

NVIDIA の新しい調査: コンテキストの長さは重大な誤りであり、多くの 32K パフォーマンスが認定されていない
Jun 05, 2024 pm 04:22 PM「長いコンテキスト」大規模モデルの誤った標準現象を容赦なく暴露 -
NVIDIA の新しい調査では、GPT-4 を含む 10 の大規模モデルが 128k、さらには 1M のコンテキスト長を生成することが判明しました。
しかし、いくつかのテストの後、新しい指標「有効なコンテキスト」は大幅に縮小しており、32Kに到達できる人はほとんどいません。
新しいベンチマークはRULERと呼ばれ、検索、マルチホップ追跡、集約、質問と回答4つのカテゴリの合計13のタスクが含まれます。 RULER は「有効コンテキスト長」を定義します。これは、モデルが 4K 長さの Llama-7B ベースラインと同じパフォーマンスを維持できる最大長です。

この研究は学者によって「非常に洞察力に富む」と評価されました。

この新しい研究を見た後、多くのネチズンも文脈長キングプレイヤーのクロードとジェミニの挑戦の結果を見たいと考えました。 (本稿では取り上げていません)


NVIDIA が「有効なコンテキスト」指標をどのように定義しているかを見てみましょう。

テストタスクはますます困難になっています
大規模モデルの長文理解能力を評価するには、まず、ZeroSCROLLS、L-Eval、LongBench、InfiniteBench などの適切な標準を選択する必要があります。サークル内で人気のあるモデル、または単に評価するモデルの検索能力は、事前知識の干渉によって制限されます。
そのため、NVIDIA によって廃止された RULER メソッドは、「トレーニング データから情報を呼び出す能力ではなく、長いコンテキストを処理して理解するモデルの能力に評価が焦点を当てていることを確認する」 と一言で要約できます。
RULER の評価データは、「パラメーター化された知識」への依存を軽減します。これは、トレーニング プロセス中に大規模なモデルが独自のパラメーターにエンコードした知識です。
具体的には、RULER ベンチマークは、タスクの 4 つの新しいカテゴリを追加することで、人気のある「干し草の山の中の針」テストを拡張します。
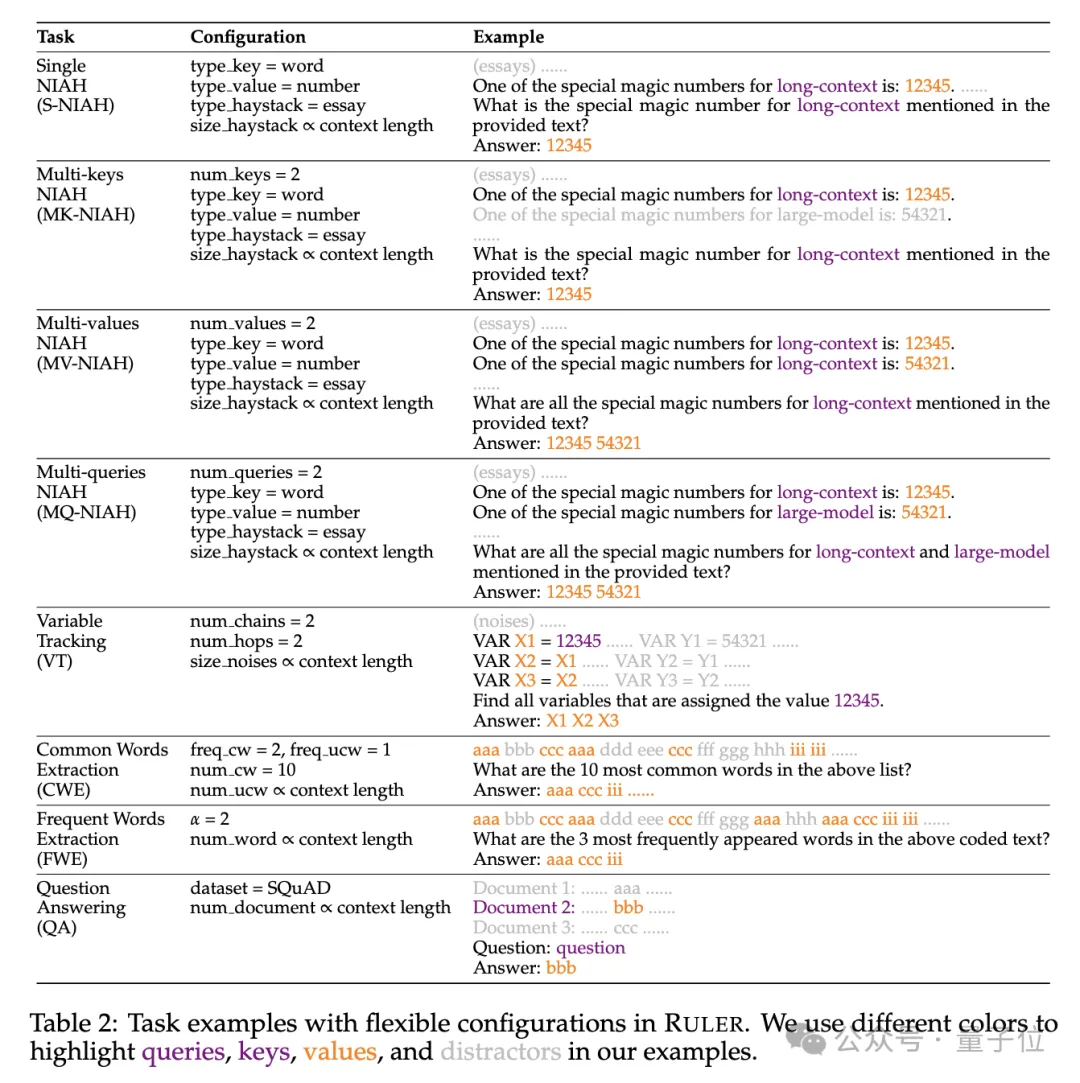
検索に関しては、干し草の山から針を見つけるという標準的な単一キー検索タスクから始まり、次の新しいタイプが追加されました:
- マルチキー検索 (マルチ-キー NIAH、MK-NIAH): 複数の干渉ピンがコンテキストに挿入され、モデルは指定された干渉ピンを取得する必要があります
- 複数値の取得 (複数値 NIAH、MV-NIAH) ): 1 つのキー(キー) は複数の値 (値) に対応するため、モデルは特定のキーに関連付けられたすべての値を取得する必要があります。
- マルチクエリ取得 (マルチクエリNIAH、MQ-NIAH): モデルは、複数のクエリに基づいてテキスト内の対応する複数のニードルを取得する必要があります。
RULER には、アップグレードされたバージョンの検索に加えて、マルチホップ トレーシング(マルチホップ トレーシング) チャレンジも追加されています。
具体的には、研究者らは変数追跡(VT)を提案しました。これは、共参照解決の最小限のタスクをシミュレートし、たとえこれらの代入がテキスト内にあるとしても、テキスト内の変数の代入チェーンを追跡することをモデルに要求します。非連続的な。 チャレンジの 3 番目のレベルは、
集約(集約) で、以下が含まれます:
- 一般的な単語の抽出
- (CWE): モデルは、テキストから最も一般的な単語を抽出する必要があります。 頻出単語抽出
- (頻出単語抽出、FWE): CWE と似ていますが、単語の頻度は語彙内のランキングとゼータ分布パラメーター α に基づいて決定されます。
課題の 4 番目のレベルは、質疑応答タスク (QA) で、既存の読解データセット (SQuAD など) に基づいて、長いシーケンスをテストするために多数の干渉段落が挿入されます。 QA能力。
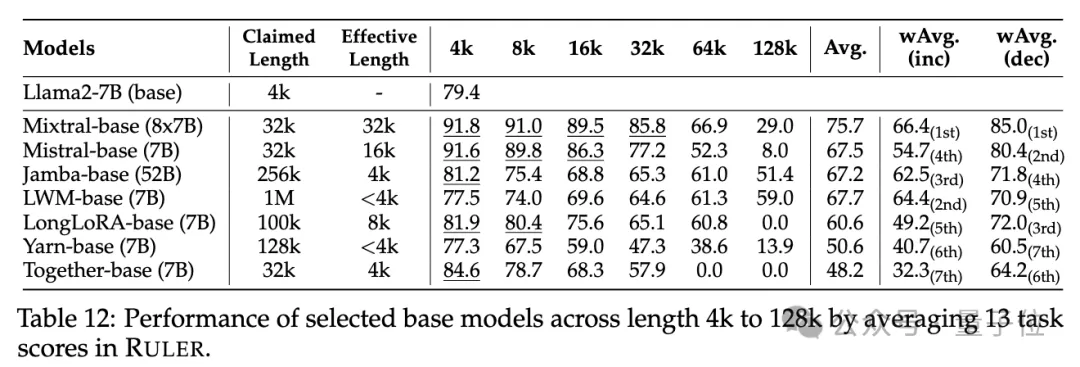
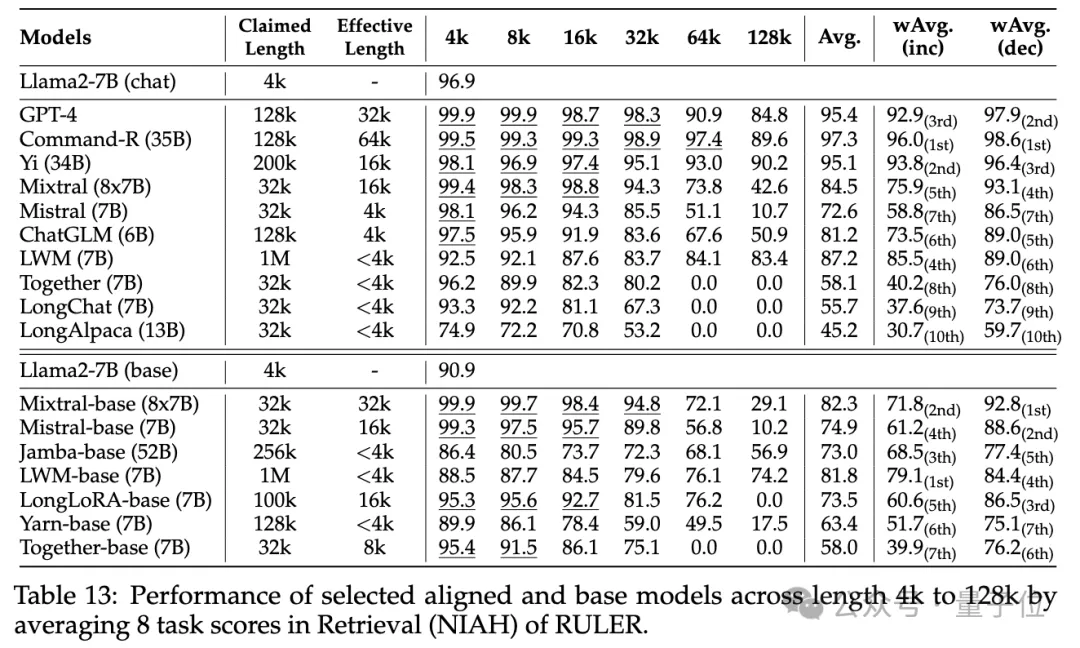
各モデルコンテキストの長さは実際どれくらいですか?実験段階では、冒頭で述べたように、研究者らは GPT-4 を含む長いコンテキストをサポートすると主張する 10 の言語モデルと、9 つのオープンソース モデル Command-R、Yi-34B、Mixtral (8x7B)、Mixtral ( 7B)、ChatGLM、LWM、Togetter、LongChat、LongAlpaca。
これらのモデルパラメータのサイズは、MoE アーキテクチャでは
6B から 8x7Bの範囲であり、最大コンテキスト長は 32K から 1M の範囲です。 RULER ベンチマーク テストでは、単純な難易度から複雑な難易度までの 4 つのタスク カテゴリをカバーする 13 の異なるタスクで各モデルが評価されました。タスクごとに、6 レベル (4K、8K、16K、32K、64K、128K) で 4K ~ 128K の範囲の入力長を持つ 500 個のテスト サンプルが生成されます。
モデルが質問への回答を拒否するのを防ぐために、入力には回答プレフィックスが追加され、再現率ベースの精度に基づいてターゲット出力の存在がチェックされます。

 より詳細なモデル比較のために、加重平均スコア
より詳細なモデル比較のために、加重平均スコア
は、さまざまな長さでパフォーマンスの加重平均を実行するための包括的な指標として使用されます。 2 つの重み付けスキームが採用されています:
wAvg(inc): 重みは長さに応じて直線的に増加し、長いシーケンスが大半を占めるアプリケーション シナリオをシミュレートします。
wAvg(dec): 重みは長さに応じて直線的に減少し、主に短いシーケンス シーンをシミュレートします。- 結果を確認してください。
- 通常の干し草の山に針を入れるテストとパスワード検索テストでは違いは見られず、ほぼすべてのモデルが、主張されているコンテキスト長の範囲内で完璧なスコアを達成しました。
その他の結果は次のとおりです。全体的に、GPT-4 は 4K 長で最高のパフォーマンスを発揮し、コンテキストが 128K に拡張された場合でもパフォーマンスの低下は最小限に抑えられています
(15.4%)。 

さらに、研究者は、入力長の増加 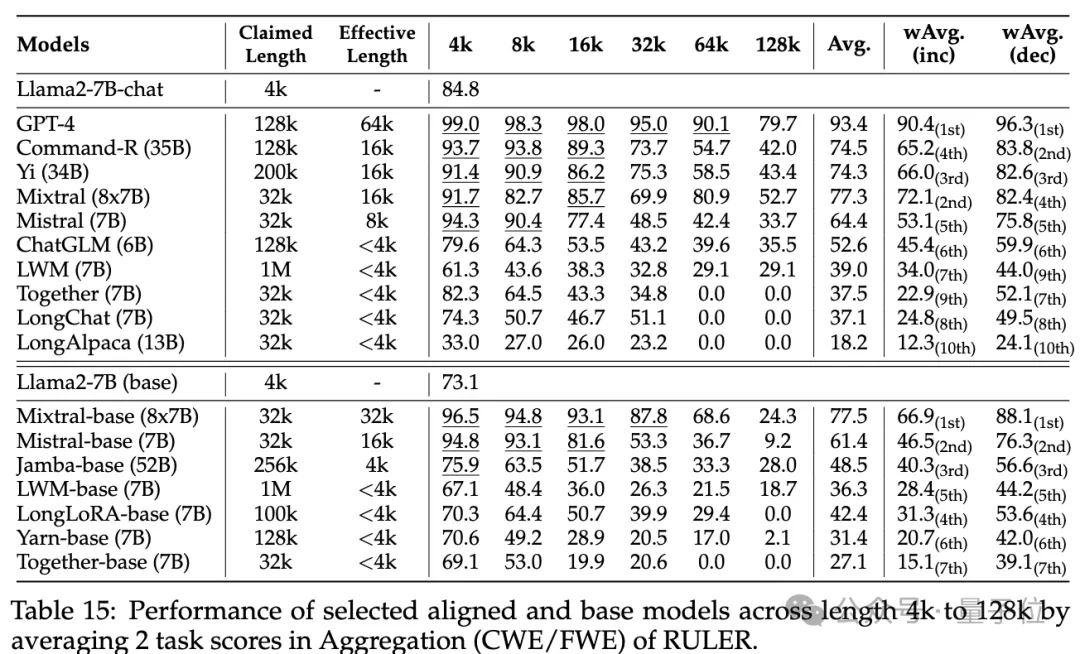 (最大 256K)
(最大 256K)
および理解するためのより複雑なタスクに対する Yi-34B-200K モデルのパフォーマンスの詳細な分析を実施しました。タスク RULER における構成と障害モードの影響。 
コンテキストでのトレーニングは一般にパフォーマンスの向上につながりますが、モデル サイズが増加すると、長いシーケンスのランキングに一貫性がなくなる可能性があることがわかりました。長いコンテキストのモデリングについては、Transformer 以外のアーキテクチャ (RWKV や Mamba など)
は、RULER 上の Transformer ベースの Llama2-7B よりも大幅に遅れています。詳細については、興味のある読者は元の論文を確認してください。 紙のリンク: https://arxiv.org/abs/2404.06654
以上がNVIDIA の新しい調査: コンテキストの長さは重大な誤りであり、多くの 32K パフォーマンスが認定されていないの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

人気の記事


人気の記事

ホットな記事タグ

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7297
7297
 9
1622
14
1342
46
1259
25
1206
29
9
1622
14
1342
46
1259
25
1206
29

 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
 NVIDIA 対話モデル ChatQA はバージョン 2.0 に進化し、コンテキストの長さは 128K と記載されています
Jul 26, 2024 am 08:40 AM
NVIDIA 対話モデル ChatQA はバージョン 2.0 に進化し、コンテキストの長さは 128K と記載されています
Jul 26, 2024 am 08:40 AM
NVIDIA 対話モデル ChatQA はバージョン 2.0 に進化し、コンテキストの長さは 128K と記載されています

 「AI Factory」はソフトウェア スタック全体の再構築を促進し、NVIDIA はユーザーが展開できる Llama3 NIM コンテナを提供します
Jun 08, 2024 pm 07:25 PM
「AI Factory」はソフトウェア スタック全体の再構築を促進し、NVIDIA はユーザーが展開できる Llama3 NIM コンテナを提供します
Jun 08, 2024 pm 07:25 PM
「AI Factory」はソフトウェア スタック全体の再構築を促進し、NVIDIA はユーザーが展開できる Llama3 NIM コンテナを提供します
 Yolov10: 詳細な説明、展開、アプリケーションがすべて 1 か所にまとめられています。
Jun 07, 2024 pm 12:05 PM
Yolov10: 詳細な説明、展開、アプリケーションがすべて 1 か所にまとめられています。
Jun 07, 2024 pm 12:05 PM
Yolov10: 詳細な説明、展開、アプリケーションがすべて 1 か所にまとめられています。
 Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
 OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
