

正確なオブジェクト検出のためのマルチグリッド冗長境界ボックス注釈

1. はじめに
現在の主要なオブジェクト検出器は、深層 CNN のバックボーン分類器ネットワークを再利用した 2 段階または 1 段階のネットワークです。 YOLOv3 は、入力画像を受け取り、それを等しいサイズのグリッド マトリックスに分割する、よく知られた最先端の 1 段階検出器の 1 つです。ターゲット中心を持つグリッド セルは、特定のターゲットの検出を担当します。
今日私たちが共有したのは、正確なタイトフィットバウンディングボックス予測を達成するために各ターゲットに複数のグリッドを割り当てる新しい数学的手法を提案することです。研究者らはまた、ターゲット検出のための効果的なオフラインのコピーアンドペーストデータ拡張も提案しました。新しく提案された方法は、現在の最先端の物体検出器の一部よりも大幅に性能が優れており、より優れたパフォーマンスが期待されます。
2. 背景
物体検出ネットワークは、画像上の物体の位置を特定し、高精度の境界ボックスを使用して正確にラベルを付けるように設計されています。最近、これを達成するための 2 つの異なる方法が登場しました。最初の方法はパフォーマンスの点で、最も重要な方法は 2 段階の物体検出です。最も代表的なのは、地域畳み込みニューラル ネットワーク (RCNN) とその派生です [高速な R-CNN: 地域提案ネットワークによるリアルタイムの物体検出に向けて]。 ]、[高速 R-CNN]。対照的に、2 番目のオブジェクト検出実装グループは、優れた検出速度と軽量さで知られており、シングルステージ ネットワークと呼ばれます。代表的な例としては、[You Only Look Once: 統合されたリアルタイムのオブジェクト検出]、[SSD:シングルショット マルチボックス検出器]、[密集物体検出のための焦点損失]。 2 段階のネットワークは、対象のオブジェクトを含む可能性のある画像の候補領域を生成する潜在領域提案ネットワークに依存しています。このネットワークによって生成された候補領域には、オブジェクトの対象領域が含まれる場合があります。単一ステージのオブジェクト検出では、検出は完全な前方パスで分類および位置特定と同時に処理されます。したがって、通常、単一ステージのネットワークは軽量で高速で、実装が容易です。

今日の研究は依然としてYOLO手法、特にYOLOv3に準拠しており、複数のネットワークユニット要素を同時に使用してターゲットの座標、カテゴリ、およびターゲットの信頼度を予測できる簡単なハックを提案しています。オブジェクトごとに複数のネットワーク単位要素を使用する背後にある理論的根拠は、複数の単位要素が同じオブジェクト上で動作するようにすることで、厳密に適合する境界ボックスを予測する可能性を高めることです。

マルチグリッド割り当てのいくつかの利点は次のとおりです:
オブジェクト検出器は、オブジェクトのクラスを予測するために 1 つのグリッド セルだけに依存するのではなく、検出しているオブジェクトのマルチビュー マップを提供します。コーディネート。
(b+) ランダムで不確実なバウンディングボックス予測が少なくなります。これは、近くのネットワークユニットが同じオブジェクトカテゴリと座標を予測するように訓練されているため、高精度と再現率を意味します。
(c) グリッドセル間の不均衡を軽減します。対象オブジェクトと対象オブジェクトのないグリッド セル。
さらに、マルチグリッド割り当ては既存のパラメータの数学的利用であり、追加のキーポイント プーリング レイヤーやキーポイントを CenterNet や CornerNet などの対応するターゲットに再結合するための後処理を必要としないため、これは、アンカーフリーまたはキーポイントベースのオブジェクト検出器が達成しようとしていることを実現する、より自然な方法です。マルチグリッドの冗長注釈に加えて、研究者らは、正確な物体検出のための新しいオフラインのコピー&ペーストベースのデータ拡張技術も導入しました。
3. マルチグリッド割り当て

上の写真には、犬、自転車、車という 3 つのターゲットが含まれています。簡潔にするために、1 つのオブジェクトに対するマルチグリッドの割り当てについて説明します。上の画像は 3 つのオブジェクトの境界ボックスを示しており、犬の境界ボックスの詳細が示されています。下の画像は、犬の境界ボックスの中心に焦点を当てた、上の画像のズームアウト領域を示しています。犬の境界ボックスの中心を含むグリッド セルの左上の座標には数値 0 のラベルが付けられ、中心を含むグリッドを囲む他の 8 つのグリッド セルには 1 から 8 のラベルが付けられます。

これまで、オブジェクトの境界ボックスの中心を含むメッシュがオブジェクトにどのように注釈を付けるかについての基本的な事実を説明してきました。カテゴリと正確にぴったりとフィットする境界ボックスを予測するという困難な作業をオブジェクトごとに 1 つのグリッド セルのみに依存することにより、次のような多くの問題が生じます。オブジェクト中心のグリッド座標がない
(b) GTへのバウンディングボックスの収束が遅い
(c) 予測されるオブジェクトのマルチアングル(角度)ビューの欠如。
そこで、ここで当然の疑問が生じます。「明らかに、ほとんどのオブジェクトには複数のグリッド セルの領域が含まれています。そこで、オブジェクトのカテゴリと座標を予測するために、これらのグリッド セルをさらに割り当てる簡単な数学的方法はありますか?」中央のグリッドセルと一緒に?」この利点としては、(a) 不均衡が軽減されること、(b) 複数のグリッド セルが同じオブジェクトを同時にターゲットにするため、境界ボックスに収束するためのトレーニングが高速化されること、(c) 緊密に適合する境界ボックスの予測が増加することが挙げられます。オブジェクトの単一点ビューではなくマルチビュー ビューを備えた YOLOv3 などのベースの検出器。新しく提案されたマルチグリッド割り当ては、上記の質問に答えることを試みます。
グラウンドトゥルースエンコーディング
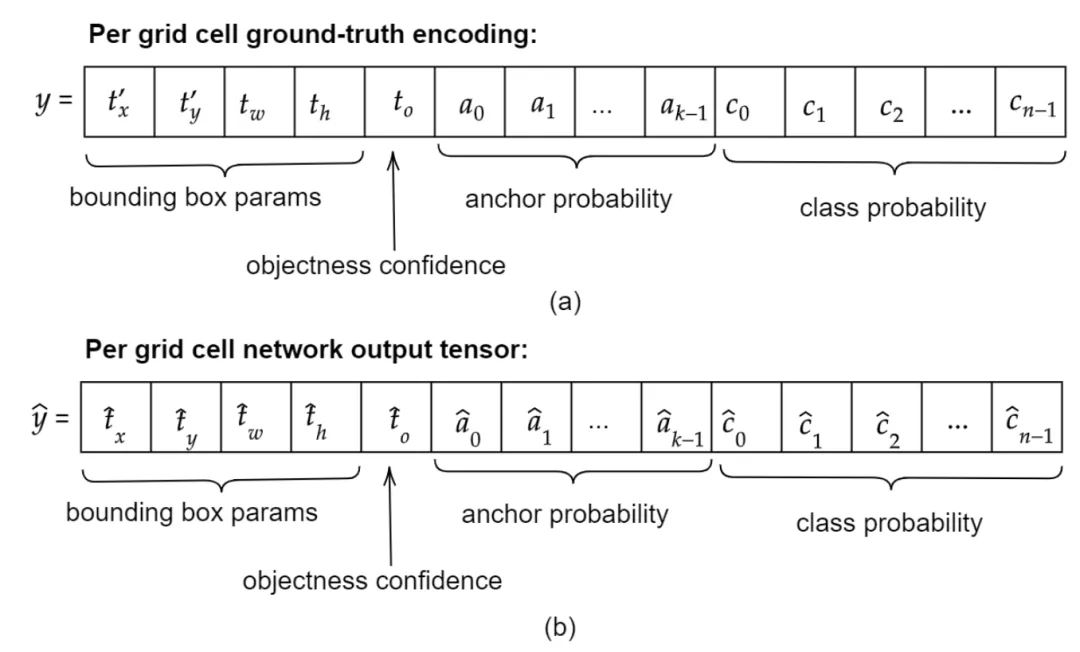
IV. トレーニング
A. 検出ネットワーク: MultiGridDet
YOLOv3 Convo から 6 つのダークネットを削除ソリューションブロックを使用して軽量化と高速化を実現します。畳み込みブロックには Conv2D+Batch Normalization+LeakyRelu があります。削除されたブロックは、分類バックボーン、つまり Darknet53 からのものではありません。代わりに、3 つのマルチスケール検出出力ネットワークまたはヘッドから、各出力ネットワークから 2 つずつ、それらを削除します。一般に、深いネットワークは良好なパフォーマンスを発揮しますが、深すぎるネットワークはすぐにオーバーフィットしたり、ネットワークの速度が大幅に低下したりする傾向があります。
B. 損失関数
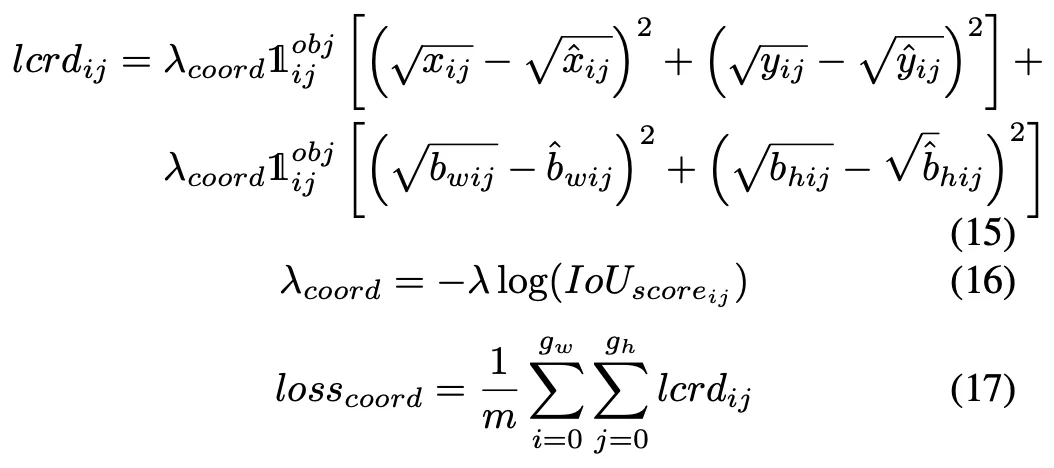
手動トレーニング画像合成の機能以下のように: まず、単純な画像検索スクリプトを使用して、ランドマーク、雨、森林などのキーワードを使用して、Google 画像から背景オブジェクトのない画像、つまり、関心のあるオブジェクトのない画像を何千枚もダウンロードします。次に、トレーニング データセット全体のランダムな q 個の画像から p 個のオブジェクトとその境界ボックスを繰り返し選択します。次に、インデックスを ID として使用して選択された p 個の境界ボックスの可能なすべての組み合わせを生成します。結合されたセットから、次の 2 つの条件を満たす境界ボックスのサブセットを選択します:
ランダムな順序で並べた場合、指定されたターゲット背景画像領域内に収まる必要があり、
オブジェクトが重なり合うことなく、背景画像空間全体または少なくともその大部分を効率的に利用します
- 図からわかるように、最初の行は 6 つを示しています。入力画像、2 行目は非最大値抑制 (NMS) 前のネットワークを示しています。最後の行は、NMS 後の入力画像に対する MultiGridDet の最終バウンディング ボックス予測を示しています。
以上が正確なオブジェクト検出のためのマルチグリッド冗長境界ボックス注釈の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1664
1664
 14
1422
52
1316
25
1267
29
1239
24
14
1422
52
1316
25
1267
29
1239
24

 正確なオブジェクト検出のためのマルチグリッド冗長境界ボックス注釈
Jun 01, 2024 pm 09:46 PM
正確なオブジェクト検出のためのマルチグリッド冗長境界ボックス注釈
Jun 01, 2024 pm 09:46 PM
1. はじめに 現在、主要なオブジェクト検出器は、深層 CNN のバックボーン分類器ネットワークを再利用した 2 段階または 1 段階のネットワークです。 YOLOv3 は、入力画像を受け取り、それを等しいサイズのグリッド マトリックスに分割する、よく知られた最先端の 1 段階検出器の 1 つです。ターゲット中心を持つグリッド セルは、特定のターゲットの検出を担当します。今日私が共有するのは、各ターゲットに複数のグリッドを割り当てて正確なタイトフィット境界ボックス予測を実現する新しい数学的手法です。研究者らはまた、ターゲット検出のための効果的なオフラインのコピー&ペーストデータの強化も提案しました。新しく提案された方法は、現在の最先端の物体検出器の一部よりも大幅に性能が優れており、より優れたパフォーマンスが期待されます。 2. バックグラウンドターゲット検出ネットワークは、次のように設計されています。
 ターゲット検出用の新しい SOTA: YOLOv9 が登場し、新しいアーキテクチャにより従来の畳み込みが復活します
Feb 23, 2024 pm 12:49 PM
ターゲット検出用の新しい SOTA: YOLOv9 が登場し、新しいアーキテクチャにより従来の畳み込みが復活します
Feb 23, 2024 pm 12:49 PM
ターゲット検出の分野では、YOLOv9 は実装プロセスで進歩を続けており、新しいアーキテクチャとメソッドを採用することにより、従来の畳み込みのパラメータ利用を効果的に改善し、そのパフォーマンスが前世代の製品よりもはるかに優れています。 2023 年 1 月に YOLOv8 が正式にリリースされてから 1 年以上が経過し、ついに YOLOv9 が登場しました。 2015 年に Joseph Redmon 氏や Ali Farhadi 氏らが第 1 世代の YOLO モデルを提案して以来、ターゲット検出分野の研究者たちはそれを何度も更新し、反復してきました。 YOLO は画像のグローバル情報に基づく予測システムであり、そのモデルのパフォーマンスは継続的に強化されています。アルゴリズムとテクノロジーを継続的に改善することにより、研究者は目覚ましい成果を上げ、ターゲット検出タスクにおける YOLO をますます強力にしています。
 iPhoneでカメラグリッドを設定する手順
Mar 26, 2024 pm 07:21 PM
iPhoneでカメラグリッドを設定する手順
Mar 26, 2024 pm 07:21 PM
1. iPhone のデスクトップを開き、[設定] を見つけてクリックして入力します。 2. 設定ページでクリックして [カメラ] に入ります。 3. [グリッド]の右側にあるスイッチをクリックしてオンにします。
 C++ を使用して高性能の画像追跡とターゲット検出を行うにはどうすればよいですか?
Aug 26, 2023 pm 03:25 PM
C++ を使用して高性能の画像追跡とターゲット検出を行うにはどうすればよいですか?
Aug 26, 2023 pm 03:25 PM
C++ を使用して高性能の画像追跡とターゲット検出を行うにはどうすればよいですか?要約: 人工知能とコンピュータビジョン技術の急速な発展に伴い、画像追跡とターゲット検出が重要な研究分野となっています。この記事では、C++ 言語といくつかのオープンソース ライブラリを使用して、高性能の画像追跡とターゲット検出を実現する方法を紹介し、コード例を示します。はじめに: 画像追跡と物体検出は、コンピューター ビジョンの分野における 2 つの重要なタスクです。ビデオ監視、自動運転、高度道路交通システムなど、さまざまな分野で広く使用されています。のために
 複数のSOTA! OV-Uni3DETR: カテゴリ、シーン、モダリティにわたる 3D 検出の汎用性の向上 (清華大学および HKU)
Apr 11, 2024 pm 07:46 PM
複数のSOTA! OV-Uni3DETR: カテゴリ、シーン、モダリティにわたる 3D 検出の汎用性の向上 (清華大学および HKU)
Apr 11, 2024 pm 07:46 PM
この論文では、3D オブジェクト検出の分野、特に Open-Vocabulary の 3D オブジェクト検出について説明します。従来の 3D オブジェクト検出タスクでは、システムは実際のシーン内のオブジェクトの 3D 境界ボックスとセマンティック カテゴリ ラベルの位置を予測する必要があり、通常は点群または RGB イメージに依存します。 2D 物体検出テクノロジはその普及性と速度により優れたパフォーマンスを発揮しますが、関連する調査によると、3D ユニバーサル検出の開発はそれに比べて遅れをとっています。現在、ほとんどの 3D オブジェクト検出方法は依然として完全教師あり学習に依存しており、特定の入力モード下で完全に注釈が付けられたデータによって制限されており、屋内シーンか屋外シーンかにかかわらず、トレーニング中に出現するカテゴリのみを認識できます。この論文では、3D ユニバーサル ターゲット検出が直面する課題は主に次のとおりであると指摘しています。
 CSS レイアウトのヒント: 円形グリッド アイコン レイアウトを実装するためのベスト プラクティス
Oct 20, 2023 am 10:46 AM
CSS レイアウトのヒント: 円形グリッド アイコン レイアウトを実装するためのベスト プラクティス
Oct 20, 2023 am 10:46 AM
CSS レイアウトのヒント: 円形グリッド アイコン レイアウトを実装するためのベスト プラクティス グリッド レイアウトは、最新の Web デザインにおける一般的で強力なレイアウト手法です。円形のグリッド アイコン レイアウトは、よりユニークで興味深いデザインの選択です。この記事では、円形グリッド アイコン レイアウトの実装に役立ついくつかのベスト プラクティスと具体的なコード例を紹介します。 HTML 構造 まず、コンテナ要素を設定し、このコンテナにアイコンを配置する必要があります。順序なしリスト (<ul>) をコンテナとして使用でき、リスト項目 (<l
 Python でのコンピューター ビジョンの例: オブジェクト検出
Jun 10, 2023 am 11:36 AM
Python でのコンピューター ビジョンの例: オブジェクト検出
Jun 10, 2023 am 11:36 AM
人工知能の発展に伴い、コンピュータービジョン技術は人々の注目の焦点の1つとなっています。 Python は効率的で習得しやすいプログラミング言語として、コンピュータ ビジョンの分野で広く認識され、推進されています。この記事では、Python でのコンピューター ビジョンの例であるオブジェクト検出に焦点を当てます。物体検出とは何ですか?物体検出はコンピュータ ビジョンの分野における重要なテクノロジであり、その目的は、写真やビデオ内の特定の物体の位置とサイズを識別することです。画像分類と比較して、ターゲット検出では画像を識別するだけでなく、
 ターゲット検出のための最新のディープ アーキテクチャはパラメータが半分で、3 倍高速です +
Apr 09, 2023 am 11:41 AM
ターゲット検出のための最新のディープ アーキテクチャはパラメータが半分で、3 倍高速です +
Apr 09, 2023 am 11:41 AM
簡単な紹介 研究の著者は、物体検出のための新しいディープ アーキテクチャである Matrix Net (xNet) を提案しています。 xNet は、サイズ寸法とアスペクト比が異なるオブジェクトをネットワーク層にマッピングします。ネットワーク層では、オブジェクトのサイズとアスペクト比は層内でほぼ均一です。したがって、xNet はサイズとアスペクト比を認識したアーキテクチャを提供します。研究者は xNet を使用して、キーポイントベースのターゲット検出を強化します。新しいアーキテクチャは、他のシングルショット検出器よりも高い時間効率を実現し、MS COCO データセットで 47.8 mAP を達成しながら、パラメータの半分を使用し、2 番目に優れたフレームワークよりも 3 倍高速にトレーニングします。上の単純な結果表示に示されているように、xNet のパラメーターと効率は他のモデルをはるかに上回っています。
