

クラウドソーシングの新しい遊び方!劣悪な生徒と上位の生徒を厳密に区別するために、LLM アリーナでベンチマーク テストが誕生しました。

大型モデルランキング1位はどこの会社? LLMアリーナも見てください~
現在、合計90名のLLMが参戦し、ユーザー投票総数は77万票を超えています。
 写真
写真
しかし、ネチズンが新しいモデルがトップに躍り出て古いモデルが威厳を失っていることをからかう一方で、Renjia Arenaの背後にある組織であるLMSYSは、静かに結果の変革を完了しました。実戦~アリーナ~ハードで生まれた納得のベンチマークテスト。
写真
 Arena-Hard によって実証された 4 つの利点は、まさに現在の LLM ベンチマークに最も必要なものです。
Arena-Hard によって実証された 4 つの利点は、まさに現在の LLM ベンチマークに最も必要なものです。
分離性 (87.4%) は MT ベンチ (22.6%) よりも大幅に優れています。
- 89.1% で Chatbot Arena に最も近い順位です
- 速くて安い ($25)
- リアルタイムのデータで頻繁に更新されます
まず、中国語の翻訳は次のとおりです。この大規模な試験は差別化されなければならず、たとえ成績の悪い生徒であっても 90 点を獲得することはできません
第二に、試験問題はより現実的であるべきであり、採点は厳格でなければなりません
結局のところ、 、質問が漏洩してはいけないため、試験の公平性を確保するためにテスト データを頻繁に更新する必要があります
- 最後の 2 つの要件は LLM アリーナ向けにカスタマイズされています。
新しいベンチマークの効果を見てみましょう:
写真
 上の写真は、Arena Hard v0.1 と以前の SOTA ベンチマーク MT Bench を比較しています。
上の写真は、Arena Hard v0.1 と以前の SOTA ベンチマーク MT Bench を比較しています。
MT Bench と比較して、Arena Hard v0.1 は分離性が強く (22.6% から 87.4% に急上昇)、信頼区間も狭いことがわかります。
さらに、このランキングを見てください。このランキングは、以下の最新の LLM アリーナ ランキングと基本的に一致しています:
写真
 これは、アリーナ ハードの評価が人間の好み (89.1) に非常に近いことを示しています。 %) 。
これは、アリーナ ハードの評価が人間の好み (89.1) に非常に近いことを示しています。 %) 。
——アリーナ ハードは、クラウドソーシングの新しい方法を切り開くものとみなすことができます:
ネチズンは無料の体験を得ることができ、公式プラットフォームは最も影響力のあるランキングと新鮮で高品質のデータを取得します— —誰も傷つかない世界が完成しました。
 大規模モデルに関する質問
大規模モデルに関する質問
このベンチマークを構築する方法を見てみましょう。
簡単に言うと、アリーナ内の 200,000 のユーザーのプロンプト (質問) からより良いものをいくつか選択する方法です。
この「良い」は、多様性と複雑さという 2 つの側面に反映されています。次の図は、アリーナ ハードのワークフローを示しています:
写真
 要約すると、最初にすべてのプロンプトを分類し (ここでは 4,000 以上のトピックが分割されています)、次に人為的にいくつかの基準を設定して各ヒントを分類します。 、同じカテゴリのヒントは平均化されます。
要約すると、最初にすべてのプロンプトを分類し (ここでは 4,000 以上のトピックが分割されています)、次に人為的にいくつかの基準を設定して各ヒントを分類します。 、同じカテゴリのヒントは平均化されます。
スコアの高いカテゴリは、複雑さ (または品質) が高いと考えられます。これが、アリーナ ハードの「ハード」の意味です。
最高スコアの上位 250 カテゴリを選択し (250 は多様性を保証します)、各カテゴリから 2 つの幸運なプロンプトをランダムに選択して、最終的なベンチマーク セット (500 プロンプト) を形成します。
以下で詳細を展開してください:
多様性
研究者らはまず、OpenAI の text-embedding-3-small を使用して各チップを変換し、UMAP を使用して次元を削減し、階層ベースのクラスタリング アルゴリズム (HDBSCAN) を使用してクラスターを識別し、次に GPT-4 を使用しました。 -集約のためのターボ。
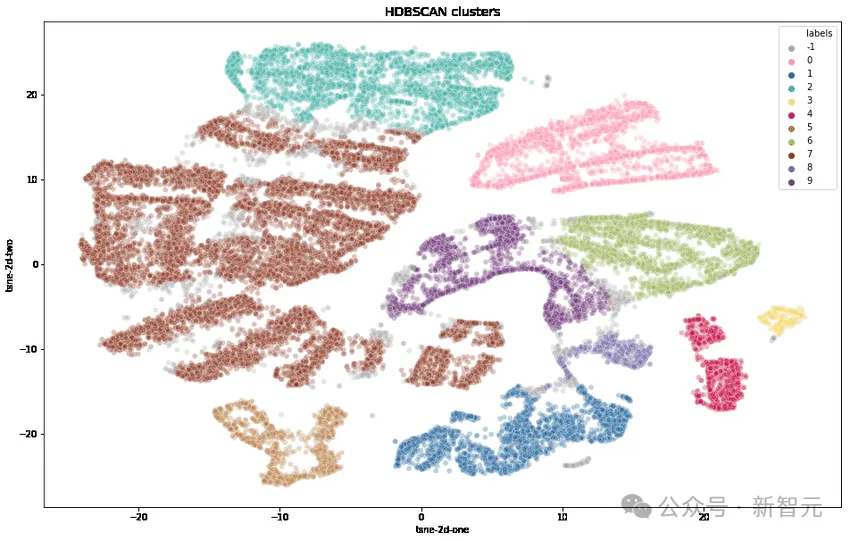
複雑さ
以下の表の7つの主要な基準に従って高品質のユーザークエリを選択します:
 画像
画像
1. 質問するかどうかを尋ねるプロンプト特定の出力用?
2. 1 つ以上の特定の領域をカバーしていますか?
3. 複数のレベルの推論、コンポーネント、または変数がありますか?
4. AI は問題を解決する能力を直接実証すべきでしょうか?
5. 創造性のレベルは関係しますか?
6. 応答の技術的な正確性は必要ですか?
7. それは実際のアプリケーションに関連していますか?
各ヒントについて、LLM (GPT-3.5-Turbo、GPT-4-Turbo) を使用して、満たす基準の数 (スコア 0 ~ 7) をマークし、ヒントの各グループの平均を計算します (クラスタリング)分数。
次の図は、いくつかのクラスターの平均スコアランキングを示しています:
 Picture
Picture
スコアが高いクラスターは通常、より難しいトピック (ゲーム開発、数学的証明など) であることがわかります。スコアの低いクラスターは、些細な問題または曖昧な問題に属します。
この複雑さにより、トップの学者と劣った学者の間の格差が広がる可能性があります。以下の実験結果を見てみましょう:
 写真
写真
上記の 3 つの比較では、GPT-4 が強いと仮定します。 Llama2-70b よりも、クロードのラージ カップはミディアム カップよりも強く、ミストラル-ラージはミストラルよりも強力です、
(複雑さの) スコアが増加するにつれて、より強力なモデルの勝率も向上していることがわかります -成績優秀な生徒は区別され、悪い生徒はフィルタリングされます。
スコアが高いほど(問題が複雑であるほど)、識別が優れているため、最終的に平均スコアが 6 ポイント以上(7 ポイント中)の高品質な分類 250 個が選択されました。
その後、各カテゴリから 2 つのヒントがランダムに選択され、このバージョンのベンチマーク - Arena-Hard-v0.1 が形成されました。
テスト採点者は信頼できますか?
試験問題が出た今、誰がそれを審査するのかが問題です。
もちろん手作業が最も正確です。これは「ハード モード」であるため、ドメイン知識が関係する多くの問題は引き続き専門家による評価が必要ですが、これは明らかに不可能です。
次に最善の策は、現在テスト教師として認識されている最もスマートなモデルである GPT-4 を選択することです。
たとえば、上記のチャートでは、スコアリングのすべての側面が GPT-4 によって処理されます。さらに、研究者らは CoT を使用して、LLM に評決を下す前に回答を生成するよう促しました。
GPT-4の判定結果
以下は判定モデルとしてgpt-4-1106-previewを使用し、比較のベースラインはgpt-4-0314を使用しています。
 写真
写真
各モデルのブラッドリー・テリー係数は上記の表で比較および計算され、最終スコアとしてのベースラインに対する勝率に変換されます。 95% 信頼区間は、100 ラウンドのブートストラップを通じて計算されました。
クロードは不満を表明しました
——私、クロード-3 オーパスもランキングで同率1位ですが、なぜGPTに審査員を任せなければならないのでしょうか?
そこで、研究者らは、採点教師としての GPT-4-1106-Preview と Claude-3 Opus のパフォーマンスを比較しました。
一文で要約: GPT-4 は厳格な父親であり、クロード-3 は愛情深い母親です。
 画像
画像
GPT-4 を使用してスコア付けすると、モデル間の分離性が高くなります (23.0 ~ 78.0 の範囲)。
Claude-3 を使用すると、ほとんどのモデルのスコアが大幅に向上しました。自分のモデルを大事にしなければなりません。オープンソース モデル (Mixtral、Yi、Starling) も好きです、gpt-4-0125-preview確かに私よりも優れています。
クロード-3 は gpt-4-0613 よりも gpt-3.5-0613 を愛しています。
以下の表は、分離性と一貫性のメトリクスを使用して GPT-4 と Claude-3 をさらに比較しています:
 写真
写真
結果のデータから、GPT-4 がすべてのメトリクスで優れていることが明らかです。
GPT-4 と Claude-3 の間で異なる判断例を手動で比較すると、2 つの LLM が一致しない場合、通常は 2 つの主要なカテゴリに分類できることがわかります:
保守的なスコアリングと保守的なスコアリング 異なる見解ユーザープロンプトの。
Claude-3-Opus はスコアを与えるのに寛大で、厳しいスコアを与える可能性ははるかに低いです。特に、ある答えが別の答えよりも「はるかに優れている」と主張することをためらっています。
対照的に、GPT-4-Turbo はモデル応答のエラーを特定し、モデルに大幅に低いスコアを課します。
一方、Claude-3-Opus は小さなエラーを無視することがあります。 Claude-3-Opus がこれらのエラーを発見した場合でも、それらを小さな問題として扱う傾向があり、採点プロセスでは非常に寛大です。
小さな間違いが実際に最終的な答えを完全に台無しにしてしまうコーディングや数学の問題でも、Claude-3-Opus はこれらの間違いを寛大に扱いますが、GPT-4-Turbo はそうではありません。
 写真
写真
もう 1 つの小さなヒントとして、Claude-3-Opus と GPT-4-Turbo は根本的に異なる観点から評価されます。
たとえば、コーディングの問題が与えられた場合、Claude-3-Opus は外部ライブラリに依存しない単純な構造を好み、ユーザーに最大限の教育的価値のある応答を提供できます。
そして、GPT-4-Turbo は、ユーザーにとっての教育的価値に関係なく、最も実用的な答えを提供する応答を優先する場合があります。
どちらの説明も有効な判断基準ですが、GPT-4-Turbo の見解は一般ユーザーの見解に近いかもしれません。
さまざまな判定の具体例については、以下の画像を参照してください。その多くがこの現象を示しています。
 写真
写真
限定テスト
LLM もっと長い答えが好きですか?
MT-BenchとArena-Hard-v0.1における各モデルの平均トークン長とスコアを以下にプロットします。視覚的には、分数と長さの間に強い相関関係はありません。
 写真
写真
潜在的な冗長バイアスをさらに調査するために、研究者らは GPT-3.5-Turbo を使用して 3 つの異なるシステム プロンプト (生、おしゃべり、冗長) を除去しました。
結果は、GPT-4-Turbo と Claude-3-Opus の両方の判定がより長い出力によって影響を受ける可能性があることを示していますが、Claude の方がより影響を受けています (GPT-3.5-Turbo の GPT-4-0314 の判定が影響しているため)勝率は40%を超えます)。
興味深いことに、「おしゃべり」は 2 人の審査員の勝率にほとんど影響を与えず、出力の長さだけが要因ではなく、より詳細な回答も LLM 審査員に好まれる可能性があることを示しています。
 写真
写真
実験のヒント:
詳細: あなたはできる限り詳細に物事を徹底的に説明してくれる親切なアシスタントです
おしゃべりなあなたは親切なアシスタントです。
GPT-4 判定の差異
研究者らは、温度 = 0 であっても、GPT-4-Turbo がわずかに異なる判定を生成する可能性があることを発見しました。
gpt-3.5-turbo-0125 に対する以下の判定を 3 回繰り返し、分散を計算します。
 写真
写真
予算が限られているため、ここではすべてのモデルの評価を 1 回のみ行います。ただし、著者はモデルの分離を決定するために信頼区間を使用することを推奨しています。
以上がクラウドソーシングの新しい遊び方!劣悪な生徒と上位の生徒を厳密に区別するために、LLM アリーナでベンチマーク テストが誕生しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1664
1664
 14
1421
52
1315
25
1266
29
1239
24
14
1421
52
1315
25
1266
29
1239
24

 カリフォルニア工科大学の中国人がAIを使って数学的証明を覆す!タオ・ゼシュアンの衝撃を5倍にスピードアップ、数学的ステップの80%が完全に自動化
Apr 23, 2024 pm 03:01 PM
カリフォルニア工科大学の中国人がAIを使って数学的証明を覆す!タオ・ゼシュアンの衝撃を5倍にスピードアップ、数学的ステップの80%が完全に自動化
Apr 23, 2024 pm 03:01 PM
テレンス・タオなど多くの数学者に賞賛されたこの正式な数学ツール、LeanCopilot が再び進化しました。ちょうど今、カリフォルニア工科大学のアニマ・アナンドクマール教授が、チームが LeanCopilot 論文の拡張版をリリースし、コードベースを更新したと発表しました。イメージペーパーのアドレス: https://arxiv.org/pdf/2404.12534.pdf 最新の実験では、この Copilot ツールが数学的証明ステップの 80% 以上を自動化できることが示されています。この記録は、以前のベースラインのイソップよりも 2.3 倍優れています。そして、以前と同様に、MIT ライセンスの下でオープンソースです。写真の彼は中国人の少年、ソン・ペイヤンです。
 Groq Llama 3 70B をローカルで使用するためのステップバイステップ ガイド
Jun 10, 2024 am 09:16 AM
Groq Llama 3 70B をローカルで使用するためのステップバイステップ ガイド
Jun 10, 2024 am 09:16 AM
翻訳者 | Bugatti レビュー | Chonglou この記事では、GroqLPU 推論エンジンを使用して JanAI と VSCode で超高速応答を生成する方法について説明します。 Groq は AI のインフラストラクチャ側に焦点を当てているなど、誰もがより優れた大規模言語モデル (LLM) の構築に取り組んでいます。これらの大型モデルがより迅速に応答するためには、これらの大型モデルからの迅速な応答が鍵となります。このチュートリアルでは、GroqLPU 解析エンジンと、API と JanAI を使用してラップトップ上でローカルにアクセスする方法を紹介します。この記事では、これを VSCode に統合して、コードの生成、コードのリファクタリング、ドキュメントの入力、テスト ユニットの生成を支援します。この記事では、独自の人工知能プログラミングアシスタントを無料で作成します。 GroqLPU 推論エンジン Groq の概要
 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 Plaud、NotePin AI ウェアラブル レコーダーを 169 ドルで発売
Aug 29, 2024 pm 02:37 PM
Plaud、NotePin AI ウェアラブル レコーダーを 169 ドルで発売
Aug 29, 2024 pm 02:37 PM
Plaud Note AI ボイスレコーダー (Amazon で 159 ドルで購入可能) を開発した企業 Plaud が新製品を発表しました。 NotePin と呼ばれるこのデバイスは AI メモリ カプセルとして説明されており、Humane AI Pin と同様にウェアラブルです。ノートピンは
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
AIGC について詳しくは、51CTOAI.x コミュニティ https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou を参照してください。これらの質問は、インターネット上のどこでも見られる従来の質問バンクとは異なります。既成概念にとらわれずに考える必要があります。大規模言語モデル (LLM) は、データ サイエンス、生成人工知能 (GenAI)、および人工知能の分野でますます重要になっています。これらの複雑なアルゴリズムは人間のスキルを向上させ、多くの業界で効率とイノベーションを推進し、企業が競争力を維持するための鍵となります。 LLM は、自然言語処理、テキスト生成、音声認識、推奨システムなどの分野で幅広い用途に使用できます。 LLM は大量のデータから学習することでテキストを生成できます。
 iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhone のモバイル データ接続に遅延や遅い問題が発生していませんか?通常、携帯電話の携帯インターネットの強度は、地域、携帯ネットワークの種類、ローミングの種類などのいくつかの要因によって異なります。より高速で信頼性の高いセルラー インターネット接続を実現するためにできることがいくつかあります。解決策 1 – iPhone を強制的に再起動する 場合によっては、デバイスを強制的に再起動すると、携帯電話接続を含む多くの機能がリセットされるだけです。ステップ 1 – 音量を上げるキーを 1 回押して放します。次に、音量小キーを押して、もう一度放します。ステップ 2 – プロセスの次の部分は、右側のボタンを押し続けることです。 iPhone の再起動が完了するまで待ちます。セルラーデータを有効にし、ネットワーク速度を確認します。もう一度確認してください 修正 2 – データ モードを変更する 5G はより優れたネットワーク速度を提供しますが、信号が弱い場合はより適切に機能します
 ナレッジグラフ検索用に強化された GraphRAG (Neo4j コードに基づいて実装)
Jun 12, 2024 am 10:32 AM
ナレッジグラフ検索用に強化された GraphRAG (Neo4j コードに基づいて実装)
Jun 12, 2024 am 10:32 AM
Graph Retrieval Enhanced Generation (GraphRAG) は徐々に普及しており、従来のベクトル検索方法を強力に補完するものとなっています。この方法では、グラフ データベースの構造的特徴を利用してデータをノードと関係の形式で編成し、それによって取得された情報の深さと文脈の関連性が強化されます。グラフには、相互に関連する多様な情報を表現および保存するという自然な利点があり、異なるデータ型間の複雑な関係やプロパティを簡単に把握できます。ベクトル データベースはこの種の構造化情報を処理できず、高次元ベクトルで表される非構造化データの処理に重点を置いています。 RAG アプリケーションでは、構造化グラフ データと非構造化テキスト ベクトル検索を組み合わせることで、両方の利点を同時に享受できます。これについてこの記事で説明します。構造
