

皆さんこんにちは、私は Luga です。今日は人工知能 (AI) の生態分野に関連するテクノロジー、つまり LLM 評価について話します。
ご存知のとおり、LLM 評価は人工知能の分野で重要なトピックです。 LLM がさまざまなシナリオで広く使用されるようになるにつれて、その機能と制限を評価することがますます重要になります。 ArthurBench は、新興の LLM 評価ツールとして、AI 研究者と開発者に包括的で公平かつ再現可能な評価プラットフォームを提供することを目指しています。

近年、大規模言語モデル (LLM) の急速な開発と改善により、従来のテキスト評価手法はいくつかの側面で適用できなくなる可能性があります。テキスト評価の分野では、BLEU などの「単語の出現」に基づく評価方法や、BERTScore などの「事前学習済みの自然言語処理モデル」に基づく評価方法など、いくつかの方法を聞いたことがあるかもしれません。 これらの新しい評価方法により、テキストの品質と関連性をより正確に評価できるようになります。たとえば、BLEU 評価方法は標準語の出現度に基づいて翻訳品質を評価しますが、BERTScore 評価方法は、自然言語文処理をシミュレートする事前トレーニングされた自然言語処理モデルの能力に基づいてテキストの関連性を評価します。 これらの新しい評価方法は、従来の方法の問題点のいくつかをある程度解決し、より高い柔軟性と精度を備えています。ただし、言語モデルの継続的な開発と改善により、これらの方法は過去には非常に優れていましたが、LLM のエコロジー技術が発展し続けるにつれて、それらは少し不十分であり、現在のニーズを完全に満たすことができないことが示されています。
LLM の急速な発展と改善に伴い、私たちは新たな課題と機会に直面しています。 LLM の機能とパフォーマンス レベルは向上し続けており、BLEU などの単語の出現ベースの評価方法では、LLM で生成されたテキストの品質と意味の正確さを完全に把握できない可能性があります。 LLM は、より流動的で一貫性があり、意味的に豊かなテキストを生成します。これは、従来の単語出現ベースの評価方法では正確に測定できない利点です。
事前トレーニングされたモデル (BERTScore など) の評価方法は、特定のタスクを扱うときにいくつかの課題に直面する可能性があります。事前トレーニングされたモデルは多くのタスクで良好なパフォーマンスを発揮しますが、LLM の固有の特性と特定のタスクでのパフォーマンスが完全には考慮されていない可能性があります。したがって、事前トレーニングされたモデルに基づく評価方法のみに依存すると、LLM の機能を完全に評価できない可能性があります。
2. LLM ガイダンス評価が必要な理由とそれがもたらす課題
1. 効率的です
2. 感度
前に説明したように、LLM 評価者は他の評価方法と比較してより敏感です。 LLM をエバリュエーターとして構成するにはさまざまな方法があり、その動作は選択した構成に応じて大きく異なります。一方、別の課題は、評価に含まれる推論ステップが多すぎる場合、または同時に処理する変数が多すぎる場合に、LLM 評価者が行き詰まってしまう可能性があることです。
LLMの特性により、その評価結果は、異なる構成やパラメータ設定によって影響を受ける可能性があります。つまり、LLM を評価するときは、期待どおりに動作するようにモデルを慎重に選択し、構成する必要があります。構成が異なると出力結果も異なる場合があるため、評価者は、正確で信頼性の高い評価結果を得るために、ある程度の時間と労力をかけて LLM の設定を調整および最適化する必要があります。
さらに、評価者は、複雑な推論や複数の変数の同時処理を必要とする評価タスクに直面すると、いくつかの課題に直面する可能性があります。これは、複雑な状況を扱う場合、LLM の推論能力が制限される可能性があるためです。 LLM は、評価の正確さと信頼性を確保するために、これらのタスクに対処するための追加の努力を必要とする場合があります。
Arthur Bench は、生成テキスト モデル (LLM) のパフォーマンスを比較するために使用されるオープンソースの評価ツールです。これを使用して、さまざまな LLM モデル、キュー、ハイパーパラメーターを評価し、さまざまなタスクでの LLM パフォーマンスに関する詳細なレポートを提供できます。
Arthur Bench の主な機能は次のとおりです:
一般的に、Arthur Bench のワークフローには主に次の段階が含まれており、詳細な分析は次のとおりです:
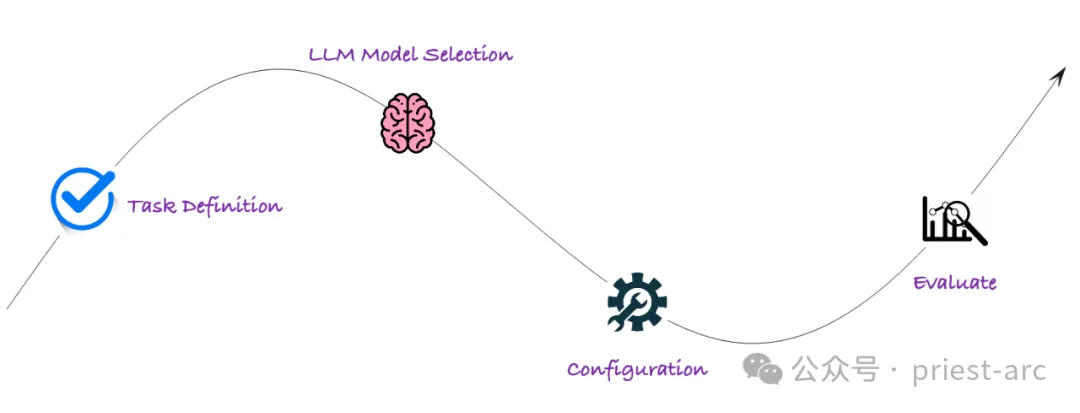
この段階では、Arthur Bench のサポートを明確にする必要があります。複数 以下を含むさまざまな評価タスク。
この段階では、主な作業は評価対象の選択です。 Arthur Bench は、GPT-3、LaMDA、Megatron-Turing NLG など、OpenAI、Google AI、Microsoft などの有名な機関の最先端テクノロジーをカバーする、さまざまな LLM モデルをサポートしています。研究のニーズに基づいて、評価用の特定のモデルを選択できます。
モデルの選択が完了したら、次のステップは詳細な制御を実行することです。 LLM パフォーマンスをより正確に評価するために、Arthur Bench ではユーザーがヒントとハイパーパラメーターを構成できるようにしています。
洗練された構成を通じて、さまざまなパラメータ設定の下での LLM のパフォーマンスの違いを深く調査し、より多くの参考値を含む評価結果を得ることができます。
最後のステップは、自動プロセスを使用してタスクの評価を実行することです。通常、Arthur Bench は、評価タスクを実行するための簡単な構成を必要とする自動評価プロセスを提供します。次の手順が自動的に実行されます:
高速なデータ駆動型 LLM 評価の鍵として、Arthur Bench は主に以下のソリューションを提供します:
 Arthur Bench は専門知識と経験を活用して各 LLM オプションを評価し、その長所と短所を比較するために一貫した指標が使用されるようにします。同氏は、企業が情報に基づいた明確な選択を行えるように、モデルのパフォーマンス、精度、速度、リソース要件などの要素を考慮します。
Arthur Bench は専門知識と経験を活用して各 LLM オプションを評価し、その長所と短所を比較するために一貫した指標が使用されるようにします。同氏は、企業が情報に基づいた明確な選択を行えるように、モデルのパフォーマンス、精度、速度、リソース要件などの要素を考慮します。
一貫した指標と評価方法を使用することで、Arthur Bench は企業に信頼できる比較フレームワークを提供し、企業が各 LLM オプションのメリットと制限を完全に評価できるようにします。これにより、企業は情報に基づいた意思決定を行い、人工知能の急速な進歩を最大限に活用し、アプリケーションで可能な限り最高のエクスペリエンスを保証できるようになります。
2. 予算とプライバシーの最適化
この予算最適化アプローチは、企業が限られたリソースで賢明な選択を行うのに役立ちます。最も高価なモデルや最先端のモデルを選ぶのではなく、特定のニーズに基づいて適切なモデルを選択してください。より手頃な価格のモデルは、いくつかの面で最先端の LLM よりもパフォーマンスが若干劣る可能性がありますが、一部の単純なタスクや標準的なタスクについては、Arthur Bench が依然としてニーズを満たすソリューションを提供できます。
さらに、Arthur Bench 氏は、このモデルを社内に導入することで、データ プライバシーをより適切に制御できると強調しました。機密データやプライバシー問題を伴うアプリケーションの場合、企業は外部のサードパーティ LLM に依存するのではなく、内部でトレーニングされた独自のモデルを使用することを好む場合があります。内部モデルを使用することで、企業はデータの処理と保存をより詳細に制御し、データのプライバシーをより適切に保護できます。
学術的なベンチマークとは、学術研究で確立されたモデルの評価指標と手法を指します。これらの指標と手法は通常、特定のタスクまたはドメインに固有であり、そのタスクまたはドメインにおけるモデルのパフォーマンスを効果的に評価できます。
ただし、学術的なベンチマークは、現実世界におけるモデルのパフォーマンスを必ずしも直接反映するとは限りません。これは、現実世界のアプリケーション シナリオはより複雑であることが多く、データ分散、モデル展開環境など、より多くの要素を考慮する必要があるためです。
Arthur Bench は、学術的なベンチマークを現実世界のパフォーマンスに変換するのに役立ちます。 この目標は次の方法で達成されます:
高速なデータ主導型 LLM 評価の鍵として、Arthur Bench には次の機能があります:
Arthur Bench には完全なスコアリング セットがあります。品質のあらゆる側面の要約からユーザーエクスペリエンスまですべてをカバーする指標。これらのスコアリング指標をいつでも使用して、さまざまなモデルを評価および比較できます。これらのスコア指標を組み合わせて使用すると、各モデルの長所と短所を完全に理解するのに役立ちます。
これらのスコア指標の範囲は非常に広く、要約の品質、正確さ、流暢さ、文法の正しさ、文脈理解能力、論理的一貫性などが含まれますが、これらに限定されません。 Arthur Bench は、これらの指標に照らして各モデルを評価し、その結果を総合的なスコアに結合して、企業が情報に基づいた意思決定を行えるように支援します。
さらに、企業に特定のニーズや懸念事項がある場合、Arthur Bench は企業の要件に基づいてカスタム スコアリング指標を作成および追加することもできます。これは、企業固有のニーズをより適切に満たし、評価プロセスが企業の目標および基準と一致していることを確認するために行われます。
ローカル展開と自律制御を希望する場合は、GitHub リポジトリからアクセスして、Arthur Bench を独自のローカル環境に展開できます。このようにして、誰もが Arthur Bench の操作を完全に習得および制御し、自分のニーズに応じてカスタマイズおよび構成することができます。
一方で、利便性と柔軟性を好むユーザーのために、クラウドベースの SaaS 製品も提供されています。クラウド経由で Arthur Bench にアクセスして使用するために登録することを選択できます。この方法により、ローカルでの面倒なインストールや設定が不要となり、提供される機能やサービスをすぐに利用することができます。
オープンソース プロジェクトとして、Arthur Bench は透明性、スケーラビリティ、コミュニティ コラボレーションの点で典型的なオープンソースの特徴を示します。このオープンソースの性質は、プロジェクトがどのように機能するかをより深く理解し、ニーズに合わせてカスタマイズおよび拡張するための豊富な利点と機会をユーザーに提供します。同時に、Arthur Bench のオープン性は、ユーザーがコミュニティのコラボレーションに積極的に参加し、他のユーザーと協力して開発することも奨励します。このオープンな協力モデルは、プロジェクトの継続的な開発と革新を促進すると同時に、ユーザーにとってより大きな価値と機会を生み出します。
つまり、Arthur Bench は、ユーザーが評価指標をカスタマイズできるオープンで柔軟なフレームワークを提供し、金融分野で広く使用されています。アマゾン ウェブ サービスおよび Cohere とのパートナーシップによりフレームワークがさらに進化し、開発者が Bench 用の新しいメトリクスを作成し、言語モデル評価の分野の進歩に貢献することが奨励されます。
参考:
以上がArthur Bench LLM 評価フレームワークを 1 つの記事で理解するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



