

データ構造の観点から見ると、各 in は in_javascript スキルよりもはるかに高速です

Firefox の JS エンジンは、次のコードのような for each 構文をサポートしていると聞きました:
var arr = [10,20,30 ,40, 50];
for each(var k in arr)
console.log(k);
arr 配列の内容を直接走査できます。
FireFox のみがこれをサポートしているため、ほとんどすべての JS コードはこの機能を使用しません。
ただし、ActionScript は本質的に、配列、ベクトル、辞書に関係なく、列挙可能なオブジェクトである限り、for in および for each in をサポートします。
以前は、「each」という単語を入力するのが面倒だったので、いつも使い慣れた for in を使って横断していました。
しかし、今日よく考えてデータ構造の観点から分析してみると、JSであってもASであっても、for inとfor each inでは効率に本質的な違いがあるように感じます。
理由は簡単です。配列は本当の意味での配列ではないからです。
配列の本当の意味は何ですか?もちろん、これは従来の言語で type[] で定義されたデータ型であり、すべての要素が継続的に保存されます。
「配列」は配列という意味もありますが、JS に詳しい人は、これが実際には非線形の擬似配列であり、添え字は任意の数であることを知っています。 arr[1000000] と記述すると、実際には 100 万要素を収容するためのスペースが適用されませんが、1000000 が対応するハッシュ値に変換され、小さな記憶スペースに相当するため、メモリが大幅に節約されます。
たとえば、次のような配列があります:
var arr = [];
arr[10] = 1000;
arr[20] = 2000;
arr[30] = 5000;
arr[40] = 8000;
arr[200] = 9000;
for...in を使用して配列を走査するのは非常に面倒なプロセスです:
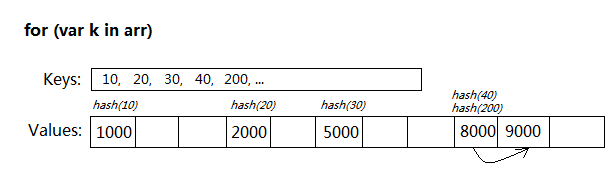
トラバーサル中に arr[k] にアクセスするたびに、ハッシュ テーブルの容量に基づいてモジュロ計算を実行する必要があります。競合がある場合は、最終的な値の結果を見つける必要があります。
for each...in 構文がサポートされている場合、その内部データ構造により、次のようにより高速になることが決定されます:
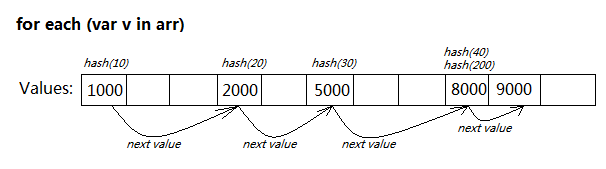
配列では、各値はノードとして直接使用され、リンクされたリストを通じて維持されます。値が追加または削除されるたびに、そのリンク関係が更新されます。
for each...in をトラバースする場合、ハッシュ計算を行わずに、最初のノードから逆方向に反復するだけで済みます。
もちろん、AS3 の Vector などの線形配列の場合、両者に大きな違いはありません。同様に、HTML5 のバイナリ配列 ArrayBuffer にも同じことが当てはまります。ただし、理論的な観点から見ると、たとえ arr が連続線形配列であっても、for each in のほうが高速です:
for...in を走査するとき、arr[k] がアクセスされるたびに、添字が範囲外チェックを実行する必要があり、各 in は内部リンク リストに基づいて反復変数を最下層から直接フィードバックするため、範囲外チェックのプロセスが省略されます。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7650
7650
 15
1392
52
91
11
36
110
15
1392
52
91
11
36
110

 kernel_security_check_failure ブルー スクリーンを解決する 17 の方法
Feb 12, 2024 pm 08:51 PM
kernel_security_check_failure ブルー スクリーンを解決する 17 の方法
Feb 12, 2024 pm 08:51 PM
Kernelsecuritycheckfailure (カーネルチェック失敗) は比較的一般的な停止コードですが、理由が何であれ、ブルースクリーンエラーは多くのユーザーを悩ませます、当サイトでは 17 種類のエラーをユーザーに丁寧に紹介します。 kernel_security_check_failure ブルー スクリーンに対する 17 の解決策 方法 1: すべての外部デバイスを削除する 使用している外部デバイスが Windows のバージョンと互換性がない場合、Kernelsecuritycheckfailure ブルー スクリーン エラーが発生することがあります。これを行うには、コンピュータを再起動する前に、すべての外部デバイスを取り外しておく必要があります。
 Win10 で Skype for Business をアンインストールするにはどうすればよいですか?コンピューターから Skype を完全にアンインストールする方法
Feb 13, 2024 pm 12:30 PM
Win10 で Skype for Business をアンインストールするにはどうすればよいですか?コンピューターから Skype を完全にアンインストールする方法
Feb 13, 2024 pm 12:30 PM
Win10 Skype はアンインストールできますか? 多くのユーザーは、このアプリケーションがコンピューターの既定のプログラムに含まれており、削除するとシステムの動作に影響するのではないかと心配しているため、これは多くのユーザーが知りたい質問です。この Web サイトはユーザーを支援します。Win10 で Skype for Business をアンインストールする方法を詳しく見てみましょう。 Win10 で Skype for Business をアンインストールする方法 1. コンピューターのデスクトップで Windows アイコンをクリックし、設定アイコンをクリックしてに入ります。 2. 「適用」をクリックします。 3. 検索ボックスに「Skype」と入力し、見つかった結果をクリックして選択します。 4. 「アンインストール」をクリックします。 5
 JavaScript で for を使用して n の階乗を求める方法
Dec 08, 2021 pm 06:04 PM
JavaScript で for を使用して n の階乗を求める方法
Dec 08, 2021 pm 06:04 PM
for を使用して n 階乗を求める方法: 1. 「for (var i=1;i<=n;i++){}」ステートメントを使用して、ループの走査範囲を「1~n」に制御します; 2. ループ内body, use "cj *=i" 1からnまでの数値を掛けて変数cjに代入; 3. ループ終了後、変数cjの値をnの階乗にして出力します。
 foreach と for ループの違いは何ですか
Jan 05, 2023 pm 04:26 PM
foreach と for ループの違いは何ですか
Jan 05, 2023 pm 04:26 PM
違い: 1. for はインデックスを介して各データ要素をループしますが、forEach は JS の基礎となるプログラムを介して配列のデータ要素をループします; 2. for はbreak キーワードを使用してループの実行を終了できますが、forEach はそれができません; 3 . forはループ変数の値を制御することでループの実行を制御できるが、forEachはできない; 4. forはループ外でループ変数を呼び出すことができるが、forEachはループ外でループ変数を呼び出すことができない; 5. forの実行効率forEach よりも高いです。
 Python の一般的なフロー制御構造は何ですか?
Jan 20, 2024 am 08:17 AM
Python の一般的なフロー制御構造は何ですか?
Jan 20, 2024 am 08:17 AM
Python の一般的なフロー制御構造は何ですか? Python では、フロー制御構造はプログラムの実行順序を決定するために使用される重要なツールです。これらを使用すると、さまざまな条件に基づいてさまざまなコード ブロックを実行したり、コード ブロックを繰り返し実行したりできます。以下では、Python の一般的なプロセス制御構造を紹介し、対応するコード例を示します。条件ステートメント (if-else): 条件ステートメントを使用すると、さまざまな条件に基づいてさまざまなコード ブロックを実行できます。基本的な構文は次のとおりです: if 条件 1: #when 条件
 JAVAの単純なforループで例外を回避するにはどうすればよいですか?
Apr 26, 2023 pm 12:58 PM
JAVAの単純なforループで例外を回避するにはどうすればよいですか?
Apr 26, 2023 pm 12:58 PM
はじめに 実際のビジネスプロジェクト開発において、与えられたリストから条件を満たさない要素を削除するという操作は誰でも経験があるのではないでしょうか?多くの学生はそれを達成するためのさまざまな方法をすぐに思いつくことができますが、あなたが考えるすべての方法は人体や動物に無害ですか?一見普通に見える操作の多くは実は罠であり、多くの初心者は注意しないと罠に陥る可能性があります。残念ながら、コードの実行中に例外がスローされ、エラーが報告された場合は幸いですが、少なくともエラーは報告されずにコードが発見され、時間内に解決されますが、ビジネス ロジックでは不可解なさまざまな奇妙な問題が発生します。この問題に注意を払わないと、その後のビジネスに隠れた危険が生じる可能性があるため、これはさらに悲劇的です。では、実装方法にはどのようなものがあるのでしょうか?どのような実装が考えられるか
 6 つの例、8 つのコード スニペット、Python の For ループの詳細な説明
Apr 11, 2023 pm 07:43 PM
6 つの例、8 つのコード スニペット、Python の For ループの詳細な説明
Apr 11, 2023 pm 07:43 PM
Python は for ループをサポートしており、その構文は他の言語 (JavaScript や Java など) とは若干異なります。次のコード ブロックは、Python で for ループを使用してリスト内の要素を反復処理する方法を示しています。 上記のコード スニペットは、3 つの文字を別々の行に出力します。 print文の後にカンマ「,」を追加することで出力を同じ行に制限することができます(印刷する文字数を多く指定すると「折り返されます」)。コードは次のとおりです。複数行ではなく 1 行でテキスト コンテンツの場合は、上記の形式のコードを使用できます。 Python には組み込み機能も用意されています
 Go 言語の for ループを使用して、flip 関数をすばやく実装します。
Mar 25, 2024 am 10:45 AM
Go 言語の for ループを使用して、flip 関数をすばやく実装します。
Mar 25, 2024 am 10:45 AM
Go 言語を使用した反転関数の実装は、for ループを通じて非常に迅速に実装できます。フリップ関数は、文字列または配列内の要素の順序を反転するもので、文字列の反転、配列要素の反転など、多くのシナリオに適用できます。 Go言語のforループを使って文字列や配列の反転機能を実現する方法を、具体的なコード例を添えて見てみましょう。文字列の反転: packagemainimport("fmt")fun
