

単なる 3D ガウス以上のもの!最先端の 3D 再構成技術の最新概要

以前に書かれたものおよび著者の個人的な理解
画像ベースの 3D 再構成は、一連の入力画像からオブジェクトまたはシーンの 3D 形状を推測することを伴う難しいタスクです。学習ベースの手法は、3D形状を直接推定できることから注目を集めています。このレビュー ペーパーは、これまでにない新しいビューの生成など、最先端の 3D 再構成技術に焦点を当てています。入力タイプ、モデル構造、出力表現、トレーニング戦略など、ガウス スプラッシュ メソッドの最近の開発の概要が提供されます。未解決の課題と今後の方向性についても議論します。この分野の急速な進歩と 3D 再構成手法を強化する数多くの機会を考慮すると、アルゴリズムを徹底的に調査することが重要であると思われます。したがって、この研究は、ガウス散乱の最近の進歩の包括的な概要を提供します。
(親指で上にスワイプし、上部のカードをクリックしてフォローしてください。操作全体にかかる時間はわずか 1.328 秒で、その後、将来的に無料のものはすべて削除されます 、適切なコンテンツがある場合に備えて 役に立ちますか~)
3D 再構成と新しいビュー合成の紹介
3D 再構成と NVS は、リアルなキャプチャーとレンダリングを目的としたコンピューター グラフィックスの 2 つの密接に関連した分野です物理的なシーンの 3D 表現。 3D 再構成には、通常は異なる視点から撮影された一連の 2D 画像から幾何学的情報や外観情報を抽出することが含まれます。 3D スキャンには多くの技術がありますが、さまざまな 2D 画像をキャプチャすることは、3D 環境に関する情報を収集するための非常にシンプルで計算コストが低い方法です。この情報は、シーンの 3D モデルを作成するために使用できます。このモデルは、仮想現実 (VR) アプリケーション、拡張現実 (AR) オーバーレイ、コンピューター支援設計 (CAD) モデリングなど、さまざまな目的に使用できます。 。
一方、NVS は、以前に取得した 3D モデルからシーンの新しい 2D ビューを生成することに重点を置いています。これにより、元の画像がその角度から撮影されていない場合でも、任意の視点からのシーンのフォトリアリスティックな画像を作成できます。深層学習の最近の進歩により、3D 再構成と NVS が大幅に向上しました。深層学習モデルを使用すると、画像から 3D ジオメトリと外観を効率的に抽出できます。また、このようなモデルを使用して、3D モデルから現実的な新しいビューを生成することもできます。その結果、これらの技術はさまざまな用途でますます普及しており、将来的にはさらに重要な役割を果たすことが期待されています。
このセクションでは、3D データを保存または表現する方法を紹介し、次にこのタスクに最も一般的に使用される公開データセットを紹介し、その後、主にガウス スプラッシュに焦点を当てたさまざまなアルゴリズムについて詳しく説明します。
3D データ表現
体積寸法を含む 3 次元データの複雑な空間的性質により、ターゲットと環境の詳細な表現が提供されます。これは、さまざまな研究分野で没入型シミュレーションや正確なモデルを作成するために非常に重要です。 3 次元データの多次元構造により、奥行き、幅、高さの組み合わせが可能になり、建築設計や医療画像技術などの分野で大きな進歩がもたらされます。
データ表現の選択は、多くの 3D 深層学習システムの設計において重要な役割を果たします。点群にはグリッド状の構造がないため、通常は直接畳み込むことができません。一方、グリッド状の構造を特徴とするボクセル表現では、多くの場合、高い計算メモリ要件が発生します。
3D 表現の進化は、3D データまたはモデルの保存方法に伴います。最も一般的に使用される 3D データ表現は、従来の方法と新しい方法に分類できます。
従来のアプローチ:
- 点群
- メッシュ
- ボクセル

新しいアプローチ:
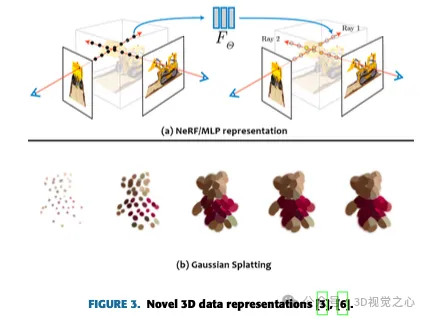
- ニューラルネットワーク/多層パーセプトロン(MLP)
- ガウススプラット
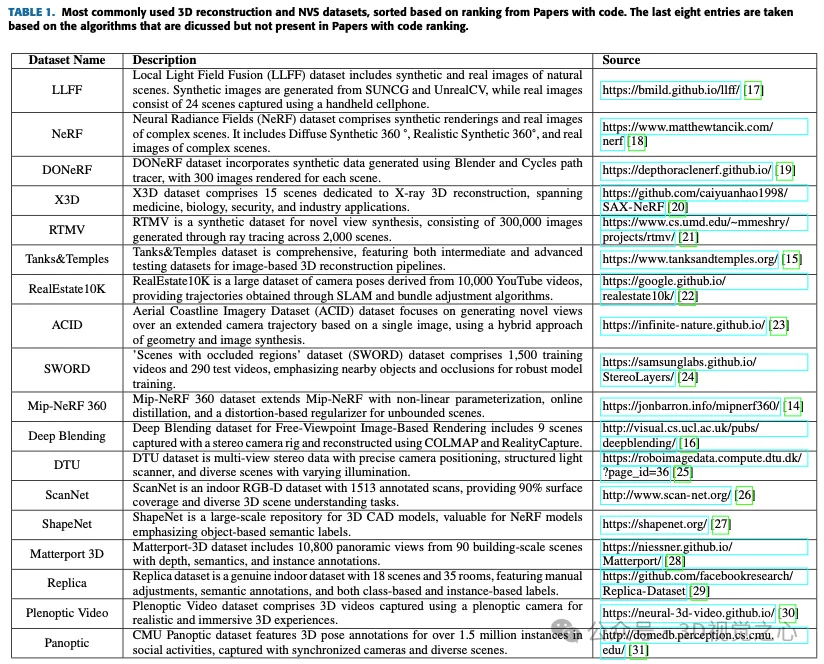
データセット
NVS テクノロジーによる 3 次元再構成
この分野の現在の進歩を評価するために、関連する学術研究を特定し、慎重にレビューする文献調査が実施されました。分析は、3D 再構成と NVS という 2 つの主要な領域に特に焦点を当てています。複数のカメラ画像からの 3D 体積再構成の開発は数十年に及び、コンピュータ グラフィックス、ロボット工学、医療画像処理などに多様に応用されています。次のセクションでは、このテクノロジーの現状について説明します。
写真測量: 1980 年代以来、ステレオ画像ペア内の対応する点を自動的に識別する高度な写真測量とステレオ ビジョン テクノロジーが登場しました。フォトグラメトリは、写真とコンピュータ ビジョンを組み合わせてオブジェクトやシーンの 3D モデルを生成する方法です。さまざまな角度から画像をキャプチャし、Agisoft Metashape などのソフトウェアを利用してカメラの位置を推定し、点群を生成する必要があります。この点群はテクスチャ付き 3D メッシュに変換され、再構築されたオブジェクトやシーンの詳細で写真のようにリアルな視覚化を作成できるようになります。
動きからの構造: 1990 年代に SFM テクノロジーが注目を集め、2D 画像シーケンスから 3D 構造とカメラの動きを再構築できるようになりました。 SFM は、一連の 2D 画像からシーンの 3D 構造を推定するプロセスです。 SFM では、画像間の点相関が必要です。複数の画像内の特徴を照合するか点を追跡することで対応する点を見つけ、三角測量して 3D 位置を見つけます。
深層学習: 近年、深層学習技術、特に畳み込みニューラル ネットワーク (CNN) が統合されています。 3D 再構成では、深層学習ベースの手法が加速しています。最も注目すべきは、3D シーンの理解と再構築のために設計されたニューラル ネットワーク アーキテクチャである 3D Occupancy Network です。これは、3D 空間を小さな体積単位、つまりボクセルに分割することによって機能し、各ボクセルはターゲットが含まれているか空の空間かを表します。これらのネットワークは、3D 畳み込みニューラル ネットワークなどの深層学習技術を使用してボクセルの占有率を予測するため、ロボット工学、自動運転車、拡張現実、3D シーンの再構成などのアプリケーションにとって価値があります。これらのネットワークは、畳み込みとトランスフォーマーに大きく依存しています。これらは、衝突回避、経路計画、物理世界とのリアルタイムの対話などのタスクに不可欠です。さらに、3D 占有ネットワークは不確実性を推定できますが、動的または複雑なシーンを扱う場合には計算上の制限がある可能性があります。ニューラル ネットワーク アーキテクチャの進歩により、その精度と効率が向上し続けています。
神経放射線分野: 2020 年に開始された NeRF は、ニューラル ネットワークと古典的な 3 次元再構成原理を組み合わせたもので、コンピューター ビジョンとグラフィックスで大きな注目を集めています。ボリューム関数をモデル化し、ニューラル ネットワークを通じて色と密度を予測することで、詳細な 3D シーンを再構築します。 NeRF はコンピュータ グラフィックスや仮想現実で広く使用されています。最近、NeRF は広範な研究を通じて精度と効率を向上させました。最近の研究では、水中シナリオにおける NeRF の適用可能性も調査されています。 3D シーン ジオメトリの堅牢な表現を提供する一方で、計算要件などの課題が依然として存在します。今後の NeRF 研究では、解釈可能性、リアルタイム レンダリング、斬新なアプリケーション、スケーラビリティに焦点を当て、仮想現実、ゲーム、ロボット工学への道を開く必要があります。
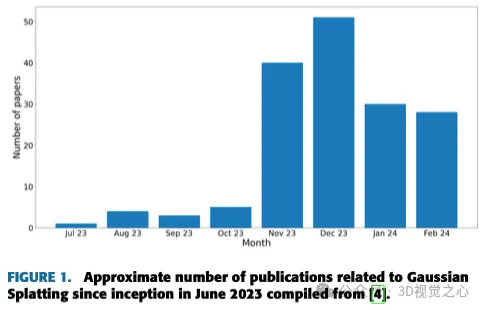
ガウス散乱: ついに 2023 年に、3D ガウス散乱が新しいリアルタイム 3D レンダリング テクノロジとして登場します。次のセクションでは、このアプローチについて詳しく説明します。
ガウス スプラッティングの基本
ガウス スプラッシュは、多くの 3D ガウスまたはパーティクルを使用して 3D シーンを描写し、それぞれに位置、方向、スケール、不透明度、色の情報が備わっています。これらのパーティクルをレンダリングするには、パーティクルを 2D 空間に変換し、最適なレンダリングができるように戦略的に整理します。
図 4 は、ガウス スプラッシュ アルゴリズムのアーキテクチャを示しています。元のアルゴリズムでは、次の手順が実行されます:
- モーションからの構造
- ガウス スプラットへの変換
- トレーニング
- 微分可能なガウス ラスタライゼーション
最先端のアルゴリズム
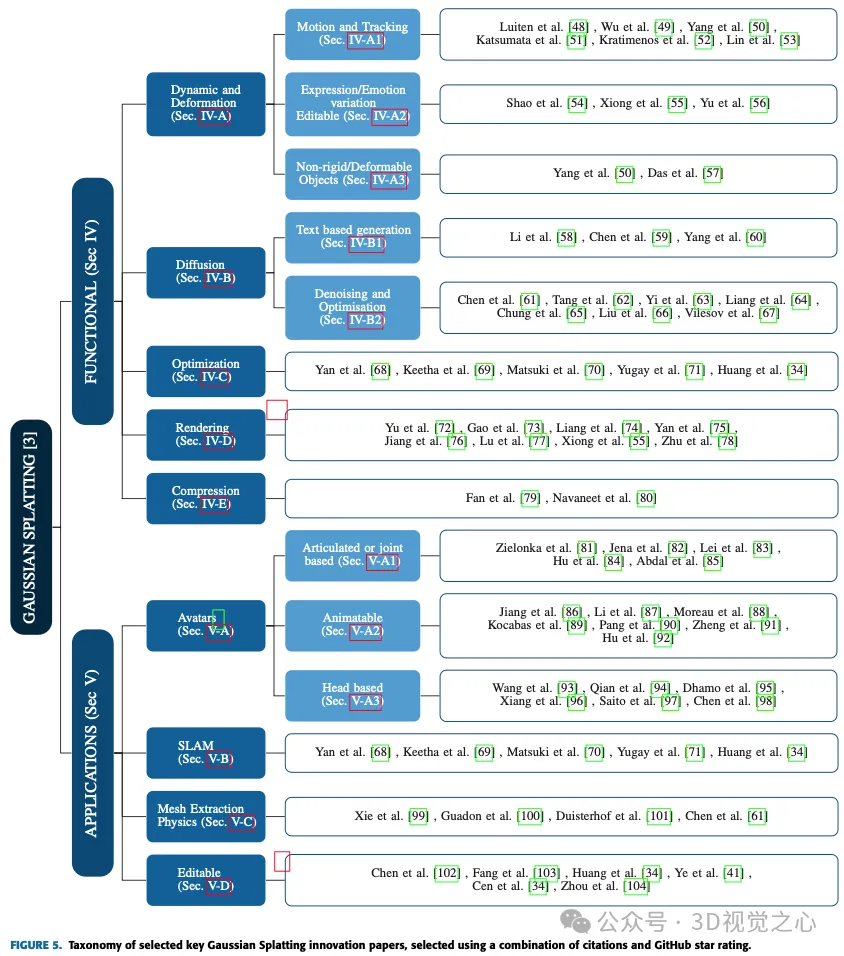
次の 2 つのセクションでは、次のようになります。ガウス スプラッシュのさまざまなアプリケーションと進歩を調査し、自動運転、アバター、圧縮、拡散、ダイナミクスと変形、編集、テキストベースの生成、メッシュ抽出と物理学、正則化と最適化、レンダリング、スパース表現、およびさまざまな分野での使用法を詳しく調べました。 Simultaneous Localization and Mapping (SLAM) などの分野での実装。各サブカテゴリを検討して、特定の課題に対処し、これらの多様な分野で大きな進歩を達成する際のガウス スプラッシュ法の多用途性についての洞察を提供します。図 5 は、すべてのメソッドの完全なリストを示しています。
機能の進歩
このセクションでは、ガウス スプラッシュ アルゴリズムが最初に導入されて以来、機能面での進歩を検証します。
ダイナミクスと変形
3D 共分散行列のすべてのパラメーターが入力画像のみに依存する一般的なガウス スプラッシュと比較して、この場合、時間の経過に伴うスプラッシュのダイナミクスをキャプチャするために、一部のパラメーターは依存します。時間またはタイムステップ通りに。たとえば、位置はタイム ステップまたはフレームに依存します。この位置は、時間的に一貫した方法で次のフレームによって更新できます。また、アバターの表情の変化や非剛体への力の適用などの特定の効果を実現するために、レンダリング中の各タイム ステップでガウス分布を編集または伝播するために使用できる、基礎となるエンコーディングを学習することもできます。図 6 は、いくつかのダイナミクスおよび変形ベースの方法を示しています。
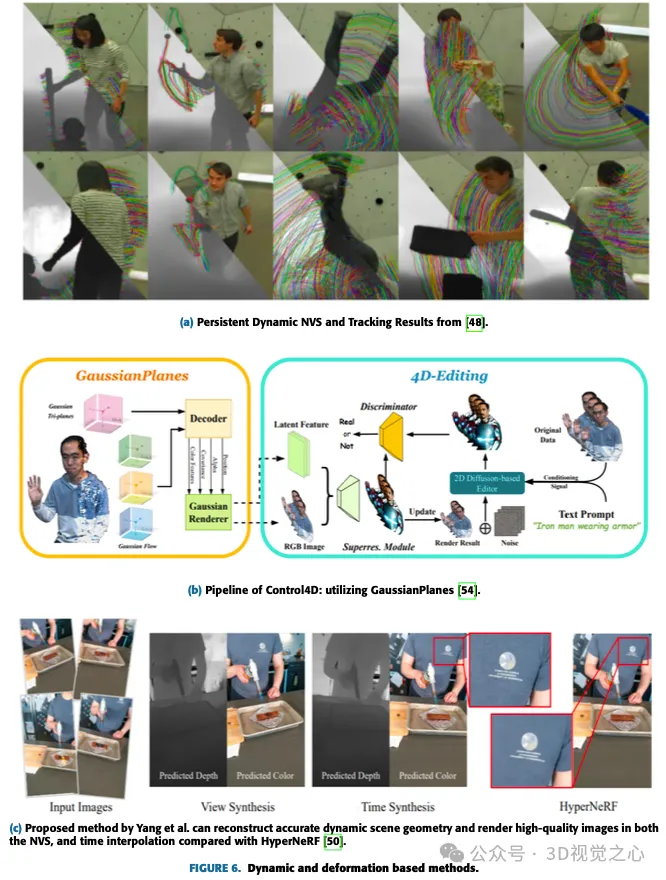
動的で変形可能なモデルは、元のガウス スプラッシュ表現にわずかな変更を加えることで簡単に表現できます:

モーションとトラッキング
動的ガウス スプラッシュに関連する作業のほとんどが 3D ガウスに拡張タイム ステップごとに個別のスプラッシュを生成するのではなく、タイム ステップ全体でモーションを追跡します。勝俣らは、位置のフーリエ近似と回転四元数の線形近似を提案しました。
Luiten らの論文では、動的なシーンのすべての 3D ポイントの完全な 6 自由度をキャプチャする方法が紹介されています。ローカル剛性制約を組み込むことにより、動的 3D ガウスは一貫した空間回転を表現し、対応やストリーミング入力を必要とせずに高密度の 6-DOF 追跡と再構成を可能にします。この方法は 2D 追跡において PIP よりも優れており、中央軌道誤差が 10 倍低く、軌道精度が高く、100% の生存率を達成します。この多用途な表現により、4D ビデオ編集、一人称視点の合成、動的なシーン生成などのアプリケーションが容易になります。
Lin らは、各ガウス点の属性変形をモデル化するように明示的に設計された新しい Dual Domain Deformation Model (DDDM) を導入しました。このモデルは、周波数領域ではフーリエ級数近似を使用し、時間領域では多項式近似を使用して、時間依存の残差を捕捉します。 DDDM は、フレームごとに個別の 3D ガウス スプラッシュ (3D-GS) モデルをトレーニングする必要がなく、複雑なビデオ シーンでの変形の処理に優れています。特に、離散ガウス ポイントの明示的変形モデリングは、静的 3D 再構築のためのオリジナルの 3D-GS と同様に、高速トレーニングと 4D シーン レンダリングを保証します。このアプローチでは効率が大幅に向上し、3D-GS モデリングと比較してトレーニングがほぼ 5 倍速くなります。ただし、最終レンダリングで忠実度の高い薄い構造を維持するには改善の余地があります。
表現や感情のバリエーションとアバターでの編集可能
Shao らは、3 次元時空間での平面ベースの分解によって実現される 4D 表現である GaussianPlanes を導入し、4D 編集の効率を向上させました。さらに、Control4D は 4D ジェネレーターを利用して、一貫性のない写真の連続作成スペースを最適化し、一貫性と品質を向上させます。提案された方法では、GaussianPlanes を使用して 4D ポートレート シーンの暗黙的表現をトレーニングし、ガウス レンダリングを使用して潜在特徴と RGB 画像にレンダリングします。 Generative Adversarial Network (GAN) ベースのジェネレーターと 2D 拡散ベースのエディターがデータセットを改良し、区別するために本物の画像と偽の画像を生成します。判別結果は、ジェネレーターとディスクリミネーターの反復更新に寄与します。ただし、このアプローチは、フロー表現を備えた正準ガウス点群に依存しているため、高速かつ広範な非剛体モーションを処理する際に課題に直面しています。このメソッドは ControlNet の影響を受けるため、編集が大まかなレベルに制限され、表現やアクションの正確な編集ができなくなります。さらに、編集プロセスには反復的な最適化が必要であり、単一ステップのソリューションがありません。
非剛体または変形可能なオブジェクト
暗黙的なニューラル表現は、動的なシーンの再構築とレンダリングに大きな変化をもたらします。しかし、現代の動的ニューラル レンダリング手法は、複雑な詳細をキャプチャし、動的シーンのリアルタイム レンダリングを達成する際に課題に直面しています。
これらの課題に対処するために、Yang らは、高忠実度の単眼動的シーン再構成のための変形可能な 3D ガウスを提案しました。新しい変形可能な3D-GS手法を提案する。この方法では、単眼の動的シーン用に特別に設計された変形フィールドを備えた正準空間で学習された 3D ガウスを利用します。この方法では、実世界の単眼の動的シーンに合わせて調整されたアニーリング スムーズ トレーニング (AST) メカニズムが導入され、追加のトレーニング オーバーヘッドを導入することなく、時間的補間タスクに対する誤ったポーズの影響を効果的に解決します。 Deformable 3D Gaussian は、差分ガウス ラスタライザーを使用することにより、レンダリング品質を向上させるだけでなく、リアルタイム速度も実現し、両方の面で既存の方法を上回ります。この方法は、NVS などのタスクに適していることが証明されており、ポイントベースの性質によりポストプロダクション タスクに多用途性を提供します。実験結果では、この方法の優れたレンダリング効果とリアルタイム パフォーマンスが強調され、動的シーン モデリングにおけるその有効性が確認されました。
DIFFUSION
拡散とガウス スプラッシュは、テキストの説明/ヒントから 3D オブジェクトを生成する強力なテクニックです。これは、拡散モデルとガウス散乱という 2 つの異なる方法の利点を組み合わせたものです。拡散モデルは、ノイズの多い入力から画像を生成する方法を学習するニューラル ネットワークです。モデルに一連のよりクリーンな画像を供給することで、モデルは画像破損のプロセスを逆転させることを学習し、最終的には完全にランダムな入力からクリーンな画像を生成します。モデルは単語と対応する視覚的特徴を関連付けることを学習できるため、これを使用してテキストの説明から画像を生成できます。拡散とガウス スプラッシュを備えたテキストから 3D へのパイプラインは、最初に拡散モデルを使用してテキスト記述から初期 3D 点群を生成することによって機能します。次に、ガウス散乱を使用して、点群を一連のガウス球に変換します。最後に、ガウス球がレンダリングされて、ターゲットの 3D 画像が生成されます。
テキストベースの生成
Yi らの研究では、ガウス分割を通じて 3D と 2D の拡散モデルをシームレスに接続し、3D の一貫性と複雑なディテールの生成を保証するテキストから 3D への手法である Gaussian Dreamer を導入しています。図 7 は、画像を生成するための提案されたモデルを示しています。コンテンツをさらに充実させるために、初期化された 3D ガウスを補うためにノイズ ポイントの増加と色の摂動が導入されます。この手法はシンプルかつ効果的であり、単一の GPU で 15 分以内に 3D インスタンスを生成するという特徴があり、従来の手法と比較して速度に優れています。生成された 3 次元インスタンスはリアルタイムで直接レンダリングできるため、この方法の実用性が強調されます。全体的なフレームワークには、事前の 3D 拡散モデルを使用した初期化と 2D 拡散モデルを使用した最適化が含まれており、両方の拡散モデルの利点を活用することで、テキスト キューから高品質で多様な 3D アセットを作成することができます。
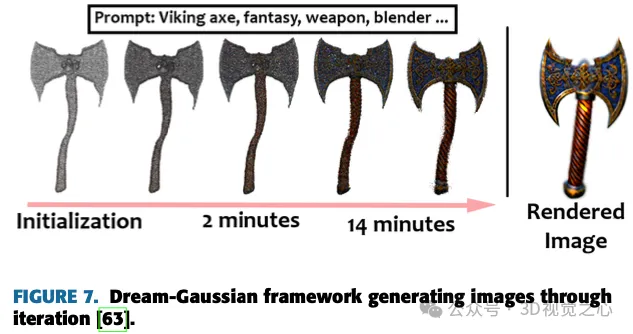
Chen らは、3D ガウスを表現として利用する Text-to-3D 生成方法である、Gaussian Scattering-Based Text-to-3D Generation (GSGEN) を提案しました。幾何学的事前分布を活用することで、テキストから 3D への生成におけるガウス散乱の独自の利点を強調します。 2 段階の最適化戦略では、2D 拡散と 3D 拡散の共同ガイダンスを組み合わせて、ジオメトリの最適化で一貫した大まかな構造を形成し、その後、コンパクトさに基づいた外観の洗練で高密度化します。
ノイズ除去と最適化
Li らの GaussianDiffusion フレームワークは、新しいテキストから 3D へのアプローチを表し、ガウス スプラッシュとランジュバン動的拡散モデルを活用してレンダリングを高速化し、比類のないリアリズムを実現します。構造化ノイズの導入により、マルチビュー ジオメトリの課題が解決され、変分ガウス散乱モデルにより収束の問題とアーティファクトが軽減されます。現在の結果はリアリズムの向上を示していますが、進行中の研究は、変分ガウスによってもたらされるぼやけやかすみを改良してさらに強化することを目的としています。
Yang らは、既存の拡散事前分布を徹底的に調査し、ノイズ除去スコアを最適化することでこれらの事前分布を改善するための統一フレームワークを提案しました。このアプローチの多用途性はさまざまなユースケースに拡張され、大幅なパフォーマンス向上を一貫して実現します。実験評価において、私たちのアプローチは現代の手法を超え、前例のないパフォーマンスを達成します。 3D 生成テクスチャの改良には成功しましたが、生成された 3D モデルのジオメトリを強化するにはまだ改善の余地があります。
最適化と速度
このサブセクションでは、トレーニングや推論の速度を高速化するために研究者によって開発された手法について説明します。 Chung らの研究では、オーバーフィッティングの問題を軽減しながら、限られた数の画像を使用して 3D シーン表現のガウス散乱を最適化する方法が導入されています。ガウス散乱点を使用して 3D シーンを表現する従来の方法では、特に利用可能な画像が限られている場合、過剰適合が発生する可能性があります。この手法では、事前トレーニングされた単眼深度推定モデルからの深度マップを幾何学的ガイドとして使用し、それらを SFM パイプラインからのまばらな特徴点と位置合わせします。これらは、3D ガウス散乱を最適化し、浮遊アーティファクトを軽減し、幾何学的一貫性を確保するのに役立ちます。提案された深度ガイドに基づく最適化戦略は LLFF データセットでテストされ、画像のみを使用した場合と比較してジオメトリが改善されていることがわかります。この研究には、早期停止戦略と深度マップの平滑化用語の導入が含まれており、どちらもパフォーマンスの向上に役立ちます。ただし、単眼奥行き推定モデルの精度への依存や COLMAP のパフォーマンスへの依存など、制限もあることも認識されています。将来の研究では、推定深度の相互依存性を調査し、テクスチャのない平原や空などの困難な領域での深度推定の課題に対処することが推奨されます。
Fu らは、シーケンス画像からのカメラ姿勢推定と NVS を同時に行うための新しいエンドツーエンド フレームワークである COLMAP Free 3D Gaussian Splatting (CF-3DGS) を導入しました。これにより、以前の方法でのカメラの動きの問題が解決されました。長期間にわたるヤマトの訓練により、 NeRF の暗黙的表現とは異なり、CF-3DGS は明示的な点群を利用してシーンを表現します。この方法では、入力フレームを順次処理し、3D ガウスを段階的に拡張してシーン全体を再構築し、360° ビデオなどの難しいシーンでのパフォーマンスと堅牢性の向上を実証します。この方法は、カメラのポーズと 3D-GS を連続的に最適化するため、ビデオ ストリーミングや順序付けされた画像取得に特に適しています。ガウス スプラッシュを使用すると、トレーニングと推論の速度が速くなり、以前の方法と比較したこのアプローチの利点が実証されています。有効性は実証されていますが、逐次最適化は主に順序付けされた画像コレクションにアプリケーションを制限し、将来の研究で順序付けされていない画像コレクションへの拡張を検討する余地を残していることが認められています。
レンダリングとシェーディングの方法
Yu らは、特にサンプリング レートを変更したときに NVS にアーティファクトが現れることを 3D-GS で観察しました。導入されたソリューションは、3D スムージング フィルターを組み込んで 3D ガウス プリミティブの最大周波数を調整することで構成され、配布範囲外のレンダリングにおけるアーティファクトに対処します。さらに、エイリアシングと拡張の問題に対処するために、2D 拡張フィルターが 2D ミップ フィルターに置き換えられました。ベンチマーク データセットの評価では、特にサンプリング レートを変更する場合のミップ スプラッティングの有効性が実証されています。提案された変更は原理的かつ簡単で、元の 3D-GS コードへの変更は最小限で済みます。ただし、ガウス フィルター近似によって生じる誤差やトレーニング オーバーヘッドのわずかな増加など、認識されている制限があります。この研究では、Mip Splatting を競争力のあるソリューションとして紹介し、最先端の手法と同等のパフォーマンスと、配布外のシナリオにおける優れた汎用性を実証し、あらゆる規模でエイリアスフリーのレンダリングを実現できる能力を実証しました。
Gao らは、多視点画像からマテリアルと照明を分解できる新しい 3D 点群レンダリング手法を提案しました。このフレームワークにより、シーンの編集、レイ トレーシング、リアルタイムの再ライティングが区別できる方法で可能になります。シーン内の各点は、法線方向、双方向反射分布関数 (BRDF) などの材料特性、さまざまな方向からの入射光に関する情報を含む「再照明可能な」 3D ガウスで表されます。正確な照度を推定するために、入射光はグローバル成分とローカル成分に分割され、視野角に基づく可視性が考慮されます。シーンの最適化では 3D ガウス スプラッシュを利用し、物理ベースの微分可能なレンダリングで BRDF と照明の分解を処理します。革新的なポイントベースのレイ トレーシング アプローチは、境界ボリューム階層を活用して、リアルタイム レンダリング中の効率的な可視性ベイクとリアルなシャドウを可能にします。実験では、BRDF 推定とビュー レンダリングが既存の方法と比較して優れていることが示されています。ただし、明確な境界がなく、最適化中にターゲット マスクが必要なシーンには依然として課題が存在します。将来の研究では、3D ガウス散乱によって生成された点群の幾何学的精度を向上させるために、マルチビュー ステレオ (MVS) キューの統合を検討する可能性があります。この「信頼性の高い 3D ガウス」パイプラインは、有望なリアルタイム レンダリング機能を実証し、再ライティング、編集、レイ トレーシングを可能にする点群ベースのアプローチを通じて、革新的なメッシュ ベースのグラフィックスへの扉を開きます。
圧縮
Fanらは、レンダリングで使用される3Dガウス表現を圧縮するための新しい技術を紹介しました。彼らの手法は、ネットワーク プルーニングと同様に、重要性に基づいて冗長なガウスを特定して削除し、視覚的な品質への影響を最小限に抑えます。 LightGaussian は、知識の抽出と擬似ビューの強化を活用して、球面調和関数が少なく、より複雑性の低い表現で情報を提供し、冗長性をさらに削減します。さらに、VecTree 量子化と呼ばれるハイブリッド方式は、属性値を量子化することで表現を最適化し、精度を大幅に損なうことなく、より小さいサイズを実現します。標準的な方法と比較して、LightGaussian は 15 倍を超える平均圧縮率を達成し、Mip NeRF 360 や Tanks&Temples などのデータセットでのレンダリング速度を 139 FPS から 215 FPS に大幅に向上させます。関係する主な手順は、グローバル顕著性の計算、ガウスの枝刈り、擬似ビューによる知識の抽出、VecTree を使用した属性の定量化です。全体として、LightGaussian は、大きなポイントベースの表現をコンパクトな形式に変換する画期的なソリューションを提供し、データの冗長性を大幅に削減し、レンダリング効率を大幅に向上させます。
アプリケーションとケーススタディ
このセクションでは、2023 年 7 月の開始以来、ガウス スプラッシュ アルゴリズムのアプリケーションにおける大きな進歩について詳しく説明します。これらの進歩は、アバター、SLAM、メッシュ抽出、物理シミュレーションなどのさまざまな分野で特定の用途に使用されます。これらの特殊なユースケースに適用すると、ガウス スプラッティングはさまざまなアプリケーション シナリオでの多用途性と有効性を実証します。
アバター
AR/VR アプリケーションの流行の高まりに伴い、Gaussian Splash の研究の多くは人間のデジタル アバターの開発に焦点を当てています。少ない視点から被写体を捉えて 3D モデルを構築するのは困難な作業ですが、Gaussian Splash は研究者と業界がこの目標を達成するのに役立ちます。
関節角度または関節運動
このガウス散乱手法は、関節角度に基づいて人体のモデリングに焦点を当てています。このタイプのモデルの一部のパラメーターは、3 次元関節の位置、角度、およびその他の同様のパラメーターを反映します。入力フレームをデコードして、現在のフレームの 3D ジョイント位置と角度を確認します。
Zielonka らは、ガウス散乱を使用した人体表現モデルを提案し、革新的な 3D-GS テクノロジーを使用してリアルタイム レンダリングを実装しました。既存の写実的な運転可能なアバターとは異なり、Drivable 3D Gaussian Splash (D3GA) は、トレーニング中の正確な 3D レジストレーションやテスト中の高密度の入力画像に依存しません。代わりに、リアルタイム レンダリングに高密度にキャリブレーションされたマルチビュー ビデオを利用し、関節のキーポイントと角度によって駆動される四面体ケージベースの変形を導入するため、図 9 に示すように、通信を伴うアプリケーションに効果的になります。

アニメーション可能
これらのメソッドは通常、ポーズ依存のガウスをトレーニングして、衣服の細部を含む複雑な動的外観をキャプチャし、高品質のアバターを生成します。これらのメソッドの中には、リアルタイム レンダリング機能もサポートしているものもあります。

Jiang らは、実際の人間を効果的にレンダリングできる方法である HiFi4G を提案しました。 HiFi4G は、モーション プリアを備えたデュアル グラフ メカニズムと適応時空間正則化機能を備えた 4D ガウス最適化を採用し、3D ガウス表現と非剛体トラッキングを組み合わせています。図 10 に示すように、HiFi4G は約 25 倍の圧縮率を実現し、フレームごとに必要なストレージ容量は 2MB 未満であり、最適化速度、レンダリング品質、ストレージ オーバーヘッドの点で優れたパフォーマンスを発揮します。これは、ガウスのスプラッシュと非剛体トラッキングを橋渡しするコンパクトな 4D ガウス表現を提案します。ただし、セグメンテーションへの依存、アーティファクトを引き起こす不適切なセグメンテーションの影響を受けやすく、フレームごとの再構成とグリッド追跡の必要性により、すべてのポーズに制限が生じます。今後の研究では、最適化プロセスを加速し、Web ビューアやモバイル デバイスでの広範な展開に向けた GPU 順序依存性の低減に焦点を当てる可能性があります。
頭部ベース
以前の頭部アバター メソッドは、主に固定された明示的なプリミティブ (グリッド、ポイント) または暗黙的なサーフェス (SDF) に依存していました。ガウス散乱ベースのモデルは、AR/VR およびフィルターベースのアプリケーションの台頭への道を開き、ユーザーがさまざまなメイクアップの外観、トーン、ヘアスタイルなどを試すことができるようになります。
Wang らは、動的なシーンを表現するために標準ガウス変換を利用しました。著者らは、パラメータ化されたヘッド ジオメトリの効率的なコンテナとして明示的な「動的」トリプレーンを使用し、トリプレーン内の基礎となるジオメトリおよび因子とよく調整して、正規ガウスの調整された正則化係数を取得しました。小さな MLP を使用して、係数は 3D ガウス プリミティブの不透明度と球面調和係数にデコードされます。 Quin らは、視点、ポーズ、表情を制御できる超現実的な頭部アバターを作成しました。アバターの再構築プロセス中に、著者は変形モデル パラメータとガウス スプラット パラメータを同時に最適化しました。この作品は、さまざまな困難なシナリオでアニメーション化するアバターの能力を示しています。 Dhamo らは、学習可能な潜在特徴に基づいて 3D-GS の明示的表現を拡張するハイブリッド モデルである HeadGaS を提案しました。これらの特徴は、パラメトリック頭部モデルの低次元パラメータと線形にブレンドされ、最終的な表情依存の色と不透明度の値を導き出すことができます。図 11 にいくつかの画像の例を示します。
SLAM
SLAM は、自動運転車で地図の構築とその地図内での車両の位置を同時に決定するために使用されるテクノロジーです。これにより、車両は未知の環境をナビゲートし、マッピングできるようになります。名前が示すように、ビジュアル SLAM (vSLAM) はカメラやさまざまなイメージ センサーからの画像に依存します。この方法は、単純なカメラ、複眼カメラ、RGB-D カメラなど、さまざまなタイプのカメラで機能するため、コスト効率の高いソリューションになります。カメラを通じて、ランドマーク検出をグラフベースの最適化と組み合わせることで、SLAM 実装の柔軟性を高めることができます。単眼 SLAM は、単一のカメラを使用する vSLAM のサブセットであり、奥行き知覚の課題に直面していますが、この問題は、オドメトリや慣性計測ユニット (IMU) のエンコーダなどの追加センサーを組み込むことで解決できます。 vSLAM に関連する主要なテクノロジーには、SFM、ビジュアル オドメトリ、ビーム調整などがあります。ビジュアル SLAM アルゴリズムは、2 つの主要なカテゴリに分類されます。1 つは特徴点マッチングを使用するスパース手法 (例: 並列追跡およびマッピング、ORB-SLAM)、もう 1 つは画像全体の明るさを利用するデンス手法 (例: DTAM、LSD-SLAM、DSO) です。 、SVO)。
物理学によるメッシュ抽出
ガウス散乱は、物理ベースのシミュレーションとレンダリングに使用できます。 3D ガウス カーネルにパラメータを追加することで、速度、ひずみ、その他の機械的特性をモデル化できます。そのため、ガウス散乱を使用した物理シミュレーションを含むさまざまな手法が数か月以内に開発されました。

Xie らは、偏微分方程式 (PDE) を使用してガウス カーネルとそれに関連する球面調和関数の進化を促進する、連続体力学に基づく 3 次元ガウス運動学手法を導入しました。この革新により、統合されたシミュレーション レンダリング パイプラインの使用が可能になり、明示的なターゲット メッシュの必要性がなくなることでモーション生成が簡素化されます。彼らのアプローチは、さまざまな材料での包括的なベンチマークと実験を通じて多用途性を実証し、単純なダイナミクスのシナリオでリアルタイムのパフォーマンスを実証します。著者らは、物理ベースのダイナミクスとフォトリアリスティックなレンダリングを同時にシームレスに生成するフレームワークである PhysGaussian を紹介します。著者らは、影の進化の欠如や体積積分の単一点求積法の使用などのフレームワークの限界を認識しながら、物質点法 (MPM) での高次求積法の採用や、より現実的なモデリングのために統合されたニューラル ネットワークの使用。このフレームワークは、液体などのさまざまなマテリアルを処理できるように拡張でき、ラージ言語モデル (LLM) を利用した高度なユーザー コントロールを組み込むことができます。図 13 は、PhysGaussian フレームワークのトレーニング プロセスを示しています。
編集
Gaussian Splash は、3D 編集やシーンのポイント操作にも翼を広げます。これから説明する最新の進歩を使用すると、チップベースのシーンの 3D 編集も可能になります。これらの方法は、シーンを 3D ガウス マップとして表現するだけでなく、シーンの意味論的かつ議論の余地のある理解も行います。
Chen らは、従来の 3D 編集方法の限界を克服することを目的とした、ガウス スプラッティングに基づく新しい 3D 編集アルゴリズムである GaussianEditor を紹介しました。メッシュや点群に依存する従来の方法ではリアルな描写を実現するのが困難ですが、NeRF のような暗黙的な 3D 表現は処理の遅さや制御の制限という課題に直面しています。 GaussianEditor は、3D-GS を活用し、ガウス セマンティック トラッキングで精度と制御を強化し、生成ガイダンスの下で安定した洗練された結果を得るために階層ガウス スプラッシュ (HGS) を導入することで、これらの問題を解決します。このアルゴリズムには、効率的なオブジェクトの削除と統合のための特殊な 3D 修復手法が含まれており、広範な実験で優れた制御、有効性、および高速パフォーマンスを実証します。図 14 は、Chen らがテストしたさまざまなテキスト プロンプトを示しています。 GaussianEditor は 3D 編集に大きな進歩をもたらし、効率性、速度、制御性が強化されています。この研究の貢献には、詳細な編集制御のためのガウス セマンティック トラッキングの導入、生成ガイダンスの下で安定した収束を達成するための HGS の提案、ターゲットの迅速な削除と追加のための 3D 修復アルゴリズムの開発、およびこれを実証する広範な実験が含まれます。この方法は、以前の 3D 編集方法よりも優れています。 GaussianEditor は進歩しているにもかかわらず、効果的な監視のために 2D 拡散モデルに依存しており、複雑なキューの処理に制限があります。これは、同様のモデルに基づく他の 3D 編集方法が直面する共通の課題です。

ディスカッション
従来、3D シーンは、明示的な性質と GPU/CUDA ベースの高速ラスタライゼーションとの互換性により、メッシュとポイントを使用して表現されてきました。ただし、NeRF 手法などの最近の進歩は、多層パーセプトロン最適化やボリュメトリック レイ マーチングによる新しいビュー合成などの手法を採用し、連続シーン表現に焦点を当てています。連続表現は最適化に役立ちますが、レンダリングに必要なランダム サンプリングにより高価なノイズが発生します。 Gaussian Splash は、最先端のビジュアル品質と競争力のあるトレーニング時間を達成するために最適化された 3D ガウス表現を活用することで、このギャップを埋めます。さらに、タイルベースのスプラッシュ ソリューションにより、最高品質のリアルタイム レンダリングが保証されます。ガウス スプラッシュは、3D シーンをレンダリングする際の品質と効率の点で最高の結果を提供します。
ガウス スプラッシュは、元の表現を変更することで動的で変形可能なターゲットを処理するために開発されました。これには、3D 位置、回転、スケーリング係数、色と不透明度の球面調和係数などのパラメーターを組み込むことが含まれます。この分野における最近の進歩には、基礎軌道の共有を促進するためのスパース性損失の導入、時間依存の残差を捕捉するためのデュアルドメイン変形モデルの導入、生成ネットワークと 3D ガウス レンダリングを接続するガウス シェル マッピングなどがあります。非剛体トラッキング、アバター表現の変更、現実的な人間のパフォーマンスの効率的なレンダリングなどの課題に対処するための取り組みも行われています。これらの進歩により、動的で変形可能なターゲットを扱う際のリアルタイム レンダリング、効率の最適化、高品質の結果が実現します。
一方、拡散とガウス スプラッシュは連携して、テキスト プロンプトから 3D ターゲットを作成します。拡散モデルは、一連のよりクリーンな画像を通じて画像破損のプロセスを逆転させることによって、ノイズの多い入力から画像を生成する方法を学習するニューラル ネットワークです。テキストから 3D へのパイプラインでは、拡散モデルがテキストの説明に基づいて初期 3D 点群を生成し、その後、ガウス散乱を使用してガウス球に変換されます。レンダリングされたガウス球により、最終的な 3D ターゲット イメージが生成されます。この分野の進歩には、構造化ノイズを使用してマルチビュー ジオメトリの課題に対処すること、変分ガウス散乱モデルを導入して収束の問題に対処すること、拡散事前分布を強化するためにノイズ除去スコアを最適化することが含まれ、テキストベースの 3D 生成で比類のないリアリズムを実現することを目指しています。 。
ガウス スプラッシュは、AR/VR アプリケーションのデジタル アバターの作成に広く使用されています。これには、最小限の視点からオブジェクトをキャプチャし、3D モデルを構築することが含まれます。この技術は人間の関節、関節角度、その他のパラメータのモデル化に使用され、表現力豊かで制御可能なアバターの生成を可能にします。この分野の進歩には、高周波の顔の詳細をキャプチャし、誇張した表情を保存し、アバターを効果的にモーフィングする方法の開発が含まれます。さらに、明示的な表現と学習可能な潜在的な特徴を組み合わせて、表現に依存する最終的な色と不透明度の値を実現するハイブリッド モデルが提案されています。これらの進歩は、生成された 3D モデルのジオメトリとテクスチャを強化して、AR/VR アプリケーションにおけるリアルで制御可能なアバターに対する需要の高まりに応えることを目的としています。
ガウス スプラッティングは、SLAM での多用途なアプリケーションも見つけ、GPU 上でリアルタイムの追跡およびマッピング機能を提供します。 3D ガウス表現と微分可能なスプラッシュ ラスタライゼーション パイプラインを使用することで、現実世界および合成シーンの高速かつフォトリアリスティックなレンダリングが可能になります。この技術はメッシュ抽出と物理ベースのシミュレーションに拡張され、明示的なターゲット メッシュなしで機械的特性をモデル化できるようになります。連続力学と偏微分方程式の進歩により、ガウス カーネルの進化が可能になり、運動の生成が簡素化されました。特に、最適化には OpenVDB などの効率的なデータ構造、位置合わせのための正則化項、エラー削減のための物理学にヒントを得た項が含まれており、それによって全体的な効率と精度が向上します。圧縮とガウス散乱レンダリング効率の向上に関する他の作業も行われています。
比較
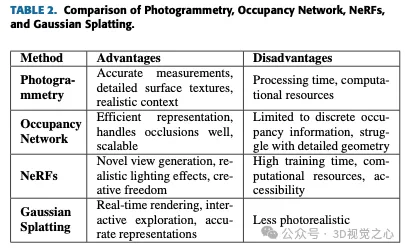
表 2 から、この記事の執筆時点では、ガウス スプラッシュがリアルタイム レンダリングとダイナミック シーン表現に最も近いオプションであることが明らかです。ネットワークの占有は、NVS のユースケースに合わせてカスタマイズされたものではありません。写真測量は、コンテキストを強く意識した高精度でリアルなモデルを作成するのに最適です。 NeRF は、斬新なビューとリアルな照明効果の生成に優れ、創造的な自由を提供し、複雑なシーンを処理します。 Gaussian Splash は、リアルタイム レンダリング機能とインタラクティブな探索に優れており、動的なアプリケーションに適しています。各手法にはそれぞれ独自の分野があり、相互に補完し合うことで、3D 再構成および視覚化のためのさまざまなツールが提供されます。
課題と制限
ガウス スプラッシュは非常に堅牢な手法ですが、いくつかの注意点があります。それらの一部を以下にリストします:
- 1) 計算の複雑さ: ガウス散乱ではピクセルごとにガウス関数の評価が必要ですが、特に多数の点や粒子を扱う場合、計算量が多くなる可能性があります。
- 2) メモリ使用量: 隣接するピクセルに対する各ポイントの重み付けされた寄与など、ガウス スプラッシュの中間結果を保存すると、大量のメモリが消費される可能性があります。
- 3) エッジ アーティファクト: ガウス散乱は、画像のエッジまたは高コントラスト領域付近にリンギングやブラーなどの望ましくないアーティファクトを生成する可能性があります。
- 4) パフォーマンスと精度のトレードオフ: 高品質の結果を達成するには、大きなカーネル サイズを使用するか、ピクセルごとに複数のガウス関数を評価する必要があり、これがパフォーマンスに影響します。
- 5) 他のレンダリング技術との統合: パフォーマンスと視覚的な一貫性を維持しながら、ガウス散乱をシャドウ マッピングやアンビエント オクルージョンなどの他の技術と統合することは複雑になる場合があります。
今後の方向性
リアルタイム 3D 再構築技術は、3D シーンやモデルのリアルタイムでのインタラクティブな探索、瞬時のフィードバックによる視点やターゲットの操作など、コンピュータ グラフィックスおよび関連分野のさまざまな機能を実現します。 。また、移動するターゲットや変化する環境を伴うダイナミックなシーンをリアルタイムでレンダリングし、リアリズムと没入感を高めることができます。リアルタイム 3D 再構成をシミュレーションおよびトレーニング環境で使用すると、自動車、航空宇宙、医療などの分野の仮想シーンに現実的な視覚フィードバックを提供できます。また、没入型 AR および VR エクスペリエンスのリアルタイム レンダリングもサポートされ、ユーザーは仮想ターゲットや環境とリアルタイムで対話できます。全体として、リアルタイム ガウス スプラッシュは、コンピューター グラフィックス、ビジュアライゼーション、シミュレーション、イマーシブ テクノロジのさまざまなアプリケーションの効率、対話性、リアリズムを強化します。
結論
この記事では、3D 再構成と新しいビュー合成のためのガウス散乱に関連するさまざまな機能面と応用面について説明しました。動的で変形可能なモデリング、モーション トラッキング、非剛体/変形可能なターゲット、表情/感情の変化、テキスト ベースの生成拡散、ノイズ除去、最適化、アバター、アニメーション化可能なターゲット、頭部ベースのモデリング、同時ローカリゼーション、計画などのトピックをカバーします。メッシュ抽出と物理学、最適化テクニック、編集機能、レンダリング方法、圧縮など。
具体的には、この記事では、画像ベースの 3D 再構成の課題と進歩、3D 形状推定の向上における学習ベースの手法の役割、動的シーンの処理、インタラクティブなターゲット操作、3D セグメンテーションにおけるガウス スプラッシュ テクノロジの応用について詳しく掘り下げています。シーン編集における潜在的なアプリケーションと将来の方向性。
ガウス スプラッシュは、コンピューター生成画像、VR/AR、ロボット工学、映画とアニメーション、自動車デザイン、小売、環境研究、航空宇宙アプリケーションなど、さまざまな分野で変革をもたらします。ただし、ガウス散乱には NeRF などの他の方法と比較してリアリズムを実現する上で制限がある可能性があることに注意してください。さらに、オーバーフィッティング、計算リソース、レンダリング品質の制限に関連する課題も考慮する必要があります。これらの制限にもかかわらず、継続的な研究とガウス散乱の進歩により、これらの課題に対処し続け、手法の有効性と適用性がさらに向上しています。
以上が単なる 3D ガウス以上のもの!最先端の 3D 再構成技術の最新概要の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1672
1672
 14
1428
52
1332
25
1276
29
1256
24
14
1428
52
1332
25
1276
29
1256
24

 なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
上記と著者の個人的な理解 3 次元ガウシアンプラッティング (3DGS) は、近年、明示的な放射線フィールドとコンピューター グラフィックスの分野で出現した革新的なテクノロジーです。この革新的な方法は、数百万の 3D ガウスを使用することを特徴とし、主に暗黙的な座標ベースのモデルを使用して空間座標をピクセル値にマッピングする神経放射線場 (NeRF) 方法とは大きく異なります。明示的なシーン表現と微分可能なレンダリング アルゴリズムにより、3DGS はリアルタイム レンダリング機能を保証するだけでなく、前例のないレベルの制御とシーン編集も導入します。これにより、3DGS は、次世代の 3D 再構築と表現にとって大きな変革をもたらす可能性のあるものとして位置付けられます。この目的を達成するために、私たちは 3DGS 分野における最新の開発と懸念について初めて体系的な概要を提供します。
 カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
0.前面に書かれています&& 自動運転システムは、さまざまなセンサー (カメラ、ライダー、レーダーなど) を使用して周囲の環境を認識し、アルゴリズムとモデルを使用することにより、高度な知覚、意思決定、および制御テクノロジーに依存しているという個人的な理解リアルタイムの分析と意思決定に。これにより、車両は道路標識の認識、他の車両の検出と追跡、歩行者の行動の予測などを行うことで、安全な運行と複雑な交通環境への適応が可能となり、現在広く注目を集めており、将来の交通分野における重要な開発分野と考えられています。 。 1つ。しかし、自動運転を難しくしているのは、周囲で何が起こっているかを車に理解させる方法を見つけることです。これには、自動運転システムの 3 次元物体検出アルゴリズムが、周囲環境にある物体 (位置を含む) を正確に認識し、記述することができる必要があります。
 Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3 の論文がついに登場しました!このモデルは2週間前にリリースされ、Soraと同じDiT(DiffusionTransformer)アーキテクチャを採用しており、リリースされると大きな話題を呼びました。前バージョンと比較して、StableDiffusion3で生成される画像の品質が大幅に向上し、マルチテーマプロンプトに対応したほか、テキスト書き込み効果も向上し、文字化けが発生しなくなりました。 StabilityAI は、StableDiffusion3 はパラメータ サイズが 800M から 8B までの一連のモデルであると指摘しました。このパラメーター範囲は、モデルを多くのポータブル デバイス上で直接実行できることを意味し、AI の使用を大幅に削減します。
 DualBEV: BEVFormer および BEVDet4D を大幅に上回る、本を開いてください!
Mar 21, 2024 pm 05:21 PM
DualBEV: BEVFormer および BEVDet4D を大幅に上回る、本を開いてください!
Mar 21, 2024 pm 05:21 PM
この論文では、自動運転においてさまざまな視野角 (遠近法や鳥瞰図など) から物体を正確に検出するという問題、特に、特徴を遠近法 (PV) 空間から鳥瞰図 (BEV) 空間に効果的に変換する方法について検討します。 Visual Transformation (VT) モジュールを介して実装されます。既存の手法は、2D から 3D への変換と 3D から 2D への変換という 2 つの戦略に大別されます。 2D から 3D への手法は、深さの確率を予測することで高密度の 2D フィーチャを改善しますが、特に遠方の領域では、深さ予測に固有の不確実性により不正確さが生じる可能性があります。 3D から 2D への方法では通常、3D クエリを使用して 2D フィーチャをサンプリングし、Transformer を通じて 3D と 2D フィーチャ間の対応のアテンション ウェイトを学習します。これにより、計算時間と展開時間が増加します。
 CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
上記および筆者の個人的な理解: 現在、自動運転システム全体において、認識モジュールが重要な役割を果たしている。道路を走行する自動運転車は、認識モジュールを通じてのみ正確な認識結果を得ることができる。下流の規制および制御モジュール自動運転システムでは、タイムリーかつ正確な判断と行動決定が行われます。現在、自動運転機能を備えた自動車には通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなどのさまざまなデータ情報センサーが搭載されており、さまざまなモダリティで情報を収集して正確な認識タスクを実現しています。純粋な視覚に基づく BEV 認識アルゴリズムは、ハードウェア コストが低く導入が容易であるため、業界で好まれており、その出力結果はさまざまな下流タスクに簡単に適用できます。
 オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
前に書かれたプロジェクトのリンク: https://nianticlabs.github.io/mickey/ 2 枚の写真が与えられた場合、それらの写真間の対応関係を確立することで、それらの間のカメラのポーズを推定できます。通常、これらの対応は 2D 対 2D であり、推定されたポーズはスケール不定です。いつでもどこでもインスタント拡張現実などの一部のアプリケーションでは、スケール メトリクスの姿勢推定が必要なため、スケールを回復するために外部深度推定器に依存します。この論文では、3D カメラ空間でのメトリックの対応を予測できるキーポイント マッチング プロセスである MicKey を提案します。画像全体の 3D 座標マッチングを学習することで、相対的なメトリックを推測できるようになります。
 自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転では軌道予測が重要な役割を果たしており、自動運転軌道予測とは、車両の走行過程におけるさまざまなデータを分析し、将来の車両の走行軌跡を予測することを指します。自動運転のコアモジュールとして、軌道予測の品質は下流の計画制御にとって非常に重要です。軌道予測タスクには豊富な技術スタックがあり、自動運転の動的/静的知覚、高精度地図、車線境界線、ニューラル ネットワーク アーキテクチャ (CNN&GNN&Transformer) スキルなどに精通している必要があります。始めるのは非常に困難です。多くのファンは、できるだけ早く軌道予測を始めて、落とし穴を避けたいと考えています。今日は、軌道予測に関するよくある問題と入門的な学習方法を取り上げます。関連知識の紹介 1. プレビュー用紙は整っていますか? A: まずアンケートを見てください。
 LLMはすべて完了しました! OmniDrive: 3D 認識と推論プランニングの統合 (NVIDIA の最新)
May 09, 2024 pm 04:55 PM
LLMはすべて完了しました! OmniDrive: 3D 認識と推論プランニングの統合 (NVIDIA の最新)
May 09, 2024 pm 04:55 PM
上記と著者の個人的な理解: この論文は、自動運転アプリケーションにおける現在のマルチモーダル大規模言語モデル (MLLM) の主要な課題、つまり MLLM を 2D 理解から 3D 空間に拡張する問題の解決に特化しています。自動運転車 (AV) は 3D 環境について正確な決定を下す必要があるため、この拡張は特に重要です。 3D 空間の理解は、情報に基づいて意思決定を行い、将来の状態を予測し、環境と安全に対話する車両の能力に直接影響を与えるため、AV にとって重要です。現在のマルチモーダル大規模言語モデル (LLaVA-1.5 など) は、ビジュアル エンコーダーの解像度制限や LLM シーケンス長の制限により、低解像度の画像入力しか処理できないことがよくあります。ただし、自動運転アプリケーションには次の要件が必要です。
