

Python实现将xml导入至excel

最近在使用Testlink时,发现导入的用例是xml格式,且没有合适的工具转成excel格式,xml使用excel打开显示的东西也太多,网上也有相关工具转成csv格式的,结果也不合人意。
那求人不如尔己,自己写一个吧
需要用到的模块有:xml.dom.minidom(python自带)、xlwt
使用版本:
python:2.7.5
xlwt:1.0.0
一、先分析Testlink XML格式:
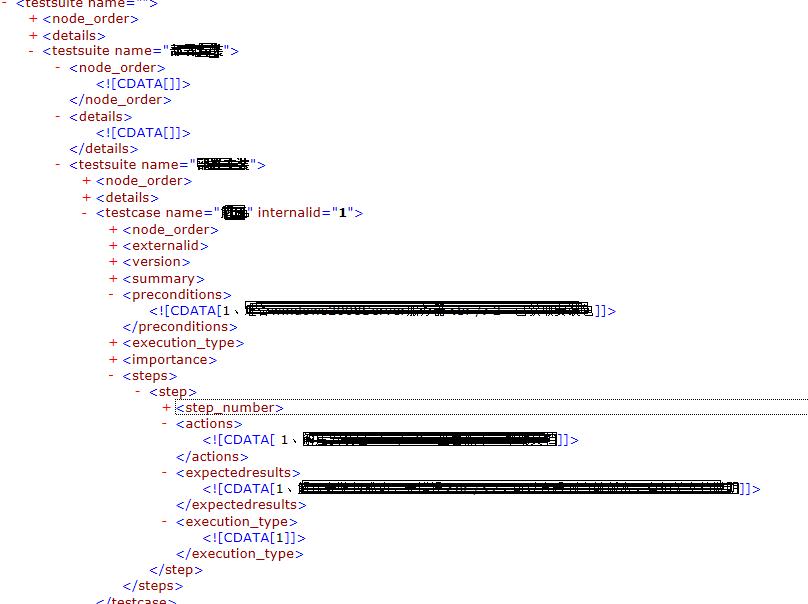
这是一个有两级testusuit的典型的testlink用例结构,我们只需要取testsuite name,testcase name,preconditions,actions,expectedresults
二、程序如下:
#coding:utf-8
'''
Created on 2015-8-20
@author: Administrator
'''
'''
'''
import xml.etree.cElementTree as ET
import xml.dom.minidom as xx
import os,xlwt,datetime
workbook=xlwt.Workbook(encoding="utf-8")
#
booksheet=workbook.add_sheet(u'sheet_1')
booksheet.col(0).width= 5120
booksheet.col(1).width= 5120
booksheet.col(2).width= 5120
booksheet.col(3).width= 5120
booksheet.col(4).width= 5120
booksheet.col(5).width= 5120
dom=xx.parse(r'D:\\Python27\test.xml')
root = dom.documentElement
row=1
col=1
borders=xlwt.Borders()
borders.left=1
borders.right=1
borders.top=1
borders.bottom=1
style = xlwt.easyxf('align: wrap on,vert centre, horiz center') #自动换行、水平居中、垂直居中
#设置标题的格式,字体方宋、加粗、背景色:菊黄
#测试项的标题
title=xlwt.easyxf(u'font:name 仿宋,height 240 ,colour_index black, bold on, italic off; align: wrap on, vert centre, horiz center;pattern: pattern solid, fore_colour light_orange;')
item='测试项'
Subitem='测试分项'
CaseTitle='测试用例标题'
Condition='预置条件'
actions='操作步骤'
Result='预期结果'
booksheet.write(0,0,item,title)
booksheet.write(0,1,Subitem,title)
booksheet.write(0,2,CaseTitle,title)
booksheet.write(0,3,Condition,title)
booksheet.write(0,4,actions,title)
booksheet.write(0,5,Result,title)
#冻结首行
booksheet.panes_frozen=True
booksheet.horz_split_pos= 1
#一级目录
for i in root.childNodes:
testsuite=i.getAttribute('name').strip()
#print testsuite
#print testsuite
'''
写测试项
'''
print "row is :",row
booksheet.write(row,col,testsuite,style)
#二级目录
for dd in i.childNodes:
print " %s" % dd.getAttribute('name')
testsuite2=dd.getAttribute('name')
if not dd.getElementsByTagName('testcase'):
print "Testcase is %s" % testsuite2
row=row+1
booksheet.write(row,2,testsuite2,style) #写测试分项
row=row+1
booksheet.write(row,1,testsuite2,style)
itemlist=dd.getElementsByTagName('testcase')
for subb in itemlist:
#print " %s" % subb.getAttribute('name')
testcase=subb.getAttribute('name')
row=row+1
booksheet.write(row,2,testcase,style)
ilist=subb.getElementsByTagName('preconditions')
for ii in ilist:
preconditions=ii.firstChild.data.replace("<br />"," ")
col=col+1
booksheet.write(row,3,preconditions,style)
steplist=subb.getElementsByTagName('actions')
#print steplist
for step in steplist:
actions=step.firstChild.data.replace("<br />"," ")
col=col+1
booksheet.write(row,4,actions,style)
#print "测试步骤:",steplist[0].firstChild.data.replace("<br />"," ")
expectlist=subb.getElementsByTagName('expectedresults')
for expect in expectlist:
result=expect.childNodes[0].nodeValue.replace("<br />","" )
booksheet.write(row,5,result,style)
row=row+1
workbook.save('demo.xls')写入excel的效果如下:

我们再来看个实例:
需要下载一个module:xlwt,如下是source code
import xml.dom.minidom
import xlwt
import sys
col = 0
row = 0
def handle_xml_report(xml_report, excel):
problems = xml_report.getElementsByTagName("problem")
handle_problems(problems, excel)
def handle_problems(problems, excel):
for problem in problems:
handle_problem(problem, excel)
def handle_problem(problem, excel):
global row
global col
code = problem.getElementsByTagName("code")
file = problem.getElementsByTagName("file")
line = problem.getElementsByTagName("line")
message = problem.getElementsByTagName("message")
for node in code:
excel.write(row, col, node.firstChild.data)
col = col + 1
for node in file:
excel.write(row, col, node.firstChild.data)
col = col + 1
for node in line:
excel.write(row, col, node.firstChild.data)
col = col + 1
for node in message:
excel.write(row, col, node.firstChild.data)
col = col + 1
row = row+1
col = 0
if __name__ == '__main__':
if(len(sys.argv) <= 1):
print ("usage: xml2xls src_file [dst_file]")
exit(0)
#the 1st argument is XML report ; the 2nd is XLS report
if(len(sys.argv) == 2):
xls_report = sys.argv[1][:-3] + 'xls'
#if there are more than 2 arguments, only the 1st & 2nd make sense
else:
xls_report = sys.argv[2]
xmldoc = xml.dom.minidom.parse(sys.argv[1])
wb = xlwt.Workbook()
ws = wb.add_sheet('MOLint')
ws.write(row, col, 'Error Code')
col = col + 1
ws.write(row, col, 'file')
col = col + 1
ws.write(row, col, 'line')
col = col + 1
ws.write(row, col, 'Description')
row = row + 1
col = 0
handle_xml_report(xmldoc, ws)
wb.save(xls_report)

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック



 携帯電話でXMLをPDFに変換するとき、変換速度は高速ですか?
Apr 02, 2025 pm 10:09 PM
携帯電話でXMLをPDFに変換するとき、変換速度は高速ですか?
Apr 02, 2025 pm 10:09 PM
Mobile XMLからPDFへの速度は、次の要因に依存します。XML構造の複雑さです。モバイルハードウェア構成変換方法(ライブラリ、アルゴリズム)コードの品質最適化方法(効率的なライブラリ、アルゴリズムの最適化、キャッシュデータ、およびマルチスレッドの利用)。全体として、絶対的な答えはなく、特定の状況に従って最適化する必要があります。
 携帯電話のXMLファイルをPDFに変換する方法は?
Apr 02, 2025 pm 10:12 PM
携帯電話のXMLファイルをPDFに変換する方法は?
Apr 02, 2025 pm 10:12 PM
単一のアプリケーションで携帯電話でXMLからPDF変換を直接完了することは不可能です。クラウドサービスを使用する必要があります。クラウドサービスは、2つのステップで達成できます。1。XMLをクラウド内のPDFに変換し、2。携帯電話の変換されたPDFファイルにアクセスまたはダウンロードします。
 C言語合計の機能は何ですか?
Apr 03, 2025 pm 02:21 PM
C言語合計の機能は何ですか?
Apr 03, 2025 pm 02:21 PM
C言語に組み込みの合計機能はないため、自分で書く必要があります。合計は、配列を通過して要素を蓄積することで達成できます。ループバージョン:合計は、ループとアレイの長さを使用して計算されます。ポインターバージョン:ポインターを使用してアレイ要素を指し示し、効率的な合計が自己概要ポインターを通じて達成されます。アレイバージョンを動的に割り当てます:[アレイ]を動的に割り当ててメモリを自分で管理し、メモリの漏れを防ぐために割り当てられたメモリが解放されます。
 XMLをPDFに変換できるモバイルアプリはありますか?
Apr 02, 2025 pm 09:45 PM
XMLをPDFに変換できるモバイルアプリはありますか?
Apr 02, 2025 pm 09:45 PM
XML構造が柔軟で多様であるため、すべてのXMLファイルをPDFSに変換できるアプリはありません。 XMLのPDFへのコアは、データ構造をページレイアウトに変換することです。これには、XMLの解析とPDFの生成が必要です。一般的な方法には、ElementTreeなどのPythonライブラリを使用してXMLを解析し、ReportLabライブラリを使用してPDFを生成することが含まれます。複雑なXMLの場合、XSLT変換構造を使用する必要がある場合があります。パフォーマンスを最適化するときは、マルチスレッドまたはマルチプロセスの使用を検討し、適切なライブラリを選択します。
 推奨されるXMLフォーマットツール
Apr 02, 2025 pm 09:03 PM
推奨されるXMLフォーマットツール
Apr 02, 2025 pm 09:03 PM
XMLフォーマットツールは、読みやすさと理解を向上させるために、ルールに従ってコードを入力できます。ツールを選択するときは、カスタマイズ機能、特別な状況の処理、パフォーマンス、使いやすさに注意してください。一般的に使用されるツールタイプには、オンラインツール、IDEプラグイン、コマンドラインツールが含まれます。
 携帯電話でXMLをPDFに変換する方法は?
Apr 02, 2025 pm 10:18 PM
携帯電話でXMLをPDFに変換する方法は?
Apr 02, 2025 pm 10:18 PM
携帯電話でXMLをPDFに直接変換するのは簡単ではありませんが、クラウドサービスの助けを借りて実現できます。軽量モバイルアプリを使用してXMLファイルをアップロードし、生成されたPDFを受信し、クラウドAPIで変換することをお勧めします。クラウドAPIはサーバーレスコンピューティングサービスを使用し、適切なプラットフォームを選択することが重要です。 XMLの解析とPDF生成を処理する際には、複雑さ、エラー処理、セキュリティ、および最適化戦略を考慮する必要があります。プロセス全体では、フロントエンドアプリとバックエンドAPIが連携する必要があり、さまざまなテクノロジーをある程度理解する必要があります。
 XML形式を開く方法
Apr 02, 2025 pm 09:00 PM
XML形式を開く方法
Apr 02, 2025 pm 09:00 PM
ほとんどのテキストエディターを使用して、XMLファイルを開きます。より直感的なツリーディスプレイが必要な場合は、酸素XMLエディターやXMLSPYなどのXMLエディターを使用できます。プログラムでXMLデータを処理する場合、プログラミング言語(Pythonなど)やXMLライブラリ(XML.ETREE.ELEMENTTREEなど)を使用して解析する必要があります。
 XMLを写真に変換する方法
Apr 03, 2025 am 07:39 AM
XMLを写真に変換する方法
Apr 03, 2025 am 07:39 AM
XMLは、XSLTコンバーターまたは画像ライブラリを使用して画像に変換できます。 XSLTコンバーター:XSLTプロセッサとスタイルシートを使用して、XMLを画像に変換します。画像ライブラリ:PILやImageMagickなどのライブラリを使用して、形状やテキストの描画などのXMLデータから画像を作成します。
