

GPT-4o と GPT-4 Turbo を 1 つの記事で読む

皆さんこんにちは、私はルーガです。今日は人工知能 (AI) の生態分野に関連するテクノロジー、つまり GPT-4o モデルについて話します。
2024 年 5 月 13 日、OpenAI は最も先進的で最先端のモデル GPT-4o を革新的に発売しました。これは、人工知能チャットボットと大規模言語モデルの分野における大きな進歩を示す動きです。人工知能機能の新時代の到来を告げる GPT-4o は、速度と多用途性の両方で前世代の GPT-4 を上回る大幅なパフォーマンスの向上を誇ります。
この画期的な進歩により、以前のバージョンでしばしば悩まされていた遅延の問題が解決され、シームレスで応答性の高いユーザー エクスペリエンスが保証されます。

GPT-4o とは何ですか?
2024 年 5 月 13 日、OpenAI は最新かつ最先端の人工知能モデル GPT-4o をリリースしました。ここで、「o」は「omni」を表し、「すべて」または「すべて」を意味します。 「普遍的」。このモデルは、GPT-4 Turbo に基づく新世代の大規模言語モデルです。 GPT-4oは、従来モデルに比べ、出力速度、回答品質、対応言語が大幅に向上し、入力データの処理形式も革新的になりました。
GPT-4o+ モデルの最も注目すべき革新は、異なる種類の入力データを処理するために独立したニューラル ネットワークを使用する以前のモデルの慣行を放棄し、代わりに単一の統合ニューラル ネットワークを使用してすべての入力を処理することです。この革新的な設計により、GPT-4o+ には前例のないマルチモーダル フュージョン機能が提供されます。 マルチモーダル フュージョンとは、より包括的で正確な結果を得るために、さまざまな種類の入力データ (画像、テキスト、オーディオなど) を統合して処理することを指します。以前のモデルでは、マルチモーダル データを処理するときにさまざまなネットワーク構造を設計する必要があり、多くのコンピューティング リソースと時間を消費していました。 GPT-4o+ は統合ニューラル ネットワークを使用することで、さまざまな種類の入力データのシームレスな接続を実現し、従来の言語モデルは通常、プレーン テキスト入力のみを処理でき、音声や画像などの非テキスト データを処理できません。ただし、GPT-4o は、背景ノイズ、複数の音源、音声入力内の感情的な色などの非テキスト信号を同時に検出および解析でき、これらのマルチモーダル情報を意味理解および生成プロセスに融合して、より豊かで、よりコンテキストに即した出力を生成します。
GPT-4o+ は、マルチモーダル入力の処理に加えて、多言語出力を生成する際にも優れた優れた出力機能を発揮します。 GPT-4o+ は、英語などの主流言語で高品質で文法的に正確で簡潔な表現を出力するだけでなく、英語以外の言語のシナリオでも同じレベルの出力を維持できます。これにより、英語ユーザーとその他の言語ユーザーの両方が GPT-4o+ の優れた自然言語生成機能を活用できるようになります。
一般に、GPT-4o+ の最大のハイライトは、単一モダリティの限界を突破し、クロスモーダルの包括的な理解と生成機能を実現することです。革新的なニューラル ネットワーク アーキテクチャとトレーニング メカニズムの助けを借りて、GPT-4o+ は複数の感覚チャネルから情報を取得するだけでなく、生成中にそれを統合して、より状況に応じた、よりパーソナライズされた応答を生成することもできます。
GPT-4o と GPT-4 Turbo のパフォーマンス
GPT-4 は、OpenAI によって発売された最新のマルチモーダル大型モデルであり、そのパフォーマンスは前世代の GPT-4 Turbo と比較して質的に飛躍しています。ここでは、次の主要な側面で 2 つの比較分析を行うことができます。 まず、GPT-4とGPT-4 Turboではモデルサイズに違いがあります。 GPT-4 には GPT-4 Turbo よりも多くのパラメータがあるため、より複雑なタスクと大規模なデータ セットを処理できます。これにより、GPT-4 は意味の理解やテキスト生成などにおいて、より高い精度と流暢性を実現できるようになります。 その
1. 推論速度
OpenAI が公開したデータによると、同じハードウェア条件下で、GPT-4o の推論速度は GPT-4 Turbo の 2 倍です。この大幅なパフォーマンス向上は主に、モード切り替えによる効率損失を回避する革新的な単一モデル アーキテクチャによるものです。単一モデル アーキテクチャにより、計算プロセスが簡素化されるだけでなく、リソースのオーバーヘッドが大幅に削減され、GPT-4o がリクエストをより高速に処理できるようになります。推論速度が速いということは、GPT-4o がユーザーに低い遅延で応答を提供できることを意味し、インタラクティブなエクスペリエンスが大幅に向上します。リアルタイムの会話、複雑なタスク処理、または同時実行性の高い環境のアプリケーションのいずれにおいても、ユーザーはよりスムーズで即時のサービス応答を体験できます。このパフォーマンスの最適化により、システム全体の効率が向上するだけでなく、さまざまなアプリケーション シナリオに対するより信頼性の高い効率的なサポートも提供されます。
 GPT-4o と GPT-4 Turbo の遅延の比較
GPT-4o と GPT-4 Turbo の遅延の比較
2. スループット
初期の GPT モデルはスループットの点で少し遅れていることが知られています。たとえば、最新の GPT-4 Turbo は 1 秒あたり 20 トークンしか生成できません。ただし、GPT-4o はこの点で大きな進歩を遂げ、1 秒あたり 109 個のトークンを生成できるようになりました。この改善により、GPT-4o の処理速度が大幅に向上し、さまざまなアプリケーション シナリオの効率が向上しました。
それにもかかわらず、GPT-4o はまだ最速のモデルではありません。 Groq でホストされている Llama を例にとると、GPT-4o をはるかに上回る 1 秒あたり 280 トークンを生成できます。ただし、GPT-4o の利点は速度だけではありません。その高度な機能と推論機能により、リアルタイム AI アプリケーションで際立っています。 GPT-4o の単一モデル アーキテクチャと最適化アルゴリズムは、コンピューティング効率を向上させるだけでなく、応答時間を大幅に短縮し、インタラクティブなエクスペリエンスに独自の利点をもたらします。

GPT-4o と GPT-4 Turbo のスループットの比較
さまざまなシナリオでの比較分析
一般的に、GPT-4o と GPT-4 Turbo が異なる種類のタスクを処理する場合、アーキテクチャとモードの違いにより、融合機能の違いにより、パフォーマンスに大きな違いが生じます。ここでは主に、データ抽出、分類、推論という 3 つの代表的なタスク タイプから、両者の違いを分析します。
1. データ抽出
テキスト データ抽出タスクでは、GPT-4 Turbo は強力な自然言語理解機能を利用して優れたパフォーマンスを実現します。ただし、画像やテーブルなどの非構造化データを含むシーンに遭遇すると、その機能が多少制限されます。
対照的に、GPT-4o は、構造化テキストであっても、画像や PDF などの非構造化データであっても、さまざまなモダリティのデータをシームレスに統合し、必要な情報を効率的に識別して抽出できます。この利点により、GPT-4o は複雑な混合データを処理する際の競争力が高まります。
ここでは、ある企業の契約シナリオを例として取り上げます。データセットには、企業と顧客間のマスターサービス契約 (MSA) が含まれています。契約書の長さはさまざまで、5 ページ程度の短いものもあれば、50 ページを超えるものもあります。
今回の評価では、契約タイトル、顧客名、サプライヤー名、解除条項の内容、不可抗力の有無など、計12項目を抽出します。 10件の契約に関する実際のデータ収集を通じて、12のカスタム評価指標を使用して設定されました。これらのメトリクスは、モデルによって生成された JSON 内の各パラメーターの LLM 出力と実際のデータを比較するために使用されます。続いて、GPT-4 Turbo と GPT-4o をテストし、評価レポートの結果を以下に示します:

各プロンプトに対応する 12 の指標の評価結果
上記の比較結果で、次のように結論付けることができます。これら 12 フィールドのうち、GPT-4o は 6 フィールドで GPT-4 Turbo よりも優れたパフォーマンスを示し、5 フィールドで同じ結果が得られ、1 フィールドでわずかにパフォーマンスが劣ります。
絶対的な観点から見ると、GPT-4 と GPT-4o は、ほとんどの分野のデータの 60 ~ 80% しか正しく識別できません。どちらのモデルも、高精度が必要な複雑なデータ抽出タスクでは標準以下のパフォーマンスを発揮しました。ショットプロンプトやチェーン思考プロンプトなどの高度なプロンプトテクニックを使用すると、より良い結果を達成できます。
さらに、GPT-4o は TTFT (最初のトークンまでの時間) において GPT-4 Turbo より 50 ~ 80% 高速であり、直接比較すると GPT-4o に利点があります。最終的な結論は、GPT-4o は、高品質で低遅延であるため、GPT-4 Turbo よりも優れているということです。
2. 分類
分類タスクでは、多くの場合、テキストや画像などのマルチモーダル情報から特徴を抽出し、意味レベルの理解と判断を実行する必要があります。現時点では、GPT-4 Turbo は単一のテキスト モダリティのみの処理に制限されているため、その分類機能は比較的制限されています。
GPT-4o は、マルチモーダル情報を融合して、より包括的な意味表現を形成できるため、テキスト分類、画像分類、感情分析などの分野、特にいくつかの困難なクロスモーダル タスクで優れた分類機能を発揮します。動的分類シナリオ。
ヒントでは、顧客のチケットがいつクローズされるかについて明確な手順を提供し、最も困難なケースの解決に役立ついくつかの例を追加しています。
モデルの出力が 100 個のラベル付きテスト ケースのグラウンド トゥルース データと一致するかどうかをテストする評価を実行することで、関連する結果が次のとおりです:
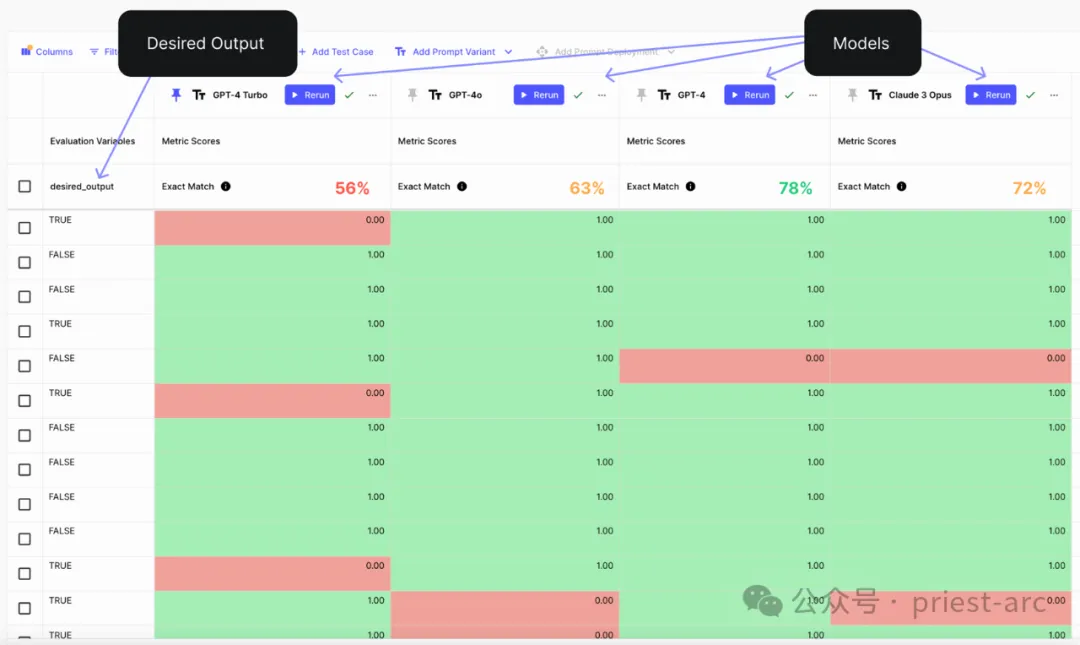
分類分析評価リファレンス
GPT-4o は、間違いなく圧倒的な性的優位性を実証しました。さまざまな複雑なタスクに関する一連のテストと比較を通じて、GPT-4o が全体的な精度において他の競合モデルをはるかに上回り、多くのアプリケーション分野で最初の選択肢となっていることがわかります。
ただし、一般的なソリューションとして GPT-4o に傾いている一方で、最適な AI モデルの選択は一夜にしての意思決定プロセスではないことにも留意する必要があります。結局のところ、AI モデルのパフォーマンスは、多くの場合、特定のアプリケーション シナリオと、精度、再現率、時間効率などのさまざまな指標のトレードオフの好みに依存します。
3. 推論
推論は人工知能システムの高次の認知能力であり、モデルが与えられた前提条件から合理的な結論を導き出す必要があります。これは、論理的推論や質疑応答の推論などのタスクにとって非常に重要です。
GPT-4 Turbo はテキスト推論タスクではうまく機能しましたが、マルチモーダル情報の融合が必要な状況に遭遇した場合、その機能は制限されます。
GPT-4o にはこの制限はありません。テキスト、画像、音声などの複数のモダリティからの意味情報を自由に統合し、これに基づいてより複雑な論理的推論、因果的推論、帰納的推論を実行できるため、人工知能システムにより「人間化された」推論と判断能力が与えられます。 。
上記のシナリオに基づいて、推論レベルでの 2 つの比較を見てみましょう: 具体的なリファレンスは次のとおりです:

16 の推論タスクの評価リファレンス
のテスト例によると。 GPT-4o モデルは、次の推論タスクでパフォーマンスがますます向上していることが観察できます。
- カレンダー計算: GPT-4o は、特定の日付の繰り返し時間を正確に識別できます。つまり、日付を処理できます。関連する計算と推論。
- 時間と角度の計算: GPT-4o は時計の角度を正確に計算できるため、時計と角度に関連する問題を扱うときに非常に役立ちます。
- 語彙 (反意語認識): GPT-4o は反意語を効果的に識別し、単語の意味を理解できます。これは意味の理解と語彙の推論にとって非常に重要です。
GPT-4o は特定の推論タスクでは改善されていますが、単語操作、パターン認識、類推推論、空間推論などのタスクでは依然として課題に直面しています。将来の改善と最適化により、これらの領域におけるモデルのパフォーマンスがさらに向上する可能性があります。
要約すると、1 分あたり最大 1,000 万トークンのレート制限に基づく GPT-4o は、GPT-4 の完全に 5 倍です。このエキサイティングなパフォーマンス指標は、多くの集中的なコンピューティング シナリオ、特にリアルタイム ビデオ分析、インテリジェントな音声対話などの分野で人工知能の普及を加速することは間違いなく、GPT-4o の高い同時応答能力は比類のない利点を示します。
GPT-4o の最も輝かしいイノベーションは、テキスト、画像、音声、その他のマルチモーダル入出力をシームレスに統合する革新的なデザインであることは間違いありません。 GPT-4o は、単一のニューラル ネットワークを通じて各モダリティからのデータを直接統合して処理することで、以前のモデル間の切り替えによる断片化したエクスペリエンスを根本的に解決し、統合された AI アプリケーションを構築する道を開きます。
モーダル融合を実現した後、GPT-4o はアプリケーションシナリオにおいてこれまでにない幅広い展望を持つことになります。コンピューター ビジョン テクノロジーを組み合わせてインテリジェントな画像分析ツールを作成する場合でも、音声認識フレームワークとシームレスに統合してマルチモーダルな仮想アシスタントを作成する場合でも、テキストと画像のデュアル モダリティに基づいて忠実度の高いグラフィック広告を生成する場合でも、すべては独立したサブモデルを統合し、GPT-4o の優れたインテリジェンスによって推進される完了したタスクには、新しい統合された効率的なソリューションが含まれます。
参考:
- [1] https://openai.com/index/hello-gpt-4o/?ref=blog.roboflow.com
- [2] https://blog.roboflow.com/gpt -4-vision/
- [3] https://www.vellum.ai/blog/analysis-gpt-4o-vs-gpt-4-turbo#task1
以上がGPT-4o と GPT-4 Turbo を 1 つの記事で読むの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7503
7503
 15
1377
52
78
11
19
54
15
1377
52
78
11
19
54

 Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
このサイトは6月27日、JianyingはByteDanceの子会社であるFaceMeng Technologyによって開発されたビデオ編集ソフトウェアであり、Douyinプラットフォームに依存しており、基本的にプラットフォームのユーザー向けに短いビデオコンテンツを作成すると報告しました。 Windows、MacOS、その他のオペレーティング システム。 Jianyingは会員システムのアップグレードを正式に発表し、インテリジェント翻訳、インテリジェントハイライト、インテリジェントパッケージング、デジタルヒューマン合成などのさまざまなAIブラックテクノロジーを含む新しいSVIPを開始しました。価格的には、クリッピングSVIPの月額料金は79元、年会費は599元(当サイト注:月額49.9元に相当)、継続月額サブスクリプションは月額59元、継続年間サブスクリプションは、年間499元(月額41.6元に相当)です。さらに、カット担当者は、ユーザーエクスペリエンスを向上させるために、オリジナルのVIPに登録している人は、
 Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
検索強化生成およびセマンティック メモリを AI コーディング アシスタントに組み込むことで、開発者の生産性、効率、精度を向上させます。 JanakiramMSV 著者の EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG から翻訳。基本的な AI プログラミング アシスタントは当然役に立ちますが、ソフトウェア言語とソフトウェア作成の最も一般的なパターンに関する一般的な理解に依存しているため、最も適切で正しいコードの提案を提供できないことがよくあります。これらのコーディング アシスタントによって生成されたコードは、彼らが解決する責任を負っている問題の解決には適していますが、多くの場合、個々のチームのコーディング標準、規約、スタイルには準拠していません。これにより、コードがアプリケーションに受け入れられるように修正または調整する必要がある提案が得られることがよくあります。
 微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
大規模言語モデル (LLM) は巨大なテキスト データベースでトレーニングされ、そこで大量の現実世界の知識を取得します。この知識はパラメータに組み込まれており、必要なときに使用できます。これらのモデルの知識は、トレーニングの終了時に「具体化」されます。事前トレーニングの終了時に、モデルは実際に学習を停止します。モデルを調整または微調整して、この知識を活用し、ユーザーの質問により自然に応答する方法を学びます。ただし、モデルの知識だけでは不十分な場合があり、モデルは RAG を通じて外部コンテンツにアクセスできますが、微調整を通じてモデルを新しいドメインに適応させることが有益であると考えられます。この微調整は、ヒューマン アノテーターまたは他の LLM 作成物からの入力を使用して実行され、モデルは追加の実世界の知識に遭遇し、それを統合します。
 OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
AIモデルによって与えられた答えがまったく理解できない場合、あなたはそれをあえて使用しますか?機械学習システムがより重要な分野で使用されるにつれて、なぜその出力を信頼できるのか、またどのような場合に信頼してはいけないのかを実証することがますます重要になっています。複雑なシステムの出力に対する信頼を得る方法の 1 つは、人間または他の信頼できるシステムが読み取れる、つまり、考えられるエラーが発生する可能性がある点まで完全に理解できる、その出力の解釈を生成することをシステムに要求することです。見つかった。たとえば、司法制度に対する信頼を築くために、裁判所に対し、決定を説明し裏付ける明確で読みやすい書面による意見を提供することを求めています。大規模な言語モデルの場合も、同様のアプローチを採用できます。ただし、このアプローチを採用する場合は、言語モデルが
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
編集者 | KX 医薬品の研究開発の分野では、タンパク質とリガンドの結合親和性を正確かつ効果的に予測することが、医薬品のスクリーニングと最適化にとって重要です。しかし、現在の研究では、タンパク質とリガンドの相互作用における分子表面情報の重要な役割が考慮されていません。これに基づいて、アモイ大学の研究者らは、初めてタンパク質の表面、3D 構造、配列に関する情報を組み合わせ、クロスアテンション メカニズムを使用して異なるモダリティの特徴を比較する、新しいマルチモーダル特徴抽出 (MFE) フレームワークを提案しました。アライメント。実験結果は、この方法がタンパク質-リガンド結合親和性の予測において最先端の性能を達成することを実証しています。さらに、アブレーション研究は、この枠組み内でのタンパク質表面情報と多峰性特徴の位置合わせの有効性と必要性を実証しています。 「S」で始まる関連研究
 AIなどの市場を開拓するグローバルファウンドリーズがタゴール・テクノロジーの窒化ガリウム技術と関連チームを買収
Jul 15, 2024 pm 12:21 PM
AIなどの市場を開拓するグローバルファウンドリーズがタゴール・テクノロジーの窒化ガリウム技術と関連チームを買収
Jul 15, 2024 pm 12:21 PM
7月5日のこのウェブサイトのニュースによると、グローバルファウンドリーズは今年7月1日にプレスリリースを発行し、自動車とインターネットでの市場シェア拡大を目指してタゴール・テクノロジーのパワー窒化ガリウム(GaN)技術と知的財産ポートフォリオを買収したことを発表した。モノと人工知能データセンターのアプリケーション分野で、より高い効率とより優れたパフォーマンスを探求します。生成 AI などのテクノロジーがデジタル世界で発展を続ける中、窒化ガリウム (GaN) は、特にデータセンターにおいて、持続可能で効率的な電力管理のための重要なソリューションとなっています。このウェブサイトは、この買収中にタゴール・テクノロジーのエンジニアリングチームがGLOBALFOUNDRIESに加わり、窒化ガリウム技術をさらに開発するという公式発表を引用した。 G
 SKハイニックスは8月6日に12層HBM3E、321層NANDなどのAI関連新製品を展示する。
Aug 01, 2024 pm 09:40 PM
SKハイニックスは8月6日に12層HBM3E、321層NANDなどのAI関連新製品を展示する。
Aug 01, 2024 pm 09:40 PM
8月1日の本サイトのニュースによると、SKハイニックスは本日(8月1日)ブログ投稿を発表し、8月6日から8日まで米国カリフォルニア州サンタクララで開催されるグローバル半導体メモリサミットFMS2024に参加すると発表し、多くの新世代の製品。フューチャー メモリおよびストレージ サミット (FutureMemoryandStorage) の紹介。以前は主に NAND サプライヤー向けのフラッシュ メモリ サミット (FlashMemorySummit) でしたが、人工知能技術への注目の高まりを背景に、今年はフューチャー メモリおよびストレージ サミット (FutureMemoryandStorage) に名前が変更されました。 DRAM およびストレージ ベンダー、さらに多くのプレーヤーを招待します。昨年発売された新製品SKハイニックス
