AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。送信メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
人間のダンスビデオ生成は、入力された参照画像とターゲットポーズシーケンスに基づいてビデオを生成することを目的とした、魅力的でやりがいのある制御可能なビデオ合成タスクです。高品質でリアルな連続ビデオ。ビデオ生成技術の急速な発展、特に生成モデルの反復進化により、ダンスビデオ生成タスクは前例のない進歩を遂げ、幅広い応用可能性を実証しました。 既存の手法は大きく2つに分けられます。最初のグループは通常、敵対的生成ネットワーク (GAN) に基づいており、中間のポーズガイド表現を利用して参照の外観をワープし、以前にワープされたターゲットから適切なビデオ フレームを生成します。ただし、敵対的生成ネットワークに基づく手法では、トレーニングが不安定で汎化機能が不十分であることが多く、その結果、明らかなアーティファクトやフレーム間ジッターが発生します。 2 番目のグループは、拡散モデルを使用してリアルなビデオを合成します。これらのメソッドには、安定したトレーニングと強力な転送機能という利点があり、GAN ベースのメソッドよりも優れたパフォーマンスを発揮します。Disco、MagicAnimate、AnimateEveryone、Champ などがあります。 拡散モデルに基づく方法は大幅に進歩しましたが、既存の方法にはまだ 2 つの制限があります: まず、参照画像の特徴をエンコードし、3D-UNet と組み合わせるには、追加の参照ネットワーク (ReferenceNet) が必要です。バックボーン ブランチの増加により、トレーニングの難易度が高まり、モデル パラメーターが増加します。第 2 に、通常、ビデオ フレーム間の時間依存性をモデル化するために時間トランスフォーマーが使用されますが、トランスフォーマーの複雑さは、生成される時間の長さに応じて二次関数的に増加します。生成されたビデオのタイミングの長さ。一般的な方法では 24 フレームのビデオしか生成できないため、実際の展開の可能性は限られています。時間的オーバーラップのスライディング ウィンドウ戦略は長いビデオを生成できますが、チームの著者らは、この方法では、セグメントのオーバーラップ接合部での滑らかでない移行や外観の不一致の問題が発生しやすいことを発見しました。 これらの問題を解決するために、華中科技大学、アリババ、中国科学技術大学の研究チームは、効率的かつ長期的なヒューマンビデオ生成を実現するUniAnimateフレームワークを提案しました。 
- 論文アドレス: https://arxiv.org/abs/2406.01188
- プロジェクトホームページ: https://unianimate.github.io/
UniAnimate フレームワークは、まず参照画像、ポーズ ガイダンス、およびノイズ ビデオを特徴空間にマッピングし、次に、統合ビデオ拡散モデル (統合ビデオ拡散モデル) を使用して、参照画像とビデオ バックボーン ブランチの見かけの位置合わせを同時に処理します。およびビデオのノイズ除去タスクにより、効率的な機能調整と一貫したビデオ生成を実現します。 次に、研究チームは、最初のフレームに基づいてランダム ノイズ入力と条件付きノイズ入力をサポートする統合ノイズ入力も提案しました。ランダム ノイズ入力は、参照画像とポーズ シーケンスを使用してビデオを生成できます。最初のフレームの条件付きノイズ入力 (最初のフレーム コンディショニング) は、ビデオの最初のフレームを条件付き入力として使用して、後続のビデオを生成し続けます。このようにして、前のビデオ セグメントの最後のフレームを次のセグメントの最初のフレームとして扱うなどして推論を生成し、1 つのフレームワークで長いビデオの生成を実現できます。 最後に、長いシーケンスをさらに効率的に処理するために、研究チームは、元の計算集約型の時系列 Transformer の代替として、状態空間モデル (Mamba) に基づく時間モデリング アーキテクチャを検討しました。実験の結果、シーケンシャル Mamba に基づくアーキテクチャはシーケンシャル Transformer と同様の効果を達成できるが、必要なグラフィックス メモリのオーバーヘッドが少ないことがわかりました。
UniAnimate フレームワークを使用すると、ユーザーは高品質の時系列の人間のダンス ビデオを生成できます。 最初のフレーム コンディショニング戦略を複数回使用することで、1 分間の高解像度ビデオを生成できることは注目に値します。従来の方法と比較して、UniAnimate には次の利点があります:
- 追加の参照ネットワークは必要ありません: UniAnimate フレームワークは、統合されたビデオ拡散モデルを通じて追加の参照ネットワークへの依存を排除し、トレーニングの困難さとモデルの数を軽減します。パラメータの。
- 追加の参照条件として参照画像のポーズ マップを導入します。これにより、ネットワークが参照ポーズとターゲット ポーズの間の対応を学習し、良好な見かけの位置合わせが実現されます。
- 統合されたフレームワーク内で長いシーケンスビデオを生成する: 統合されたノイズ入力を追加することで、UniAnimate はフレーム内で長時間のビデオを生成できるようになり、従来の方法の時間制約を受けなくなりました。
- 高い一貫性: UniAnimate フレームワークは、最初のフレームを後続のフレームを生成する条件として繰り返し使用することで、生成されたビデオのスムーズなトランジション効果を保証し、ビデオの外観をより一貫性と一貫性のあるものにします。この戦略では、ユーザーが複数のビデオ クリップを生成し、良好な結果が得られたクリップの最後のフレームを次に生成されるクリップの最初のフレームとして選択することもできるため、ユーザーはモデルを操作し、必要に応じて生成結果を調整することが容易になります。ただし、前の時系列オーバーラップのスライディング ウィンドウ戦略を使用して長いビデオを生成する場合、拡散プロセスの各ステップで各ビデオが互いに結合されるため、セグメントの選択を実行できません。
上記の特性により、UniAnimate フレームワークは高品質で長期にわたる人間のダンス ビデオの合成に優れたパフォーマンスを発揮し、より幅広いアプリケーションに新たな可能性を提供します。
2. 実際の写真に基づいてダンスビデオを生成します。
3. 粘土風の写真に基づいてダンスビデオを生成します。
6. 他のクロスドメイン画像に基づいてダンスビデオを生成します。
7. 1分間のダンスビデオの生成。 オリジナルの MP4 ビデオとその他の HD ビデオの例については、この論文のプロジェクトのホームページ https://unianimate.github.io/ を参照してください。 1. TikTokデータセットに対する既存の手法との定量的な比較実験。
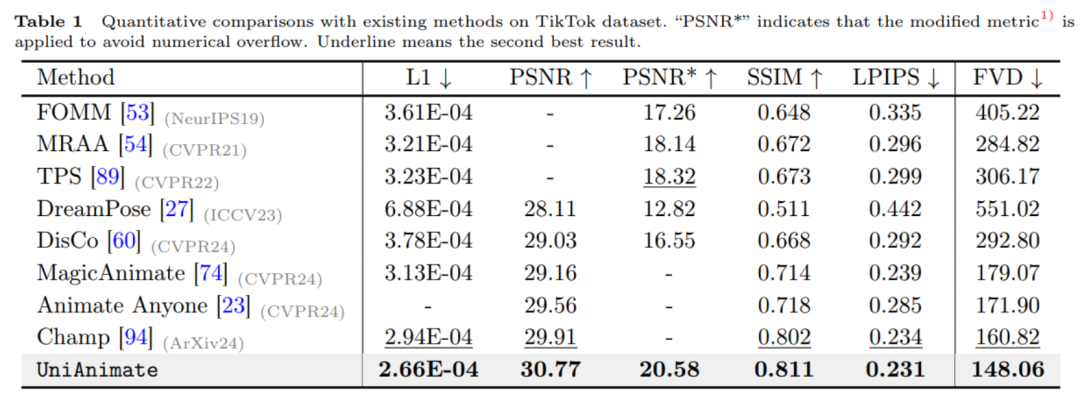
上の表に示すように、UniAnimate メソッドは、L1、PSNR、SSIM、LPIPS などの画像インジケーターおよびビデオ インジケーター FVD で最高の結果を達成しており、UniAnimate が高忠実度の結果を生成できることを示しています。
上記の定性的な比較実験からも、MagicAnimate と Animate Anybody と比較して、UniAnimate メソッドの方が明らかなアーティファクトなしでより優れた連続結果を生成できることがわかり、UniAnimate の有効性が示されています。
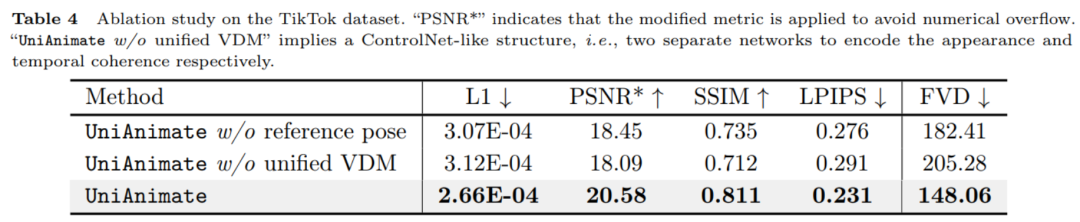
上記の表の数値結果からわかるように、UniAnimate で使用される基準ポーズと統一ビデオ拡散モデルがパフォーマンスの向上に重要な役割を果たしています。
上の図からわかるように、長いビデオを生成するために一般的に使用されるタイミング オーバーラップ スライディング ウィンドウ戦略では、簡単に不連続な遷移が発生する可能性があります。これは、異なるウィンドウではノイズ除去が一貫していないためであると研究チームは考えています。タイミングが重なる部分が発生するため、生成結果が異なり、直接平均化すると明らかな変形や歪みが生じ、この不一致がエラー伝播の原因となります。この記事で使用する最初のフレームのビデオ継続生成方法は、滑らかなトランジションを生成できます。 さらに実験的な比較結果と分析については、元の論文を参照してください。 全体として、UniAnimate のサンプル結果と定量的比較結果は非常に優れており、映画やテレビの制作、仮想現実やゲーム業界などのさまざまな分野で UniAnimate が活用され、ユーザーにさらなるメリットがもたらされることを期待しています。リアルで刺激的な人間の映像体験。 以上がHuake らは、人間が踊るビデオ生成のための新しいフレームワークである UniAnimate を提案しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

































![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



