

自動運転の初の純粋な視覚的静的再構築

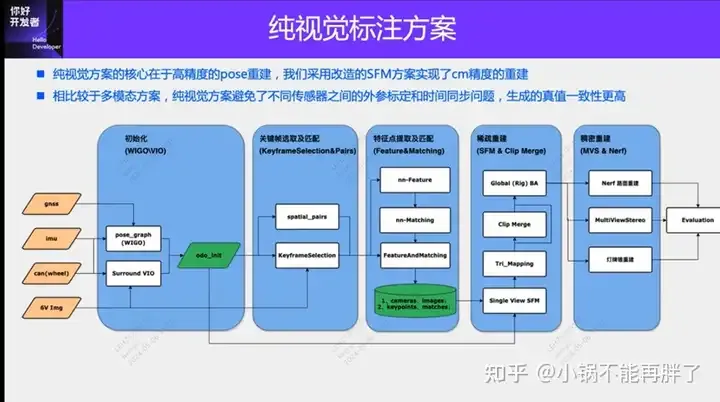
純粋に視覚的な注釈ソリューションは、主に視覚に加えて、動的注釈のために GPS、IMU、および車輪速度センサーからのデータを使用します。もちろん、量産シナリオでは、純粋に視覚的なものである必要はありません。一部の量産車両には固体レーダー (AT128) などのセンサーが搭載されています。大量生産の観点からデータの閉ループを作成し、これらすべてのセンサーを使用すると、動的オブジェクトのラベル付けの問題を効果的に解決できます。しかし、私たちの計画には固体レーダーはありません。したがって、この最も一般的な量産ラベル ソリューションを紹介します。
純粋に視覚的な注釈ソリューションの中核は、高精度のポーズ再構築にあります。再構築の精度を確保するために、Structure from Motion (SFM) ポーズ再構築スキームを使用します。ただし、従来の SFM、特にインクリメンタル SFM は非常に遅く、計算量は O(n^4) (n はイメージの数) です。この種の再構成効率は、大規模モデルのデータ アノテーションには受け入れられません。SFM ソリューションにいくつかの改良を加えました。
改善されたクリップ再構築は主に 3 つのモジュールに分かれています: 1) マルチセンサーデータ、GNSS、IMU、およびホイールスピードメーターを使用して、pose_graph 最適化を構築し、初期ポーズを取得します。このアルゴリズムは Wheel-Imu-GNSS -Odometry と呼ばれます。 WIGO); 2) 画像の特徴抽出とマッチング、および初期 3D ポイントを取得するための初期化されたポーズを直接使用した三角形分割。 3) 最後に、グローバル BA (バンドル調整) が実行されます。 一方で、私たちのソリューションはインクリメンタル SFM を回避し、他方では、異なるクリップ間での並列操作を実現できるため、ポーズ再構築の効率が大幅に向上します。既存のインクリメンタル再構築と比較して、10 ~ 20 の効率を達成できます。倍の効率向上。
単一の再構築プロセス中に、私たちのソリューションはいくつかの最適化も行いました。たとえば、学習ベースの特徴 (Superpoint と Superglue) を使用し、1 つは特徴点、もう 1 つはマッチング手法 を使用して、従来の SIFT キー ポイントを置き換えました。 NN フィーチャーを学習する利点は、カスタマイズされたニーズに合わせてルールをデータ駆動型で設計できることと、弱いテクスチャや暗い照明状況での堅牢性を向上できることです。キーポイントの検出とマッチングの効率。いくつかの比較実験を行った結果、夜景での NN 特徴の成功率は SFIT の 20% から 80% に比べて約 4 倍高くなることがわかりました。
単一のClipの再構築結果を取得した後、複数のClipを集約します。既存の HDmap マッピング構造マッチング方式とは異なり、集約の精度を確保するために、特徴点レベルの集約を採用しています。つまり、クリップ間の集約制約は特徴点のマッチングを通じて実装されます。この操作は、SLAM のループ クロージャ検出に似ています。最初に、GPS を使用していくつかの一致するフレームを決定します。次に、特徴点と説明を使用して画像を照合し、最後にこれらのループ クロージャ制約を組み合わせてグローバル BA (バンドル) を構築します。調整)して最適化します。現在、当社のソリューションの精度と RTE インデックスは、既存のビジュアル SLAM ソリューションやマッピング ソリューションをはるかに上回っています。
実験: Colmap cuda バージョンを使用し、180 枚の画像、解像度 3848*2168 を使用し、内部パラメーターを手動で設定し、残りはデフォルト設定を使用します。スパース再構成には約 15 分かかり、密再構成全体には非常に時間がかかります。時間 (1-2h)
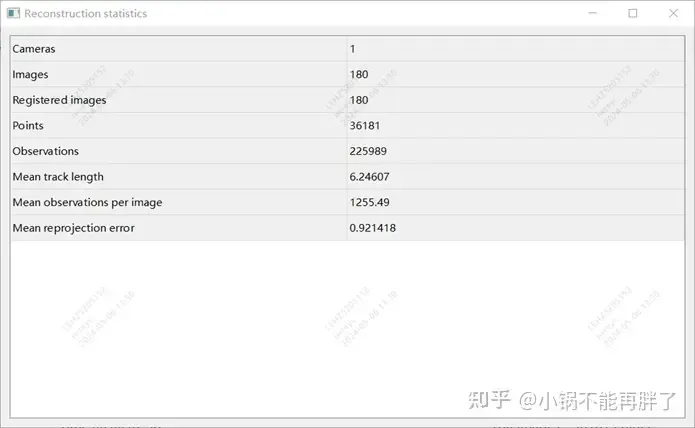
再構成結果統計
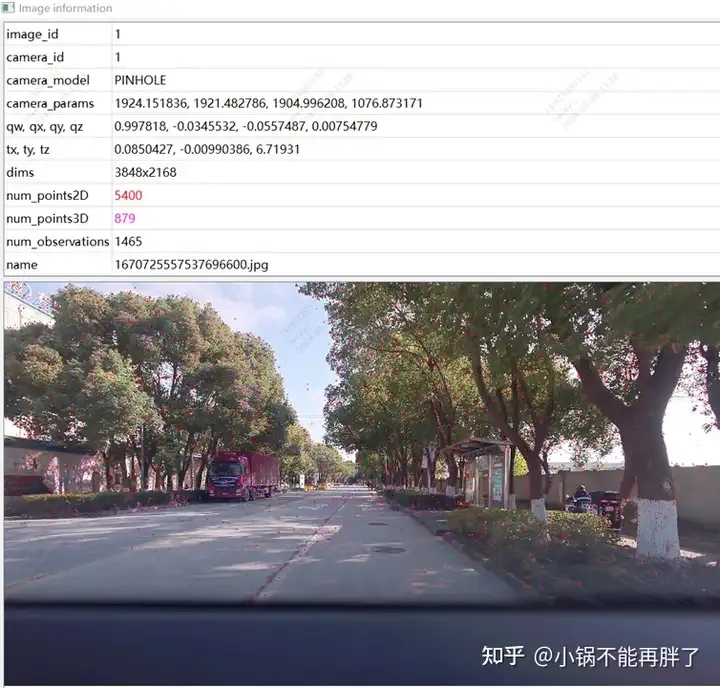
特徴点図

スパース再構成効果

直線セクションの全体的な効果

グラウンドコーンエフェクト

高さの速度制限標識エフェクト

交差点横断歩道エフェクト
さらに、一連の画像を試してみましたが、収束しませんでした: 静的自我フィルタリング、フォーミング。車両の動きに応じて 50 ~ 100 メートルごとのクリップ、ハイダイナミック シーンのダイナミック ポイント フィルタリング、トンネル シーンのポーズ
全周およびパノラママルチカメラの使用: 特徴点マッチングマップの最適化、内部および外部パラメーターの最適化項目、既存の odom の使用。
https://github.com/colmap/colmap/blob/main/pycolmap/custom_bundle_adjustment.py
pyceres.solve(solver_options, Bundle_adjuster.problem, summary)
3DGS は高密度再構成を高速化します。そうでないと時間がかかりすぎます受け入れる
以上が自動運転の初の純粋な視覚的静的再構築の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7534
7534
 15
1379
52
82
11
21
86
15
1379
52
82
11
21
86

 なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
上記と著者の個人的な理解 3 次元ガウシアンプラッティング (3DGS) は、近年、明示的な放射線フィールドとコンピューター グラフィックスの分野で出現した革新的なテクノロジーです。この革新的な方法は、数百万の 3D ガウスを使用することを特徴とし、主に暗黙的な座標ベースのモデルを使用して空間座標をピクセル値にマッピングする神経放射線場 (NeRF) 方法とは大きく異なります。明示的なシーン表現と微分可能なレンダリング アルゴリズムにより、3DGS はリアルタイム レンダリング機能を保証するだけでなく、前例のないレベルの制御とシーン編集も導入します。これにより、3DGS は、次世代の 3D 再構築と表現にとって大きな変革をもたらす可能性のあるものとして位置付けられます。この目的を達成するために、私たちは 3DGS 分野における最新の開発と懸念について初めて体系的な概要を提供します。
 自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
昨日の面接で、ロングテール関連の質問をしたかと聞かれたので、簡単にまとめてみようと思いました。自動運転のロングテール問題とは、自動運転車におけるエッジケース、つまり発生確率が低い考えられるシナリオを指します。認識されているロングテール問題は、現在、単一車両のインテリジェント自動運転車の運用設計領域を制限している主な理由の 1 つです。自動運転の基礎となるアーキテクチャとほとんどの技術的問題は解決されており、残りの 5% のロングテール問題が徐々に自動運転の開発を制限する鍵となってきています。これらの問題には、さまざまな断片的なシナリオ、極端な状況、予測不可能な人間の行動が含まれます。自動運転におけるエッジ シナリオの「ロング テール」とは、自動運転車 (AV) におけるエッジ ケースを指します。エッジ ケースは、発生確率が低い可能性のあるシナリオです。これらの珍しい出来事
 カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
0.前面に書かれています&& 自動運転システムは、さまざまなセンサー (カメラ、ライダー、レーダーなど) を使用して周囲の環境を認識し、アルゴリズムとモデルを使用することにより、高度な知覚、意思決定、および制御テクノロジーに依存しているという個人的な理解リアルタイムの分析と意思決定に。これにより、車両は道路標識の認識、他の車両の検出と追跡、歩行者の行動の予測などを行うことで、安全な運行と複雑な交通環境への適応が可能となり、現在広く注目を集めており、将来の交通分野における重要な開発分野と考えられています。 。 1つ。しかし、自動運転を難しくしているのは、周囲で何が起こっているかを車に理解させる方法を見つけることです。これには、自動運転システムの 3 次元物体検出アルゴリズムが、周囲環境にある物体 (位置を含む) を正確に認識し、記述することができる必要があります。
 ORB-SLAM3を超えて! SL-SLAM: 低照度、重度のジッター、弱いテクスチャのシーンはすべて処理されます。
May 30, 2024 am 09:35 AM
ORB-SLAM3を超えて! SL-SLAM: 低照度、重度のジッター、弱いテクスチャのシーンはすべて処理されます。
May 30, 2024 am 09:35 AM
以前に書きましたが、今日は、深層学習テクノロジーが複雑な環境におけるビジョンベースの SLAM (同時ローカリゼーションとマッピング) のパフォーマンスをどのように向上させることができるかについて説明します。ここでは、深部特徴抽出と深度マッチング手法を組み合わせることで、低照度条件、動的照明、テクスチャの弱い領域、激しいセックスなどの困難なシナリオでの適応を改善するように設計された多用途のハイブリッド ビジュアル SLAM システムを紹介します。当社のシステムは、拡張単眼、ステレオ、単眼慣性、ステレオ慣性構成を含む複数のモードをサポートしています。さらに、他の研究にインスピレーションを与えるために、ビジュアル SLAM と深層学習手法を組み合わせる方法も分析します。公開データセットと自己サンプリングデータに関する広範な実験を通じて、測位精度と追跡堅牢性の点で SL-SLAM の優位性を実証しました。
 座標系の変換を本当にマスターしましたか?自動運転と切り離せないマルチセンサーの問題
Oct 12, 2023 am 11:21 AM
座標系の変換を本当にマスターしましたか?自動運転と切り離せないマルチセンサーの問題
Oct 12, 2023 am 11:21 AM
最初のパイロットおよび重要な記事では、主に自動運転技術で一般的に使用されるいくつかの座標系と、それらの間の相関と変換を完了し、最終的に統合環境モデルを構築する方法を紹介します。ここでの焦点は、車両からカメラの剛体への変換 (外部パラメータ)、カメラから画像への変換 (内部パラメータ)、および画像からピクセル単位への変換を理解することです。 3D から 2D への変換には、対応する歪み、変換などが発生します。要点:車両座標系とカメラ本体座標系を平面座標系とピクセル座標系に書き換える必要がある 難易度:画像の歪みを考慮する必要がある 歪み補正と歪み付加の両方を画面上で補正する2. はじめに ビジョンシステムには、ピクセル平面座標系 (u, v)、画像座標系 (x, y)、カメラ座標系 ()、世界座標系 () の合計 4 つの座標系があります。それぞれの座標系には関係性があり、
 自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転では軌道予測が重要な役割を果たしており、自動運転軌道予測とは、車両の走行過程におけるさまざまなデータを分析し、将来の車両の走行軌跡を予測することを指します。自動運転のコアモジュールとして、軌道予測の品質は下流の計画制御にとって非常に重要です。軌道予測タスクには豊富な技術スタックがあり、自動運転の動的/静的知覚、高精度地図、車線境界線、ニューラル ネットワーク アーキテクチャ (CNN&GNN&Transformer) スキルなどに精通している必要があります。始めるのは非常に困難です。多くのファンは、できるだけ早く軌道予測を始めて、落とし穴を避けたいと考えています。今日は、軌道予測に関するよくある問題と入門的な学習方法を取り上げます。関連知識の紹介 1. プレビュー用紙は整っていますか? A: まずアンケートを見てください。
 SIMPL: 自動運転向けのシンプルで効率的なマルチエージェント動作予測ベンチマーク
Feb 20, 2024 am 11:48 AM
SIMPL: 自動運転向けのシンプルで効率的なマルチエージェント動作予測ベンチマーク
Feb 20, 2024 am 11:48 AM
原題: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving 論文リンク: https://arxiv.org/pdf/2402.02519.pdf コードリンク: https://github.com/HKUST-Aerial-Robotics/SIMPL 著者単位: 香港科学大学DJI 論文のアイデア: この論文は、自動運転車向けのシンプルで効率的な動作予測ベースライン (SIMPL) を提案しています。従来のエージェントセントとの比較
 nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
先頭と開始点に書かれている エンドツーエンドのパラダイムでは、統一されたフレームワークを使用して自動運転システムのマルチタスクを実現します。このパラダイムの単純さと明確さにも関わらず、サブタスクにおけるエンドツーエンドの自動運転手法のパフォーマンスは、依然としてシングルタスク手法に比べてはるかに遅れています。同時に、以前のエンドツーエンド手法で広く使用されていた高密度鳥瞰図 (BEV) 機能により、より多くのモダリティやタスクに拡張することが困難になります。ここでは、スパース検索中心のエンドツーエンド自動運転パラダイム (SparseAD) が提案されています。このパラダイムでは、スパース検索は、高密度の BEV 表現を使用せずに、空間、時間、タスクを含む運転シナリオ全体を完全に表します。具体的には、統合されたスパース アーキテクチャが、検出、追跡、オンライン マッピングなどのタスク認識のために設計されています。さらに、重い
