。データベース分野では、MongoDB は広く使用されている NoSQL データベースであり、そのデータ複製と障害回復メカニズムは、データの信頼性と高可用性を確保するために重要です。この記事では、読者がデータベースについてより深く理解できるように、MongoDB のデータ レプリケーションと障害回復メカニズムについて詳しく分析します。 1. MongoDB のデータ複製メカニズム データ複製
 0 しきい値のクローン作成ソリューションがアップグレードされ、オープン ソース モデルが完全に再現され、オンライン エクスペリエンスに登録は必要ありません。
Apr 14, 2023 pm 10:58 PM
0 しきい値のクローン作成ソリューションがアップグレードされ、オープン ソース モデルが完全に再現され、オンライン エクスペリエンスに登録は必要ありません。
Apr 14, 2023 pm 10:58 PM
ChatGPTやGPT4に代表されるAIアプリケーションや大規模モデルは世界中で普及しており、新たな技術産業革命を切り開き、AGI(汎用人工知能)の新たな出発点となると考えられています。テクノロジー大手が新製品の発売を目指して競い合っているだけでなく、学界や産業界の多くのAI大物も関連する起業家精神の波に加わっている。生成 AI は「数日」で急速に反復され、急増し続けています。ただし、OpenAI はオープンソース化していません。その背後にある技術的な詳細は何ですか?このテクノロジーの波に素早く追いつき、追いつき、参加するにはどうすればよいでしょうか?大規模な AI モデルの構築と適用にかかる高額なコストを削減するにはどうすればよいでしょうか?サードパーティの大規模モデル API の使用によるコア データと知的財産の漏洩をどのように保護するか?一番人気としては
