

この記事を読んで、いくつかの一般的な LangChain の代替手段を理解してください

皆さんこんにちは、私は Luga です。今日は人工知能 (AI) の生態分野に関連するテクノロジー、つまり LLM 開発フレームワークについて話します。
LLM (大規模言語モデル) アプリケーション開発の分野では、オープンソース フレームワークが重要な役割を果たし、開発者に強力なツール サポートを提供します。この分野のリーダーとして、LangChain はその革新的なデザインと包括的な機能で幅広い評価を獲得しています。しかし同時に、さまざまなシナリオのニーズに適したより良い選択肢を提供する代替フレームワークもいくつか登場しています。
結局のところ、どのフレームワークにも必然的に一定の制限があります。たとえば、LangChain の速度抽象化により、場合によっては開始がより困難になる可能性があり、デバッグ エクスペリエンスを強化する必要があり、一部のコードの品質も改善に値します。これはまさに代替製品が目指している方向であり、アーキテクチャ設計の最適化、エンジニアリング手法の改善、コミュニティ サポートの強化などにより、開発者にとってより便利で効率的なアプリケーション構築エクスペリエンスを生み出すことに努めています。

1. LangChain 開発背景の分析
これは人気のあるオープンソース フレームワークであり、LangChain は開発者が人工知能アプリケーションを構築するのを支援するように設計されています。 LangChain は、チェーン、プロキシ、メモリ モジュール用の標準インターフェイスを提供することで、LLM (LangLink Model) ベースのアプリケーションの開発プロセスを簡素化します。
実際のアプリケーション シナリオでは、概念実証 (POC) を迅速に作成するときに LangChain+ フレームワークが特に役立ちます。ただし、どのフレームワークを使用しても、いくつかの課題が伴います。具体的には:
- 過度の抽象化により、特定の状況では LangChain の使用が非常に便利になりますが、フレームワークでサポートされていないユースケースを構築する場合は困難になります。フレームワークの高度な抽象化により、開発者の柔軟性が制限される可能性があり、その結果、一部の特定のニーズを満たすことができなくなる可能性があります。
- フレームワークの抽象化レベルが高いため、パフォーマンスの問題やバグのデバッグがより困難になります。アプリケーションで問題が発生した場合、根本的な詳細がフレームワーク内に隠されており、デバッグが複雑になるため、開発者が問題の具体的な原因を特定することが困難になることがあります。
- コードの品質は低く、コンポーネントの複雑さはより高い可能性があるため、開発者は本番環境での実際のデプロイメントではなく、AI 開発の学習やプロトタイピングに LangChain を使用する可能性が高くなります。これは、フレームワークのメンテナンスとパフォーマンスの最適化に課題があり、実稼働グレードのアプリケーションに必要な安定性と信頼性が保証されていないことが原因である可能性があります。
2. 7 つの次元の包括的な分析に基づく LangChain の代替の実現可能性分析
LLM (大規模言語モデル) の開発と適用の急増において、さまざまなツール プラットフォームの利点を評価し承認することが重要なリンクとなります。プロンプトエンジニアリング、データ統合、ワークフローオーケストレーション、テストの視覚化、評価指標、生産準備状況、ライフサイクル管理を含む 7 つの主要な側面に基づく包括的な分析は、間違いなく非常に前向きで体系的なアイデアと方向性です。
次に、詳細な分析を 1 つずつ実行します。
1. プロンプト エンジニアリング - プロンプト エンジニアリング
LLM の可能性を最大限に引き出すには、高品質なプロンプト エンジニアリングが前提条件であり、基礎であることに疑いの余地はありません。理想的なツール プラットフォームは、簡潔で柔軟なプロンプト作成インターフェイスを提供するだけでなく、プロンプトの自動生成と最適化を実現し、特定のタスクのコンテキストに最大限適合し、プロンプトのコストを削減するために、自然言語理解やセマンティック解析などの高度なテクノロジーを統合する必要があります。手動介入のコスト。
さらに、複雑な複数ステップのタスクの場合、プロンプトのパラメータ化された管理とバージョン管理をサポートできるかどうかも重要な考慮事項になります。
2. データの取得と統合 - データの取得と統合
RAG パラダイムの台頭により、効率的な外部ナレッジ ベース統合機能がツール プラットフォームに必要な機能になりました。優れたプラットフォームは、さまざまな異種データ ソースに簡単に接続してインポートできるだけでなく、ナレッジ インジェクションの精度と一貫性を確保するための強力なデータ前処理機能と品質管理機能も備えている必要があります。さらに、大量の検索結果を視覚的に分析して最適化することで、開発者の作業効率も大幅に向上します。
3. モデルのオーケストレーションとチェーン - モデルのオーケストレーションとチェーン
現実の世界で複雑なタスク要件に直面すると、通常、単一の LLM が単独でそれを完了することは困難です。したがって、複数のモデル モジュールのワークフローを柔軟に調整し、パラメーター制御を通じて差別化された組み合わせを実現する機能が、ツール プラットフォームの中核的な競争力になります。
同時に、ワークフローのバージョン管理、パラメータ調整、再現性、その他の機能の優れたサポートにより、開発効率も大幅に向上します。
4. デバッグと可観測性 - デバッグと可観測性
典型的な「ブラック ボックス」AI として、LLM システムの内部メカニズムは常に混乱を招いています。優れたツール プラットフォームは、この制限を打ち破り、注意分布の視覚化や推論パスの追跡などの手段を通じてモデルの内部状態に関する洞察を提供するよう努める必要があり、同時に、より正確なエラーのトラブルシューティング、逸脱の修正、パフォーマンスの最適化をサポートする必要があります。これにより、システムの解釈可能性と信頼性が真に向上します。
5. 評価 - 評価
厳格な評価プロセスは、LLM アプリケーションの品質を確保するための重要な部分です。この時点で、さまざまなプラットフォームによって提供される評価インフラストラクチャ、対象となる指標の次元、自動化のレベル、および手動評価との統合の程度が、評価結果の客観性と信頼性を直接決定します。
一般的に言えば、成熟した評価システムは、最終製品の実際の実装に対して確かな品質保証を確実に提供します。
6. 導入と実稼働への対応 - 導入と実稼働への対応
実稼働環境向けの産業グレードのアプリケーションの場合、ツール プラットフォームの導入と運用および保守の機能が中心的な考慮事項となります。完全なオンライン メカニズム、サポートされている導入オプション (クラウド、エッジ デバイスなど)、セキュリティ コンプライアンス、パフォーマンスの最適化、監視と警報、その他の製品保証は、LLM システムの最終的な可用性と信頼性に直接影響します。
7. エコシステムと統合 - エコシステムと統合
最先端の革新的なテクノロジーとして、LLM プラットフォームと既存のエンタープライズ テクノロジー スタックのシームレスな統合は、その広範なアプリケーションを確保するための前提条件です。巨大なサードパーティ アプリケーション ストアとパートナー リソース ライブラリは、幅広い業界シナリオと差別化されたニーズをカバーする豊富なエコシステムの構築に役立ち、それによって LLM テクノロジーの大規模な普及と革新的なアプリケーションを促進します。
上記の 7 つの側面の包括的な分析とトレードオフの比較を通じて、さまざまな LLM 開発ツール プラットフォームの長所と短所を比較的客観的に評価できます。たとえば、迅速なエンジニアリング機能に重点を置くシナリオでは、この分野で優れたパフォーマンスを発揮するプラットフォームを選択する傾向が強いかもしれませんが、強力な運用とメンテナンスの保証を必要とする産業レベルのアプリケーションでは、展開や信頼性などの要素が重要になります。さらに重要な検討事項。
もちろん、上記の 7 つの機能的特徴に加えて、特定のシーンの要件に基づいて、使いやすさ、学習曲線、ドキュメントの品質、コミュニティ活動、開発ルートなどの他の非機能的要素も考慮する必要があります。そして仕事の習慣について、本当に高度なツール選択の決定を下すことができるでしょうか。
同時に、ツールプラットフォームの活力と持続可能な開発能力も不可欠な視点です。活発な開発コミュニティ、充実したビジネスサポートプラン、継続的な技術革新ルートにより、長期にわたる信頼できるサポートを提供します。結局のところ、LLM テクノロジーの開発は初期段階にあり、ツール プラットフォームは時代に追いつき、常に新しい変化の傾向に適応して受け入れる必要があります。
3. 一般的なオープンソースの LangChain 代替手段の分析
1.LlamaIndex
LLM (大規模言語モデル) の波の中で、RAG (検索拡張生成) アーキテクチャがますます主流のパラダイムになりつつあります。 RAG アプリケーションの構築に重点を置いたオープンソース データ フレームワークとして、LlamaIndex は間違いなく有望な開発の可能性を示しています。
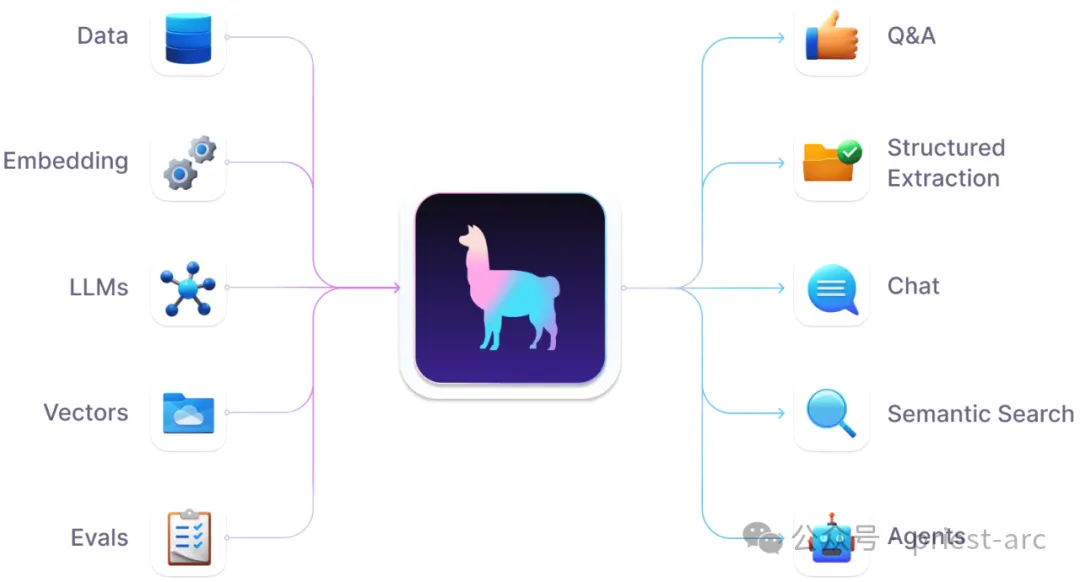
LLM アプリケーション用の LlamaIndex データ フレーム (出典: LlamaIndex)
Langchain などの有名なプロジェクトと比較して、LlamaIndex は、焦点を絞ったフィールドの最適化と革新的な設計コンセプトにより、ユーザーにさらなる効率と専門性を提供します RAG アプリケーション開発経験。その主な機能と利点についてさらに詳しく分析したほうがよいでしょう:
まず第一に、LlamaIndex はデータの取り込みと前処理で優れたパフォーマンスを発揮します。さまざまな構造化および非構造化データ形式と互換性があるだけでなく、さらに重要なことに、柔軟なテキスト セグメンテーション、ベクトル化、その他のメカニズムを通じて、データが高品質で LLM メモリにエンコードされることが保証されます。これにより、生成段階でのコンテキストを理解するための強固な基盤が築かれます。
同時に、LlamaIndex はインデックス データ構造とクエリ戦略の豊富な選択肢を提供し、開発者がさまざまなシナリオでクエリ効率の利点を最大限に活用し、高パフォーマンスのセマンティック検索を実現できるようにします。この的を絞った最適化は、RAG アプリケーションの重要な要件の 1 つです。
注目に値するもう 1 つのハイライトは、LlamaIndex のマルチモーダル データ (画像、ビデオなど) の自然なサポートです。主要なビジュアル セマンティック モデルと統合することで、豊富なクロスモーダル コンテキストを RAG 生成プロセスに導入でき、出力に新しい次元を追加できます。これにより、数多くの革新的なアプリケーションへの道が開かれることは間違いありません。
コアのデータ管理機能に加えて、LlamaIndex は RAG アプリケーション開発のエンジニアリング実践にも焦点を当てています。並列クエリや Dask ベースの分散コンピューティングのサポートなどの高度な機能を提供し、データ処理効率を大幅に向上させ、大規模な生産の基盤を築きます。
アーキテクチャの観点から見ると、LlamaIndex はモジュール式でスケーラブルな設計コンセプトを遵守しています。柔軟なプラグイン システムにより、開発者はカスタム データ ローダー、テキスト スプリッター、ベクトル インデックス、その他のモジュールを簡単に導入して、さまざまなシナリオでの個別のニーズに完全に対応できます。
さらに、オープンソース エコロジーの完璧な統合も、LlamaIndex 固有のユニークな利点です。 Hugging Face、FAISS などの一般的なツールやフレームワークをすぐに利用できる統合サポートがあり、ユーザーは障壁なく高度な AI/ML 機能を活用して、革新的な製品を効率的に構築できます。
RAG アプリケーションに根ざしたプロフェッショナル レベルのツールとして、LlamaIndex は、Langchain などの一般的なフレームワークを補完する優れたツールとなっています。開発者は、実際のニーズに基づいて、LlamaIndex の効率的で最適化されたパスと、Langchain の一般的で柔軟なパラダイムのどちらかを自由に選択できるため、開発効率と製品品質を最大化できます。
もちろん、LlamaIndex は結局のところ若くてダイナミックなプロジェクトであり、改善と開発の余地がまだたくさんあります。たとえば、より複雑なシナリオのモデリング機能をさらに強化し、よりインテリジェントな自動最適化提案を提供し、ベスト プラクティスと参考ユース ケースの蓄積を強化することはすべて、将来の重要な方向性となります。
同時に、LlamaIndex は LLM および RAG アーキテクチャの最新の開発を継続し、新たなモデルとパラダイムの革新をタイムリーに取り入れて、あらゆる側面で業界をリードする標準を維持します。これらはいずれも、活発な開発者コミュニティ、トップ企業パートナー、科学研究コミュニティの同僚による長期的な投資と継続的なサポートがなければ不可能です。
2.Flowise AI
LLM (大規模言語モデル) アプリケーション開発の分野では、敷居を下げて効率を向上させることが常に業界の共通の願望でした。オープンソースのノーコード LLM アプリケーション構築ツールとして、Flowise はこの追求において強力な実践者になりつつあります。
従来のコーディング開発フレームワークとは異なり、Flowise の革新的なドラッグ アンド ドロップのビジュアル インターフェイスが最大のハイライトです。開発者はプログラミング言語を深く習得する必要はなく、プリセットされたコンポーネント モジュールをインターフェイスにドラッグ アンド ドロップするだけで、簡単なパラメータ設定と配線を通じて、強力な LLM アプリケーションを簡単に構築できます。この新しい開発パラダイムにより、参入障壁が大幅に下がり、LLM アプリケーション開発はもはやプログラマーの独占的な領域ではなくなり、一般のユーザーも創造性を発揮して自動化のニーズを実現できるようになりました。

Flowise AI リファレンス フロー (出典: Flowise)
さらに言及する価値があるのは、Flowise が単純なローコード ツールではなく、業界トップのフレームワークである LangChain とカーネル レベルで深く統合されていることです。これは、Flowise が、LangChain の強力な LLM オーケストレーション、チェーンされたアプリケーション、データ拡張などのすべてのコア機能をネイティブにサポートし、ドラッグ アンド ドロップ コンポーネントを通じてコード不要のインターフェイスに完全に公開し、アプリケーション開発の柔軟性と拡張性を確保することを意味します。能力。単純な質問応答システムを構築している場合でも、複雑なマルチモーダル分析プロセスを構築している場合でも、Flowise はお客様のニーズを完全に満たすことができます。
その包括的な機能に加えて、Flowise のもう 1 つの優れた利点は、既存のエコシステムとのシームレスな統合です。真のオープンソース プロジェクトとして、Flowise は主流の LLM モデルとツール チェーンに対するすぐに使用できるサポートを提供し、開発者がこれらの技術機能を障害なく利用し、時代に合わせたユニークで革新的なアプリケーションを簡単に構築できるようにします。
たとえば、Flowise は Anthropic、OpenAI、Cohere などの主流の LLM モデルとシームレスに互換性があります。ユーザーは簡単な構成で最新かつ最も強力な言語機能を呼び出すことができ、同時にデータ統合エコロジーとも互換性があります。ネイティブ サポートにより、アプリケーションは豊富な異種データ ソースに自由にアクセスできます。
最も魅力的なのは、Flowise がクローズド システムではなく、オープン API と組み込み統合メカニズムを提供していることです。開発者は、Flowise アプリケーションを Web サイト、アプリ、デスクトップ ソフトウェアなどの製品環境に簡単に統合し、すべての関係者からのカスタム リクエストを受け入れて、エンドツーエンドの閉ループ エクスペリエンスを実現できます。
Flowise は、LangChain の強力な技術コア、独自の柔軟なビジュアル アーキテクチャ、エコシステムとのシームレスな統合の助けを借りて、LLM とエンドユーザーを結び、LLM の民主化プロセスを促進する強力なリンクになったと言えます。必要な個人や企業は、Flowis プラットフォーム上でワンクリックするだけで独自のインテリジェントなアプリケーションを構築および展開でき、AI によってもたらされる生産性の向上を享受できます。
3.AutoChain
軽量で拡張可能なフレームワークである AutoChain は、LangChain や AutoGPT などの前任者の経験を活用して、より効率的で柔軟な会話型インテリジェント エージェント構築エクスペリエンスを開発者に提供します。
AutoChain の中核となる設計哲学は、「シンプルさ、カスタマイズ、自動化」として要約できます。詳細は以下のとおりです:
(1) シンプル
LangChainなどの巨大なフレームワークと比較して、AutoChainは開発者の学習コストと使用コストを可能な限り削減するために、コンセプトとアーキテクチャの単純化を意図的に追求しています。これは、最も基本的な LLM アプリケーション開発プロセスを抽象化し、一連の理解しやすい構成要素を通じて明確な開発パスをユーザーに提供します。
(2) カスタマイズ
AutoChain は、各開発者が直面するアプリケーションのシナリオが固有であることを認識しています。そのため、比類のないカスタマイズ機能をユーザーに提供し、プラグイン可能なツール、データ ソース、意思決定プロセス モジュールを通じて特定のニーズを満たすインテリジェント エージェントを構築できるようになります。このコンセプトは、AutoChain が「差別化を受け入れる」というオープンな姿勢を示しています。
(3) 自動化
AutoChain は対話システムのフレームワークとして、シナリオのシミュレーションと自動評価の重要性を理解しています。開発者は、組み込みの対話シミュレーション エンジンを通じて、さまざまな人間とコンピューターの対話シナリオにおけるさまざまなバージョンのエージェントのパフォーマンスを効率的かつ自動的に評価し、継続的に最適化と反復を行うことができます。このイノベーション能力により、開発効率が大幅に向上することは間違いありません。
これらの「3 つのシンプルな」特徴に基づいて、AutoChain の独特の魅力を発見するのは難しくありません:
- LLM アプリケーション開発を始めたばかりの初心者にとって、AutoChain のスムーズな学習曲線は最もフレンドリーなスタートとなるでしょう。可能な限り短い時間で簡単な会話エージェントの作成を開始できるようになります。
- 経験豊富な LangChain ユーザーにとって、AutoChain の多くの概念は似ていますが、より合理化されているため、理解しやすく移行しやすく、カスタマイズされた対話システムを迅速に構築して実験するのに役立ちます。
- 会話型 AI の研究者や先駆者にとって、AutoChain は、無限にカスタマイズおよび拡張して独自の革新的なパラダイムを構築できるクリーンなテスト場を提供します。
参考:
- [1] https://flowiseai.com/
- [2] https://autochain.forethought.ai/examples/
- [3] https://www.llamaindex.ai /
以上がこの記事を読んで、いくつかの一般的な LangChain の代替手段を理解してくださいの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1664
1664
 14
1422
52
1316
25
1268
29
1240
24
14
1422
52
1316
25
1268
29
1240
24

 Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
このサイトは6月27日、JianyingはByteDanceの子会社であるFaceMeng Technologyによって開発されたビデオ編集ソフトウェアであり、Douyinプラットフォームに依存しており、基本的にプラットフォームのユーザー向けに短いビデオコンテンツを作成すると報告しました。 Windows、MacOS、その他のオペレーティング システム。 Jianyingは会員システムのアップグレードを正式に発表し、インテリジェント翻訳、インテリジェントハイライト、インテリジェントパッケージング、デジタルヒューマン合成などのさまざまなAIブラックテクノロジーを含む新しいSVIPを開始しました。価格的には、クリッピングSVIPの月額料金は79元、年会費は599元(当サイト注:月額49.9元に相当)、継続月額サブスクリプションは月額59元、継続年間サブスクリプションは、年間499元(月額41.6元に相当)です。さらに、カット担当者は、ユーザーエクスペリエンスを向上させるために、オリジナルのVIPに登録している人は、
 Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
検索強化生成およびセマンティック メモリを AI コーディング アシスタントに組み込むことで、開発者の生産性、効率、精度を向上させます。 JanakiramMSV 著者の EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG から翻訳。基本的な AI プログラミング アシスタントは当然役に立ちますが、ソフトウェア言語とソフトウェア作成の最も一般的なパターンに関する一般的な理解に依存しているため、最も適切で正しいコードの提案を提供できないことがよくあります。これらのコーディング アシスタントによって生成されたコードは、彼らが解決する責任を負っている問題の解決には適していますが、多くの場合、個々のチームのコーディング標準、規約、スタイルには準拠していません。これにより、コードがアプリケーションに受け入れられるように修正または調整する必要がある提案が得られることがよくあります。
 GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
AIGC について詳しくは、51CTOAI.x コミュニティ https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou を参照してください。これらの質問は、インターネット上のどこでも見られる従来の質問バンクとは異なります。既成概念にとらわれずに考える必要があります。大規模言語モデル (LLM) は、データ サイエンス、生成人工知能 (GenAI)、および人工知能の分野でますます重要になっています。これらの複雑なアルゴリズムは人間のスキルを向上させ、多くの業界で効率とイノベーションを推進し、企業が競争力を維持するための鍵となります。 LLM は、自然言語処理、テキスト生成、音声認識、推奨システムなどの分野で幅広い用途に使用できます。 LLM は大量のデータから学習することでテキストを生成できます。
 微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
大規模言語モデル (LLM) は巨大なテキスト データベースでトレーニングされ、そこで大量の現実世界の知識を取得します。この知識はパラメータに組み込まれており、必要なときに使用できます。これらのモデルの知識は、トレーニングの終了時に「具体化」されます。事前トレーニングの終了時に、モデルは実際に学習を停止します。モデルを調整または微調整して、この知識を活用し、ユーザーの質問により自然に応答する方法を学びます。ただし、モデルの知識だけでは不十分な場合があり、モデルは RAG を通じて外部コンテンツにアクセスできますが、微調整を通じてモデルを新しいドメインに適応させることが有益であると考えられます。この微調整は、ヒューマン アノテーターまたは他の LLM 作成物からの入力を使用して実行され、モデルは追加の実世界の知識に遭遇し、それを統合します。
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 SKハイニックスは8月6日に12層HBM3E、321層NANDなどのAI関連新製品を展示する。
Aug 01, 2024 pm 09:40 PM
SKハイニックスは8月6日に12層HBM3E、321層NANDなどのAI関連新製品を展示する。
Aug 01, 2024 pm 09:40 PM
8月1日の本サイトのニュースによると、SKハイニックスは本日(8月1日)ブログ投稿を発表し、8月6日から8日まで米国カリフォルニア州サンタクララで開催されるグローバル半導体メモリサミットFMS2024に参加すると発表し、多くの新世代の製品。フューチャー メモリおよびストレージ サミット (FutureMemoryandStorage) の紹介。以前は主に NAND サプライヤー向けのフラッシュ メモリ サミット (FlashMemorySummit) でしたが、人工知能技術への注目の高まりを背景に、今年はフューチャー メモリおよびストレージ サミット (FutureMemoryandStorage) に名前が変更されました。 DRAM およびストレージ ベンダー、さらに多くのプレーヤーを招待します。昨年発売された新製品SKハイニックス
 SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
編集者 | KX 医薬品の研究開発の分野では、タンパク質とリガンドの結合親和性を正確かつ効果的に予測することが、医薬品のスクリーニングと最適化にとって重要です。しかし、現在の研究では、タンパク質とリガンドの相互作用における分子表面情報の重要な役割が考慮されていません。これに基づいて、アモイ大学の研究者らは、初めてタンパク質の表面、3D 構造、配列に関する情報を組み合わせ、クロスアテンション メカニズムを使用して異なるモダリティの特徴を比較する、新しいマルチモーダル特徴抽出 (MFE) フレームワークを提案しました。アライメント。実験結果は、この方法がタンパク質-リガンド結合親和性の予測において最先端の性能を達成することを実証しています。さらに、アブレーション研究は、この枠組み内でのタンパク質表面情報と多峰性特徴の位置合わせの有効性と必要性を実証しています。 「S」で始まる関連研究
