

DiffMap: 高精度地図構築を強化するために LDM を使用する最初のネットワーク

論文のタイトル:
DiffMap: 拡散モデルを使用したマップ事前のマップセグメンテーションの強化
論文の著者:
Peijin Jia、Tuopu Wen、Ziang Luo、Mengmeng Yang、Kun Jiang、クァン・レイ、 Xuewei Tang、Ziyuan Liu、Le Cui、Kehua Sheng、Bo Zhang、Diange Yang
01 背景の紹介
自動運転車の場合、高解像度 (HD) マップは環境への理解を深めるのに役立ちます(知覚) ) 精度とナビゲーションの精度。ただし、手動マッピングには複雑さとコストがかかるという問題があります。この目的を達成するために、現在の研究では、BEV (鳥瞰図) 認識タスクにマップ構築を統合しています。BEV 空間でラスター化された HD マップを構築することは、FCN と同様のものの使用を追加すると理解できます。 (フルボリューム) BEV 特徴を取得した後、製品ネットワークのセグメンテーション ヘッド)。たとえば、HDMapNet は、LSS (Lift、Splat、Shoot) を介してセンサー機能をエンコードし、セマンティック セグメンテーション、インスタンス検出、および方向予測に多重解像度 FCN を使用してマップを構築します。
しかし、現時点では、そのような方法 (ピクセルベースの分類方法) には依然として固有の制限があり、特定の分類属性を無視する可能性が含まれ、これにより中央分離帯の歪みや中断、ぼやけた横断歩道、その他の種類のアーティファクトが発生する可能性があります。図 1(a) に示すように、ノイズが発生します。これらの問題は、地図の構造精度に影響を与えるだけでなく、自動運転システムの下流の経路計画モジュールにも直接影響を与える可能性があります。
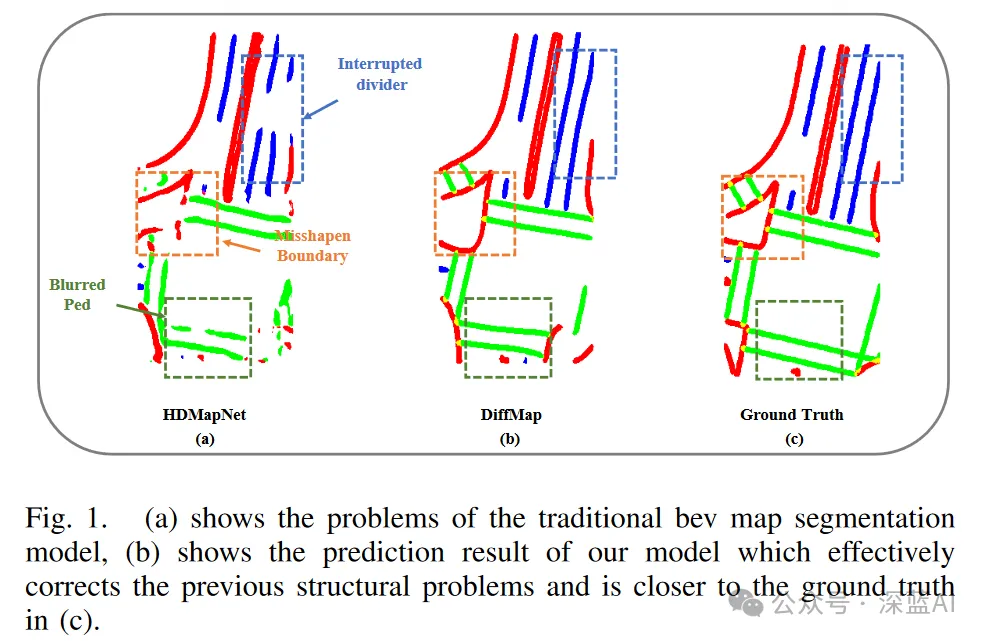
▲ 図1|HDMapNet、DiffMap、GroundTruthの効果の比較
したがって、モデルはHDマップの平行や直線などの構造的な事前情報を考慮することが最善です車線の特徴。一部の生成モデルには、画像の信頼性と固有の特性を捉えるこの機能があります。たとえば、LDM (潜在拡散モデル) は、高忠実度の画像生成において大きな可能性を示し、セグメンテーション強化に関連するタスクにおいてその有効性が証明されています。さらに、制御変数を導入して、特定の制御要件を満たすように画像生成をさらにガイドすることができます。したがって、マップ構造の事前分布を取得するために生成モデルを適用すると、セグメンテーション アーティファクトが削減され、マップ構築のパフォーマンスが向上することが期待されます。
この記事で、著者は DiffMap ネットワークについて言及しました。このネットワークは初めて、既存のセグメンテーション モデルに対してマップ構造化された事前モデリングを実行し、改良された LDM を拡張モジュールとして使用することでプラグ アンド プレイをサポートします。 DiffMap は、ノイズの追加と除去のプロセスを通じて事前にマップを学習して、出力が現在のフレームの観測値と一致することを確認するだけでなく、BEV 機能を制御信号として統合して、出力が現在のフレームの観測値と一致することを確認することもできます。実験結果は、DiffMap がアーティファクトを大幅に削減し、全体的なマップ構築パフォーマンスを向上させながら、よりスムーズで合理的なマップ セグメンテーション結果を効果的に生成できることを示しています。
02 関連作業
2.1 セマンティック マップの構築
従来の高解像度 (HD) マップの構築では、通常、セマンティック マップは LIDAR 点群に基づいて手動または半自動で注釈が付けられます。一般に、グローバルに一貫したマップは SLAM アルゴリズムに基づいて構築され、意味論的な注釈が手動でマップに追加されます。ただし、このアプローチは時間と労力がかかり、マップの更新に大きな課題が生じるため、そのスケーラビリティとリアルタイム パフォーマンスが制限されます。
HDMapNet は、オンボードセンサーを使用してローカルセマンティックマップを動的に構築する方法を提案しています。 LIDAR 点群とパノラマ画像の特徴を鳥瞰図 (BEV) 空間にエンコードし、3 つの異なるヘッドを使用してデコードし、最終的にベクトル化されたローカル セマンティック マップを生成します。 SuperFusion は、長距離の高精度セマンティック マップの構築、LIDAR 深度情報を使用して画像深度推定を強化すること、および画像特徴を使用して長距離 LIDAR 特徴予測をガイドすることに重点を置いています。次に、HDMapNet と同様のマップ検出ヘッドを使用して、セマンティック マップを取得します。 MachMap はタスクをポリライン検出とポリゴン インスタンス セグメンテーションに分割し、後処理を使用してマスクを調整して最終結果を取得します。その後の研究は、ベクトル化された高精細地図を直接取得するためのエンドツーエンドのオンライン マッピングに焦点を当てています。手動の注釈を使用しないセマンティック マップの動的な構築により、構築コストが効果的に削減されます。
2.2 セグメンテーションと検出に適用される拡散モデル
ノイズ除去拡散確率モデル (DDPM) は、マルコフ連鎖に基づく生成モデルの一種で、画像生成などの分野で優れたパフォーマンスを示し、段階的に拡張されています。セグメンテーションや検出などのさまざまなタスクに使用できます。 SegDiff は拡散モデルを画像セグメンテーション タスクに適用します。このタスクでは、使用される UNet エンコーダーがさらに 3 つのモジュール (E、F、G) に分離されます。モジュール G と F はそれぞれ入力画像 I とセグメンテーション マップをエンコードし、これらは E で加算的にマージされ、セグメンテーション マップを反復的に改良します。 DDPMS は、基本セグメンテーション モデルを使用して初期事前予測を生成し、拡散モデルを使用して事前予測を改良します。 DiffusionDet は、拡散モデルをターゲット検出フレームワークに拡張し、ノイズ ボックスからターゲット ボックスへのノイズ除去拡散プロセスとしてターゲット検出をモデル化します。
拡散モデルは自動運転の分野でも使用されており、幾何学的制約を使用して街路シーンを合成する MagicDrive や、拡散モデルをマルチエージェントの動作予測問題に拡張する Motiondiffuser などがあります。
2.3 事前マップ
現在、事前情報 (明示的な標準地図情報と暗黙的な時間情報を含む) 不確実性を利用してモデルの堅牢性を強化し、車両センサーの負荷を軽減する方法がいくつかあります。 MapLite2.0 は、標準解像度 (SD) の以前の地図を出発点として使用し、それをオンボード センサーと組み合わせて、ローカルの高解像度地図をリアルタイムで推論します。 MapEx と SMERF は、標準の地図データを活用して、車線の認識とトポロジの理解を向上させます。 SMERF は、Transformer ベースの標準地図エンコーダを採用して車線境界線と車線タイプをエンコードし、標準地図情報とセンサーベースの鳥瞰図 (BEV) 機能の間の相互注意を計算して標準地図情報を統合します。 NMP は、過去の地図以前のデータと現在の認識データを組み合わせることで、自動運転車に長期記憶機能を提供します。 MapPrior は、識別モデルと生成モデルを組み合わせ、既存のモデルに基づいて生成された予備予測を予測フェーズ中に事前予測としてエンコードし、生成モデルの離散潜在空間を注入して、生成モデルを使用して予測を改良します。 PreSight は、以前の旅行からのデータを使用して、都市規模の神経放射線場を最適化し、神経事前分布を生成し、その後のナビゲーションでのオンライン認識を強化します。
03 メソッド分析
3.1 準備


3.2 全体的なアーキテクチャ
図2に示すように。デコーダとして、DiffMap は拡散モデルをセマンティック マップ セグメンテーション モデルに組み込み、周囲のマルチビュー画像と LiDAR 点群を入力として受け取り、それらを BEV 空間にエンコードして、融合された BEV 特徴を取得します。次に、DiffMap をデコーダとして使用してセグメンテーション マップを生成します。 DiffMap モジュールでは、BEV 特徴がノイズ除去プロセスをガイドする条件として使用されます。
 ▲ 図2|DiffMapアーキテクチャ ©️[Deep Blue AI]でコンパイルされた
▲ 図2|DiffMapアーキテクチャ ©️[Deep Blue AI]でコンパイルされた
◆セマンティックマップ構築のベースライン: ベースラインは主にBEVエンコーダ-デコーダパラダイムに従います。エンコーダ部分は、入力データ (LiDAR および/またはカメラ データ) から特徴を抽出し、それを高次元表現に変換する役割を果たします。同時に、デコーダは通常、高次元の特徴表現を対応するセグメンテーション マップにマッピングするセグメンテーション ヘッドとして機能します。ベースラインは、フレームワーク全体でスーパーバイザーとコントローラーという 2 つの主要な役割を果たします。スーパーバイザとして、ベースラインは補助的な監視としてセグメンテーション結果を生成します。同時に、コントローラーとして、中間の BEV 特性を条件付き制御変数として提供し、拡散モデルの生成プロセスをガイドします。
◆DiffMap モジュール: LDM に続いて、著者はベースライン フレームワークのデコーダとして DiffMap モジュールを紹介します。 LDM は主に、画像認識圧縮モジュール (VQVAE など) と UNet を使用して構築された拡散モデルの 2 つの部分で構成されます。まず、エンコーダはマップ セグメンテーションのグラウンド トゥルースを潜在空間にエンコードします。ここで、 は潜在空間の低次元を表します。続いて、低次元の潜在変数空間で拡散とノイズ除去が実行され、デコーダを使用して潜在空間を元のピクセル空間に復元します。
まず、拡散プロセスを通じてノイズを追加し、各タイム ステップでノイズ ポテンシャル マップを取得します。その後、ノイズ除去プロセス中に、UNet がノイズ予測のバックボーン ネットワークとして機能します。セグメンテーション結果の監視部分を強化するために、DiffMap モデルがトレーニング中にインスタンス関連の予測の意味論的特徴を直接提供することが期待されます。したがって、著者は UNet ネットワーク構造を 2 つのブランチに分割し、1 つのブランチは従来の拡散モデルなどのノイズの予測に使用され、もう 1 つのブランチは潜在空間のノイズの予測に使用されます。
図 3 に示すとおり。潜在マップ予測を取得した後、意味論的特徴マップとして元のピクセル空間に復号化されます。次に、HDMapNet が提案する方法に従ってインスタンス予測をそれらから取得でき、セマンティック セグメンテーション、インスタンスの埋め込み、およびレーンの方向という 3 つの異なるヘッドの予測を出力できます。これらの予測は後処理ステップで使用され、マップがベクトル化されます。

▲図3|ノイズ除去モジュール
プロセス全体は条件付き生成プロセスであり、マップ セグメンテーションの結果は現在のセンサー入力に基づいて取得されます。結果の確率分布は次のようにモデル化できます。 ここで、 はマップ分割結果を表し、 は条件付き制御変数、つまり BEV 特徴を表します。著者はここで制御変数を統合するために 2 つの方法を使用します。まず、BEV 特徴と BEV 特徴は空間領域で同じカテゴリとスケールを持っているため、式 5 に示すように、潜在空間サイズに調整されてから、ノイズ除去プロセスの入力として連結されます。
第二に、クロスアテンション メカニズムは、キー/値およびクエリとして UNet ネットワークの各層に統合されます。クロスアテンションモジュールの式は以下のとおりです:
3.3 具体的な実装
◆トレーニング:

◆推論:

04 実験
4.1 実験の詳細
◆データセット: nuScenes データセットで DiffMap を検証します。 nuScenes データセットには、1000 シーンのマルチビュー イメージと点群が含まれており、そのうち 700 シーンがトレーニングに使用され、150 シーンが検証に使用され、150 シーンがテストに使用されます。 nuScenes データセットには、注釈付きの HD マップ セマンティック ラベルも含まれています。
◆アーキテクチャ: カメラブランチのバックボーンネットワークとして ResNet-101 を使用し、モデルの LiDAR ブランチバックボーンネットワークとして PointPillars を使用します。ベースライン モデルのセグメンテーション ヘッドは、ResNet-18 ベースの FCN ネットワークです。オートエンコーダーには VQVAE が採用されており、モデルは nuScenes のセグメント化された地図データセットで事前トレーニングされ、地図の特徴を抽出して地図を基本潜在空間に圧縮します。最後に、UNet を使用して拡散ネットワークを構築します。
◆トレーニングの詳細: AdamW オプティマイザーを使用して、30 エポックの間 VQVAE モデルをトレーニングします。使用される学習率スケジューラは LambdaLR で、減衰係数 0.95 の指数関数的減衰モードで学習率を徐々に低下させます。初期学習率は に設定され、バッチ サイズは 8 です。次に、AdamW オプティマイザーを使用して、初期学習率 2e-4 で 30 エポックの間、拡散モデルを最初からトレーニングしました。 MultiStepLR スケジューラーが採用されており、指定されたマイルストーン時点 (0.7、0.9、1.0) およびさまざまなトレーニング段階での 1/3 のスケーリング係数に従って学習率を調整します。最後に、BEV セグメンテーションの結果は 0.15m の解像度に設定され、LiDAR 点群がボクセル化されます。 HDMapNet の検出範囲は [-30m, 30m]×[-15m, 15m]m であるため、対応する BEV マップ サイズは 400×200 ですが、Superfusion は [0m, 90m]×[-15m, 15m] を使用して 600 を取得します。 × 200 件の結果。 LDM の次元制約 (VAE および UNet では 8 倍のダウンサンプリング) のため、セマンティック グラウンド トゥルース マップのサイズは 64 の倍数にパディングする必要があります。
◆推論詳細:現在のBEV特徴条件でノイズマップのノイズ除去処理を20回実行することで予測結果が得られます。 3 つのサンプルの平均が最終的な予測結果として使用されます。
4.2 評価指標
は、主にマップのセマンティックセグメンテーションとインスタンス検出タスクに対して評価されます。そして、主に、車線境界線、車線分離帯、横断歩道という 3 つの静的な地図要素に焦点を当てています。


4.3 評価結果
表1にセマンティックマップセグメンテーションのIoUスコアの比較を示します。 DiffMap はすべての区間で大幅な改善を示し、特に車線分離帯や横断歩道で最良の結果が得られました。
 ▲表1|IoUスコアの比較
▲表1|IoUスコアの比較
表2に示すように、DiffMap方式では平均精度(AP)も大幅に向上しており、DiffMapの有効性が実証されています。
 ▲表2|MAPスコア比較
▲表2|MAPスコア比較
表 3 に示すように、DiffMap パラダイムが HDMapNet に統合されると、カメラのみを使用する場合でも、カメラとライダーの融合方法を使用する場合でも、DiffMap が HDMapNet のパフォーマンスを向上させることができることがわかります。これは、DiffMap メソッドが長距離および近距離の検出を含むさまざまなセグメンテーション タスクに有効であることを示しています。ただし、境界の場合、DiffMap はうまく機能しません。境界の形状構造が固定されておらず、予測できない歪みが多く、先験的な構造特徴を捕捉することが困難であるためです。
 ▲表3|定量分析結果
▲表3|定量分析結果
4.4 アブレーション実験
表4は、VQVAEのさまざまなダウンサンプリング係数が検出結果に及ぼす影響を示しています。ダウンサンプリング係数が 4、8、および 16 の場合の DiffMap の動作を分析すると、ダウンサンプリング係数を 8x に設定すると最良の結果が得られることがわかります。
 ▲表4|アブレーション実験結果
▲表4|アブレーション実験結果
さらに、表5に示すように、著者はインスタンス関連の予測モジュールを削除した場合のモデルへの影響も測定しました。実験では、この予測を追加すると IOU がさらに改善されることが示されています。

▲表5|アブレーション実験結果(予測モジュール含むか否か)
4.5 可視化
図4は、複雑なシーンにおけるDiffMapとベースライン(HDMapNet-fusion)の比較を示しています。ベースライン セグメンテーションの結果が、要素内の形状特性と一貫性を無視していることは明らかです。対照的に、DiffMap はこれらの問題を修正し、マップ仕様とよく一致したセグメンテーション出力を生成する機能を示しています。具体的には、(a)、(b)、(d)、(e)、(h)、および (l) の場合、DiffMap は不正確に予測された横断歩道を効果的に補正します。 (c)、(d)、(h)、(i)、(j)、および (l) の場合、DiffMap は不正確な境界を完成または削除し、結果を現実的な境界ジオメトリに近づけます。さらに、(b)、(f)、(g)、(h)、(k)、(l) の場合、DiffMap は分割線の切れの問題を解決し、隣接する要素の平行性を保証します。
 ▲図4|定性分析結果
▲図4|定性分析結果
本論文で著者が設計したDiffMapネットワークは、潜在拡散モデルを利用してマップ構造事前分布を学習する新しい手法であり、これにより、従来のマップ セグメンテーション モデルが採用されます。この方法は、任意のマップ セグメンテーション モデルの補助ツールとして使用でき、その予測結果は遠距離と近距離の両方の検出シナリオで大幅に改善されます。この方法は拡張性が高いため、他のタイプの事前情報を調査するのに適しています。たとえば、SD マップ事前情報を DiffMap の 2 番目のモジュールに統合して、パフォーマンスを向上させることができます。ベクトル化された地図構築の進歩は今後も続くことが予想されます。
以上がDiffMap: 高精度地図構築を強化するために LDM を使用する最初のネットワークの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1664
1664
 14
1423
52
1317
25
1268
29
1242
24
14
1423
52
1317
25
1268
29
1242
24

 自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
昨日の面接で、ロングテール関連の質問をしたかと聞かれたので、簡単にまとめてみようと思いました。自動運転のロングテール問題とは、自動運転車におけるエッジケース、つまり発生確率が低い考えられるシナリオを指します。認識されているロングテール問題は、現在、単一車両のインテリジェント自動運転車の運用設計領域を制限している主な理由の 1 つです。自動運転の基礎となるアーキテクチャとほとんどの技術的問題は解決されており、残りの 5% のロングテール問題が徐々に自動運転の開発を制限する鍵となってきています。これらの問題には、さまざまな断片的なシナリオ、極端な状況、予測不可能な人間の行動が含まれます。自動運転におけるエッジ シナリオの「ロング テール」とは、自動運転車 (AV) におけるエッジ ケースを指します。エッジ ケースは、発生確率が低い可能性のあるシナリオです。これらの珍しい出来事
 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI は確かに数学を変えつつあります。最近、この問題に細心の注意を払っている陶哲軒氏が『米国数学協会会報』(米国数学協会会報)の最新号を送ってくれた。 「機械は数学を変えるのか?」というテーマを中心に、多くの数学者が意見を述べ、そのプロセス全体は火花に満ち、ハードコアで刺激的でした。著者には、フィールズ賞受賞者のアクシャイ・ベンカテシュ氏、中国の数学者鄭楽軍氏、ニューヨーク大学のコンピューター科学者アーネスト・デイビス氏、その他業界で著名な学者を含む強力な顔ぶれが揃っている。 AI の世界は劇的に変化しています。これらの記事の多くは 1 年前に投稿されたものです。
 Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google が推進する JAX のパフォーマンスは、最近のベンチマーク テストで Pytorch や TensorFlow のパフォーマンスを上回り、7 つの指標で 1 位にランクされました。また、テストは最高の JAX パフォーマンスを備えた TPU では行われませんでした。ただし、開発者の間では、依然として Tensorflow よりも Pytorch の方が人気があります。しかし、将来的には、おそらくより大規模なモデルが JAX プラットフォームに基づいてトレーニングされ、実行されるようになるでしょう。モデル 最近、Keras チームは、ネイティブ PyTorch 実装を使用して 3 つのバックエンド (TensorFlow、JAX、PyTorch) をベンチマークし、TensorFlow を使用して Keras2 をベンチマークしました。まず、主流のセットを選択します
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
この 1 か月間、いくつかのよく知られた理由により、私は業界のさまざまな教師やクラスメートと非常に集中的な交流をしてきました。この交換で避けられない話題は当然、エンドツーエンドと人気の Tesla FSDV12 です。この機会に、現時点での私の考えや意見を整理し、皆様のご参考とご議論に役立てたいと思います。エンドツーエンドの自動運転システムをどのように定義するか、またエンドツーエンドで解決することが期待される問題は何でしょうか?最も伝統的な定義によれば、エンドツーエンド システムとは、センサーから生の情報を入力し、関心のある変数をタスクに直接出力するシステムを指します。たとえば、画像認識では、従来の特徴抽出 + 分類子方式と比較して、CNN はエンドツーエンドと言えます。自動運転タスクでは、各種センサー(カメラ/LiDAR)からのデータを入力
