

python编写简单爬虫资料汇总

爬虫真是一件有意思的事儿啊,之前写过爬虫,用的是urllib2、BeautifulSoup实现简单爬虫,scrapy也有实现过。最近想更好的学习爬虫,那么就尽可能的做记录吧。这篇博客就我今天的一个学习过程写写吧。
一 正则表达式
正则表达式是一个很强大的工具了,众多的语法规则,我在爬虫中常用的有:
| . | 匹配任意字符(换行符除外) |
| * | 匹配前一个字符0或无限次 |
| ? | 匹配前一个字符0或1次 |
| .* | 贪心算法 |
| .*? | 非贪心算法 |
| (.*?) | 将匹配到的括号中的结果输出 |
| \d | 匹配数字 |
| re.S | 使得.可以匹配换行符 |
常用的方法有:find_all(),search(),sub()
对以上语法方法做以练习,代码见:https://github.com/Ben0825/Crawler/blob/master/re_test.py
二 urllib和urllib2
urllib和urllib2库是学习Python爬虫最基本的库,利用该库,我们可以得到网页的内容,同时,可以结合正则对这些内容提取分析,得到真正想要的结果。
在此将urllib和urllib2结合正则爬取了糗事百科中的作者点赞数内容。
代码见:https://github.com/Ben0825/Crawler/blob/master/qiubai_test.py
三 BeautifulSoup
BeautifulSoup是Python的一个库,最主要的功能是从网页抓取数据,官方介绍是这样的:
Beautiful Soup 提供一些简单的、python 式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup 自动将输入文档转换为 Unicode 编码,输出文档转换为 utf-8 编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup 就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup 已成为和 lxml、html6lib 一样出色的 python 解释器,为用户灵活地提供不同的解析策略或强劲的速度。
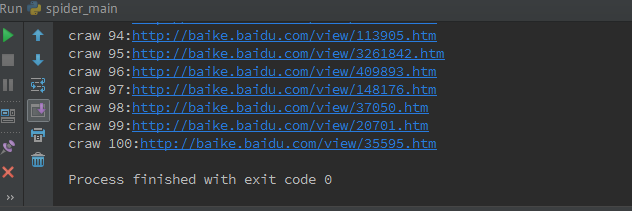
首先:爬取百度百科Python词条下相关的100个页面,爬取的页面值自己设定。
代码详见:https://github.com/Ben0825/Crawler/tree/master/python_baike_Spider
代码运行:
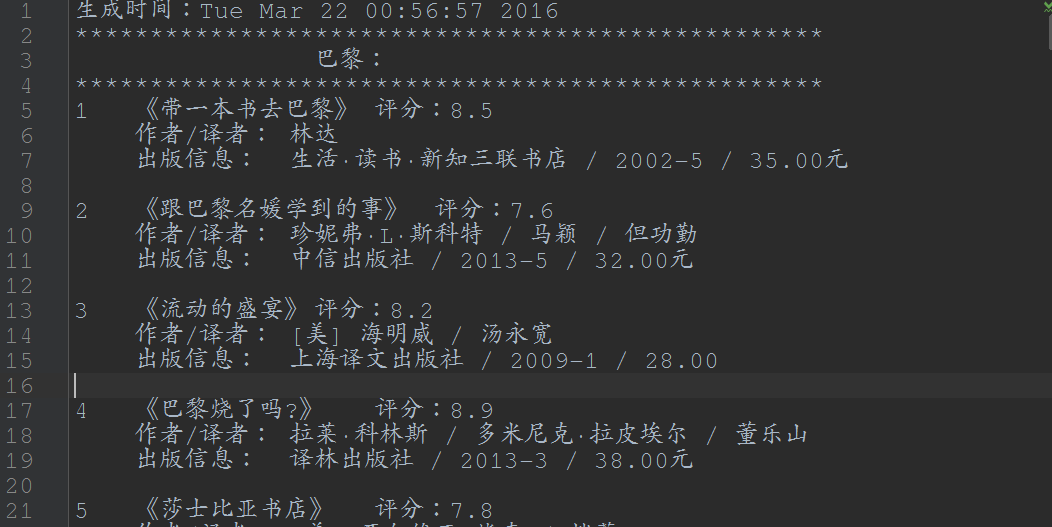
巩固篇,依据豆瓣中图书的标签得到一个书单,同样使用BeautifulSoup。
代码详见:https://github.com/Ben0825/Crawler/blob/master/doubanTag.py
运行结果:
以上就是今天学习的一些内容,爬虫真的很有意思啊,明天继续学scrapy!

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7359
7359
 15
1628
14
1353
52
1265
25
1214
29
15
1628
14
1353
52
1265
25
1214
29

 XML形式を開く方法
Apr 02, 2025 pm 09:00 PM
XML形式を開く方法
Apr 02, 2025 pm 09:00 PM
ほとんどのテキストエディターを使用して、XMLファイルを開きます。より直感的なツリーディスプレイが必要な場合は、酸素XMLエディターやXMLSPYなどのXMLエディターを使用できます。プログラムでXMLデータを処理する場合、プログラミング言語(Pythonなど)やXMLライブラリ(XML.ETREE.ELEMENTTREEなど)を使用して解析する必要があります。
 XML形式を美化する方法
Apr 02, 2025 pm 09:57 PM
XML形式を美化する方法
Apr 02, 2025 pm 09:57 PM
XMLの美化は、合理的なインデンテーション、ラインブレーク、タグ組織など、本質的に読みやすさを向上させています。原則は、XMLツリーを通過し、レベルに応じてインデントを追加し、テキストを含む空のタグとタグを処理することです。 PythonのXML.ETREE.ELEMENTTREEライブラリは、上記の美化プロセスを実装できる便利なchile_xml()関数を提供します。
 XMLの変更にはプログラミングが必要ですか?
Apr 02, 2025 pm 06:51 PM
XMLの変更にはプログラミングが必要ですか?
Apr 02, 2025 pm 06:51 PM
XMLコンテンツを変更するには、ターゲットノードの正確な検出が必要であるため、プログラミングが必要です。プログラミング言語には、XMLを処理するための対応するライブラリがあり、APIを提供して、データベースの運用などの安全で効率的で制御可能な操作を実行します。
 携帯電話用の無料のXMLからPDFツールはありますか?
Apr 02, 2025 pm 09:12 PM
携帯電話用の無料のXMLからPDFツールはありますか?
Apr 02, 2025 pm 09:12 PM
モバイルには、単純で直接無料のXMLからPDFツールはありません。必要なデータ視覚化プロセスには、複雑なデータの理解とレンダリングが含まれ、市場のいわゆる「無料」ツールのほとんどは経験がありません。コンピューター側のツールを使用したり、クラウドサービスを使用したり、アプリを開発してより信頼性の高い変換効果を取得することをお勧めします。
 携帯電話でXMLをPDFに変換するとき、変換速度は高速ですか?
Apr 02, 2025 pm 10:09 PM
携帯電話でXMLをPDFに変換するとき、変換速度は高速ですか?
Apr 02, 2025 pm 10:09 PM
Mobile XMLからPDFへの速度は、次の要因に依存します。XML構造の複雑さです。モバイルハードウェア構成変換方法(ライブラリ、アルゴリズム)コードの品質最適化方法(効率的なライブラリ、アルゴリズムの最適化、キャッシュデータ、およびマルチスレッドの利用)。全体として、絶対的な答えはなく、特定の状況に従って最適化する必要があります。
 携帯電話でXMLをPDFに変換する方法は?
Apr 02, 2025 pm 10:18 PM
携帯電話でXMLをPDFに変換する方法は?
Apr 02, 2025 pm 10:18 PM
携帯電話でXMLをPDFに直接変換するのは簡単ではありませんが、クラウドサービスの助けを借りて実現できます。軽量モバイルアプリを使用してXMLファイルをアップロードし、生成されたPDFを受信し、クラウドAPIで変換することをお勧めします。クラウドAPIはサーバーレスコンピューティングサービスを使用し、適切なプラットフォームを選択することが重要です。 XMLの解析とPDF生成を処理する際には、複雑さ、エラー処理、セキュリティ、および最適化戦略を考慮する必要があります。プロセス全体では、フロントエンドアプリとバックエンドAPIが連携する必要があり、さまざまなテクノロジーをある程度理解する必要があります。
 XMLをPDFに変換できるモバイルアプリはありますか?
Apr 02, 2025 pm 08:54 PM
XMLをPDFに変換できるモバイルアプリはありますか?
Apr 02, 2025 pm 08:54 PM
XMLをPDFに直接変換するアプリケーションは、2つの根本的に異なる形式であるため、見つかりません。 XMLはデータの保存に使用され、PDFはドキュメントを表示するために使用されます。変換を完了するには、PythonやReportLabなどのプログラミング言語とライブラリを使用して、XMLデータを解析してPDFドキュメントを生成できます。
 推奨されるXMLフォーマットツール
Apr 02, 2025 pm 09:03 PM
推奨されるXMLフォーマットツール
Apr 02, 2025 pm 09:03 PM
XMLフォーマットツールは、読みやすさと理解を向上させるために、ルールに従ってコードを入力できます。ツールを選択するときは、カスタマイズ機能、特別な状況の処理、パフォーマンス、使いやすさに注意してください。一般的に使用されるツールタイプには、オンラインツール、IDEプラグイン、コマンドラインツールが含まれます。
